 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring System 1 and 2 communication for latent reasoning in LLMs
Oct 01, 2025Should LLM reasoning live in a separate module, or within a single model's forward pass and representational space? We study dual-architecture latent reasoning, where a fluent Base exchanges latent messages with a Coprocessor, and test two hypotheses aimed at improving latent communication over Liu et al. (2024): (H1) increase channel capacity; (H2) learn communication via joint finetuning. Under matched latent-token budgets on GPT-2 and Qwen-3, H2 is consistently strongest while H1 yields modest gains. A unified soft-embedding baseline, a single model with the same forward pass and shared representations, using the same latent-token budget, nearly matches H2 and surpasses H1, suggesting current dual designs mostly add compute rather than qualitatively improving reasoning. Across GSM8K, ProsQA, and a Countdown stress test with increasing branching factor, scaling the latent-token budget beyond small values fails to improve robustness. Latent analyses show overlapping subspaces with limited specialization, consistent with weak reasoning gains. We conclude dual-model latent reasoning remains promising in principle, but likely requires objectives and communication mechanisms that explicitly shape latent spaces for algorithmic planning.
BalancedDPO: Adaptive Multi-Metric Alignment
Mar 16, 2025



Text-to-image (T2I) diffusion models have made remarkable advancements, yet aligning them with diverse preferences remains a persistent challenge. Current methods often optimize single metrics or depend on narrowly curated datasets, leading to overfitting and limited generalization across key visual quality metrics. We present BalancedDPO, a novel extension of Direct Preference Optimization (DPO) that addresses these limitations by simultaneously aligning T2I diffusion models with multiple metrics, including human preference, CLIP score, and aesthetic quality. Our key novelty lies in aggregating consensus labels from diverse metrics in the preference distribution space as compared to existing reward mixing approaches, enabling robust and scalable multi-metric alignment while maintaining the simplicity of the standard DPO pipeline that we refer to as BalancedDPO. Our evaluations on the Pick-a-Pic, PartiPrompt and HPD datasets show that BalancedDPO achieves state-of-the-art results, outperforming existing approaches across all major metrics. BalancedDPO improves the average win rates by 15%, 7.1%, and 10.3% on Pick-a-pic, PartiPrompt and HPD, respectively, from the DiffusionDPO.
Reinforced Sequential Decision-Making for Sepsis Treatment: The POSNEGDM Framework with Mortality Classifier and Transformer
Mar 12, 2024



Sepsis, a life-threatening condition triggered by the body's exaggerated response to infection, demands urgent intervention to prevent severe complications. Existing machine learning methods for managing sepsis struggle in offline scenarios, exhibiting suboptimal performance with survival rates below 50%. This paper introduces the POSNEGDM -- ``Reinforcement Learning with Positive and Negative Demonstrations for Sequential Decision-Making" framework utilizing an innovative transformer-based model and a feedback reinforcer to replicate expert actions while considering individual patient characteristics. A mortality classifier with 96.7\% accuracy guides treatment decisions towards positive outcomes. The POSNEGDM framework significantly improves patient survival, saving 97.39% of patients, outperforming established machine learning algorithms (Decision Transformer and Behavioral Cloning) with survival rates of 33.4% and 43.5%, respectively. Additionally, ablation studies underscore the critical role of the transformer-based decision maker and the integration of a mortality classifier in enhancing overall survival rates. In summary, our proposed approach presents a promising avenue for enhancing sepsis treatment outcomes, contributing to improved patient care and reduced healthcare costs.
Understanding the Natural Language of DNA using Encoder-Decoder Foundation Models with Byte-level Precision
Nov 04, 2023



This paper presents the Ensemble Nucleotide Byte-level Encoder-Decoder (ENBED) foundation model, analyzing DNA sequences at byte-level precision with an encoder-decoder Transformer architecture. ENBED uses a sub-quadratic implementation of attention to develop an efficient model capable of sequence-to-sequence transformations, generalizing previous genomic models with encoder-only or decoder-only architectures. We use Masked Language Modeling to pre-train the foundation model using reference genome sequences and apply it in the following downstream tasks: (1) identification of enhancers, promotors and splice sites, (2) identification of biological function annotations of genomic sequences, (3) recognition of sequences containing base call mismatches and insertion/deletion errors, an advantage over tokenization schemes involving multiple base pairs, which lose the ability to analyze with byte-level precision, and (4) generating mutations of the Influenza virus using the encoder-decoder architecture and validating them against real-world observations. In each of these tasks, we demonstrate significant improvement as compared to the existing state-of-the-art results.
Domain Adaptive Few-Shot Open-Set Learning
Sep 22, 2023



