 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Critical Training
Mar 09, 2026Training large language models (LLMs) as autonomous agents often begins with imitation learning, but it only teaches agents what to do without understanding why: agents never contrast successful actions against suboptimal alternatives and thus lack awareness of action quality. Recent approaches attempt to address this by introducing self-reflection supervision derived from contrasts between expert and alternative actions. However, the training paradigm fundamentally remains imitation learning: the model imitates pre-constructed reflection text rather than learning to reason autonomously. We propose Agentic Critical Training (ACT), a reinforcement learning paradigm that trains agents to identify the better action among alternatives. By rewarding whether the model's judgment is correct, ACT drives the model to autonomously develop reasoning about action quality, producing genuine self-reflection rather than imitating it. Across three challenging agent benchmarks, ACT consistently improves agent performance when combined with different post-training methods. It achieves an average improvement of 5.07 points over imitation learning and 4.62 points over reinforcement learning. Compared to approaches that inject reflection capability through knowledge distillation, ACT also demonstrates clear advantages, yielding an average improvement of 2.42 points. Moreover, ACT enables strong out-of-distribution generalization on agentic benchmarks and improves performance on general reasoning benchmarks without any reasoning-specific training data, highlighting the value of our method. These results suggest that ACT is a promising path toward developing more reflective and capable LLM agents.
Why Pass@k Optimization Can Degrade Pass@1: Prompt Interference in LLM Post-training
Feb 26, 2026Pass@k is a widely used performance metric for verifiable large language model tasks, including mathematical reasoning, code generation, and short-answer reasoning. It defines success if any of $k$ independently sampled solutions passes a verifier. This multi-sample inference metric has motivated inference-aware fine-tuning methods that directly optimize pass@$k$. However, prior work reports a recurring trade-off: pass@k improves while pass@1 degrades under such methods. This trade-off is practically important because pass@1 often remains a hard operational constraint due to latency and cost budgets, imperfect verifier coverage, and the need for a reliable single-shot fallback. We study the origin of this trade-off and provide a theoretical characterization of when pass@k policy optimization can reduce pass@1 through gradient conflict induced by prompt interference. We show that pass@$k$ policy gradients can conflict with pass@1 gradients because pass@$k$ optimization implicitly reweights prompts toward low-success prompts; when these prompts are what we term negatively interfering, their upweighting can rotate the pass@k update direction away from the pass@1 direction. We illustrate our theoretical findings with large language model experiments on verifiable mathematical reasoning tasks.
Safety Recovery in Reasoning Models Is Only a Few Early Steering Steps Away
Feb 11, 2026Reinforcement learning (RL) based post-training for explicit chain-of-thought (e.g., GRPO) improves the reasoning ability of multimodal large-scale reasoning models (MLRMs). But recent evidence shows that it can simultaneously degrade safety alignment and increase jailbreak success rates. We propose SafeThink, a lightweight inference-time defense that treats safety recovery as a satisficing constraint rather than a maximization objective. SafeThink monitors the evolving reasoning trace with a safety reward model and conditionally injects an optimized short corrective prefix ("Wait, think safely") only when the safety threshold is violated. In our evaluations across six open-source MLRMs and four jailbreak benchmarks (JailbreakV-28K, Hades, FigStep, and MM-SafetyBench), SafeThink reduces attack success rates by 30-60% (e.g., LlamaV-o1: 63.33% to 5.74% on JailbreakV-28K, R1-Onevision: 69.07% to 5.65% on Hades) while preserving reasoning performance (MathVista accuracy: 65.20% to 65.00%). A key empirical finding from our experiments is that safety recovery is often only a few steering steps away: intervening in the first 1-3 reasoning steps typically suffices to redirect the full generation toward safe completions.
Test-Time Scaling in Diffusion LLMs via Hidden Semi-Autoregressive Experts
Oct 06, 2025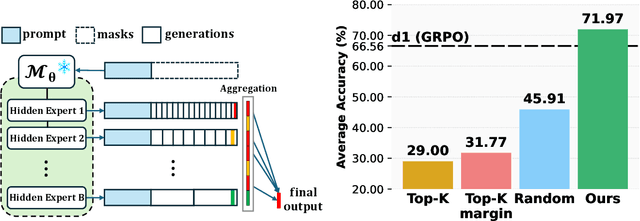
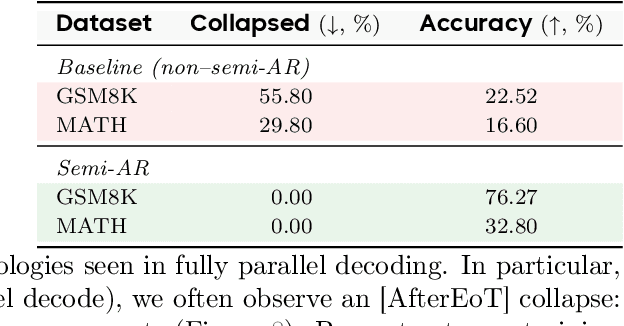
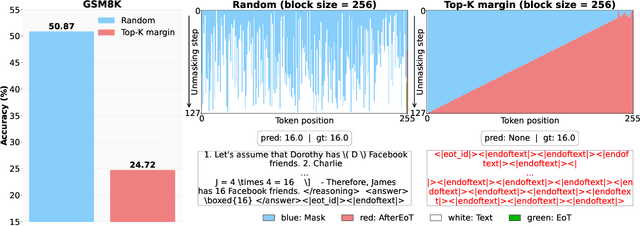
Diffusion-based large language models (dLLMs) are trained flexibly to model extreme dependence in the data distribution; however, how to best utilize this information at inference time remains an open problem. In this work, we uncover an interesting property of these models: dLLMs trained on textual data implicitly learn a mixture of semi-autoregressive experts, where different generation orders reveal different specialized behaviors. We show that committing to any single, fixed inference time schedule, a common practice, collapses performance by failing to leverage this latent ensemble. To address this, we introduce HEX (Hidden semiautoregressive EXperts for test-time scaling), a training-free inference method that ensembles across heterogeneous block schedules. By doing a majority vote over diverse block-sized generation paths, HEX robustly avoids failure modes associated with any single fixed schedule. On reasoning benchmarks such as GSM8K, it boosts accuracy by up to 3.56X (from 24.72% to 88.10%), outperforming top-K margin inference and specialized fine-tuned methods like GRPO, without additional training. HEX even yields significant gains on MATH benchmark from 16.40% to 40.00%, scientific reasoning on ARC-C from 54.18% to 87.80%, and TruthfulQA from 28.36% to 57.46%. Our results establish a new paradigm for test-time scaling in diffusion-based LLMs (dLLMs), revealing that the sequence in which masking is performed plays a critical role in determining performance during inference.
MIRA: Towards Mitigating Reward Hacking in Inference-Time Alignment of T2I Diffusion Models
Oct 02, 2025Diffusion models excel at generating images conditioned on text prompts, but the resulting images often do not satisfy user-specific criteria measured by scalar rewards such as Aesthetic Scores. This alignment typically requires fine-tuning, which is computationally demanding. Recently, inference-time alignment via noise optimization has emerged as an efficient alternative, modifying initial input noise to steer the diffusion denoising process towards generating high-reward images. However, this approach suffers from reward hacking, where the model produces images that score highly, yet deviate significantly from the original prompt. We show that noise-space regularization is insufficient and that preventing reward hacking requires an explicit image-space constraint. To this end, we propose MIRA (MItigating Reward hAcking), a training-free, inference-time alignment method. MIRA introduces an image-space, score-based KL surrogate that regularizes the sampling trajectory with a frozen backbone, constraining the output distribution so reward can increase without off-distribution drift (reward hacking). We derive a tractable approximation to KL using diffusion scores. Across SDv1.5 and SDXL, multiple rewards (Aesthetic, HPSv2, PickScore), and public datasets (e.g., Animal-Animal, HPDv2), MIRA achieves >60\% win rate vs. strong baselines while preserving prompt adherence; mechanism plots show reward gains with near-zero drift, whereas DNO drifts as compute increases. We further introduce MIRA-DPO, mapping preference optimization to inference time with a frozen backbone, extending MIRA to non-differentiable rewards without fine-tuning.
Enhancing Diversity in Large Language Models via Determinantal Point Processes
Sep 05, 2025Supervised fine-tuning and reinforcement learning are two popular methods for post-training large language models (LLMs). While improving the model's performance on downstream tasks, they often reduce the model's output diversity, leading to narrow, canonical responses. Existing methods to enhance diversity are limited, either by operating at inference time or by focusing on lexical differences. We propose a novel training method named DQO based on determinantal point processes (DPPs) to jointly optimize LLMs for quality and semantic diversity. Our approach samples and embeds a group of responses for each prompt, then uses the determinant of a kernel-based similarity matrix to measure diversity as the volume spanned by the embeddings of these responses. Experiments across instruction-following, summarization, story generation, and reasoning tasks demonstrate that our method substantially improves semantic diversity without sacrificing model quality.
Does Thinking More always Help? Understanding Test-Time Scaling in Reasoning Models
Jun 04, 2025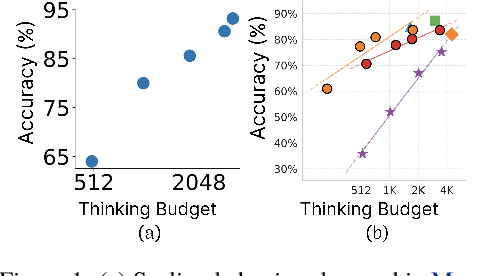
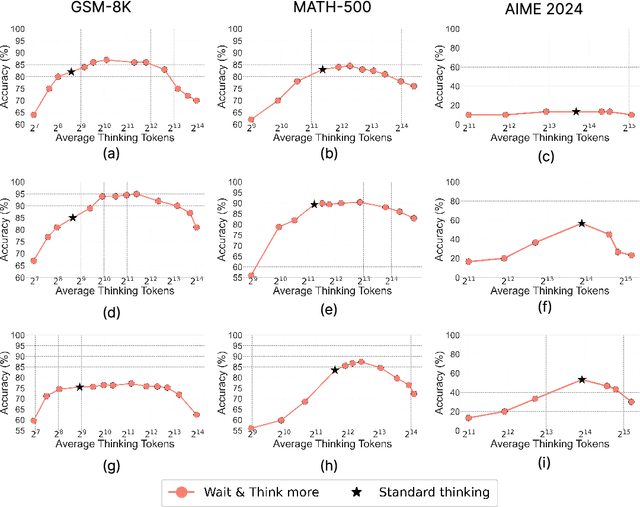
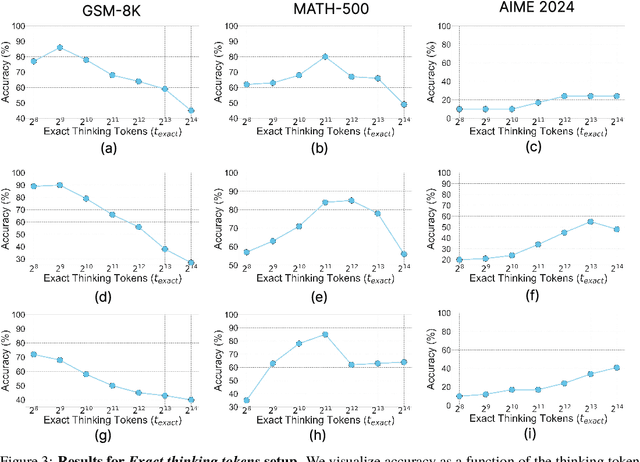
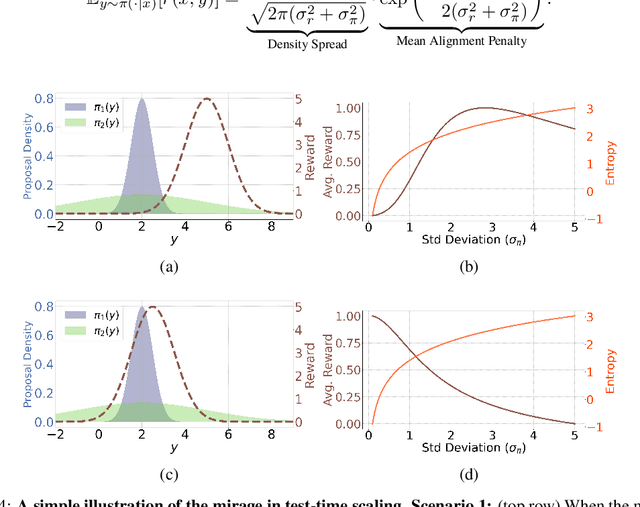
Recent trends in test-time scaling for reasoning models (e.g., OpenAI o1, DeepSeek R1) have led to a popular belief that extending thinking traces using prompts like "Wait" or "Let me rethink" can improve performance. This raises a natural question: Does thinking more at test-time truly lead to better reasoning? To answer this question, we perform a detailed empirical study across models and benchmarks, which reveals a consistent pattern of initial performance improvements from additional thinking followed by a decline, due to "overthinking". To understand this non-monotonic trend, we consider a simple probabilistic model, which reveals that additional thinking increases output variance-creating an illusion of improved reasoning while ultimately undermining precision. Thus, observed gains from "more thinking" are not true indicators of improved reasoning, but artifacts stemming from the connection between model uncertainty and evaluation metric. This suggests that test-time scaling through extended thinking is not an effective way to utilize the inference thinking budget. Recognizing these limitations, we introduce an alternative test-time scaling approach, parallel thinking, inspired by Best-of-N sampling. Our method generates multiple independent reasoning paths within the same inference budget and selects the most consistent response via majority vote, achieving up to 20% higher accuracy compared to extended thinking. This provides a simple yet effective mechanism for test-time scaling of reasoning models.
Bounded Rationality for LLMs: Satisficing Alignment at Inference-Time
May 29, 2025Aligning large language models with humans is challenging due to the inherently multifaceted nature of preference feedback. While existing approaches typically frame this as a multi-objective optimization problem, they often overlook how humans actually make decisions. Research on bounded rationality suggests that human decision making follows satisficing strategies-optimizing primary objectives while ensuring others meet acceptable thresholds. To bridge this gap and operationalize the notion of satisficing alignment, we propose SITAlign: an inference time framework that addresses the multifaceted nature of alignment by maximizing a primary objective while satisfying threshold-based constraints on secondary criteria. We provide theoretical insights by deriving sub-optimality bounds of our satisficing based inference alignment approach. We empirically validate SITAlign's performance through extensive experimentation on multiple benchmarks. For instance, on the PKU-SafeRLHF dataset with the primary objective of maximizing helpfulness while ensuring a threshold on harmlessness, SITAlign outperforms the state-of-the-art multi objective decoding strategy by a margin of 22.3% in terms of GPT-4 win-tie rate for helpfulness reward while adhering to the threshold on harmlessness.
Review, Refine, Repeat: Understanding Iterative Decoding of AI Agents with Dynamic Evaluation and Selection
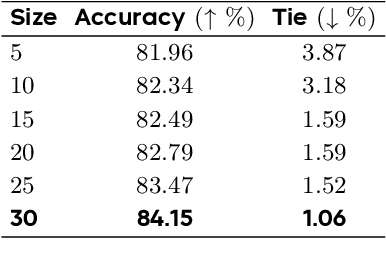
Apr 02, 2025While AI agents have shown remarkable performance at various tasks, they still struggle with complex multi-modal applications, structured generation and strategic planning. Improvements via standard fine-tuning is often impractical, as solving agentic tasks usually relies on black box API access without control over model parameters. Inference-time methods such as Best-of-N (BON) sampling offer a simple yet effective alternative to improve performance. However, BON lacks iterative feedback integration mechanism. Hence, we propose Iterative Agent Decoding (IAD) which combines iterative refinement with dynamic candidate evaluation and selection guided by a verifier. IAD differs in how feedback is designed and integrated, specifically optimized to extract maximal signal from reward scores. We conduct a detailed comparison of baselines across key metrics on Sketch2Code, Text2SQL, and Webshop where IAD consistently outperforms baselines, achieving 3--6% absolute gains on Sketch2Code and Text2SQL (with and without LLM judges) and 8--10% gains on Webshop across multiple metrics. To better understand the source of IAD's gains, we perform controlled experiments to disentangle the effect of adaptive feedback from stochastic sampling, and find that IAD's improvements are primarily driven by verifier-guided refinement, not merely sampling diversity. We also show that both IAD and BON exhibit inference-time scaling with increased compute when guided by an optimal verifier. Our analysis highlights the critical role of verifier quality in effective inference-time optimization and examines the impact of noisy and sparse rewards on scaling behavior. Together, these findings offer key insights into the trade-offs and principles of effective inference-time optimization.
Collab: Controlled Decoding using Mixture of Agents for LLM Alignment
Mar 27, 2025Alignment of Large Language models (LLMs) is crucial for safe and trustworthy deployment in applications. Reinforcement learning from human feedback (RLHF) has emerged as an effective technique to align LLMs to human preferences and broader utilities, but it requires updating billions of model parameters, which is computationally expensive. Controlled Decoding, by contrast, provides a mechanism for aligning a model at inference time without retraining. However, single-agent decoding approaches often struggle to adapt to diverse tasks due to the complexity and variability inherent in these tasks. To strengthen the test-time performance w.r.t the target task, we propose a mixture of agent-based decoding strategies leveraging the existing off-the-shelf aligned LLM policies. Treating each prior policy as an agent in the spirit of mixture of agent collaboration, we develop a decoding method that allows for inference-time alignment through a token-level selection strategy among multiple agents. For each token, the most suitable LLM is dynamically chosen from a pool of models based on a long-term utility metric. This policy-switching mechanism ensures optimal model selection at each step, enabling efficient collaboration and alignment among LLMs during decoding. Theoretical analysis of our proposed algorithm establishes optimal performance with respect to the target task represented via a target reward for the given off-the-shelf models. We conduct comprehensive empirical evaluations with open-source aligned models on diverse tasks and preferences, which demonstrates the merits of this approach over single-agent decoding baselines. Notably, Collab surpasses the current SoTA decoding strategy, achieving an improvement of up to 1.56x in average reward and 71.89% in GPT-4 based win-tie rate.