Few-shot learning has made impressive strides in addressing the crucial challenges of recognizing unknown samples from novel classes in target query sets and managing visual shifts between domains. However, existing techniques fall short when it comes to identifying target outliers under domain shifts by learning to reject pseudo-outliers from the source domain, resulting in an incomplete solution to both problems. To address these challenges comprehensively, we propose a novel approach called Domain Adaptive Few-Shot Open Set Recognition (DA-FSOS) and introduce a meta-learning-based architecture named DAFOSNET. During training, our model learns a shared and discriminative embedding space while creating a pseudo open-space decision boundary, given a fully-supervised source domain and a label-disjoint few-shot target domain. To enhance data density, we use a pair of conditional adversarial networks with tunable noise variances to augment both domains closed and pseudo-open spaces. Furthermore, we propose a domain-specific batch-normalized class prototypes alignment strategy to align both domains globally while ensuring class-discriminativeness through novel metric objectives. Our training approach ensures that DAFOS-NET can generalize well to new scenarios in the target domain. We present three benchmarks for DA-FSOS based on the Office-Home, mini-ImageNet/CUB, and DomainNet datasets and demonstrate the efficacy of DAFOS-NET through extensive experimentation
Multi-task Hierarchical Adversarial Inverse Reinforcement Learning
May 22, 2023



Multi-task Imitation Learning (MIL) aims to train a policy capable of performing a distribution of tasks based on multi-task expert demonstrations, which is essential for general-purpose robots. Existing MIL algorithms suffer from low data efficiency and poor performance on complex long-horizontal tasks. We develop Multi-task Hierarchical Adversarial Inverse Reinforcement Learning (MH-AIRL) to learn hierarchically-structured multi-task policies, which is more beneficial for compositional tasks with long horizons and has higher expert data efficiency through identifying and transferring reusable basic skills across tasks. To realize this, MH-AIRL effectively synthesizes context-based multi-task learning, AIRL (an IL approach), and hierarchical policy learning. Further, MH-AIRL can be adopted to demonstrations without the task or skill annotations (i.e., state-action pairs only) which are more accessible in practice. Theoretical justifications are provided for each module of MH-AIRL, and evaluations on challenging multi-task settings demonstrate superior performance and transferability of the multi-task policies learned with MH-AIRL as compared to SOTA MIL baselines.
RSINet: Inpainting Remotely Sensed Images Using Triple GAN Framework
Feb 12, 2022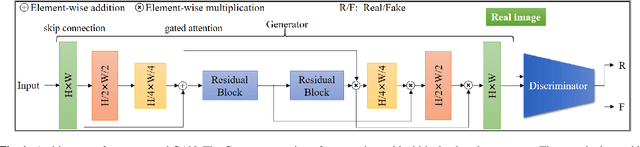
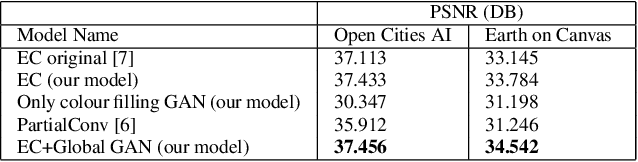
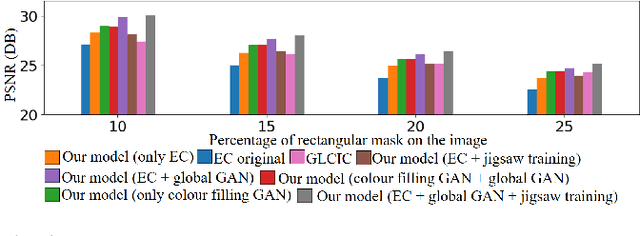

We tackle the problem of image inpainting in the remote sensing domain. Remote sensing images possess high resolution and geographical variations, that render the conventional inpainting methods less effective. This further entails the requirement of models with high complexity to sufficiently capture the spectral, spatial and textural nuances within an image, emerging from its high spatial variability. To this end, we propose a novel inpainting method that individually focuses on each aspect of an image such as edges, colour and texture using a task specific GAN. Moreover, each individual GAN also incorporates the attention mechanism that explicitly extracts the spectral and spatial features. To ensure consistent gradient flow, the model uses residual learning paradigm, thus simultaneously working with high and low level features. We evaluate our model, alongwith previous state of the art models, on the two well known remote sensing datasets, Open Cities AI and Earth on Canvas, and achieve competitive performance.
Explaining decision of model from its prediction
Jun 15, 2021

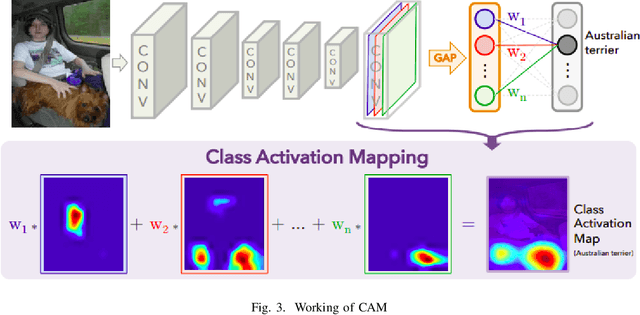
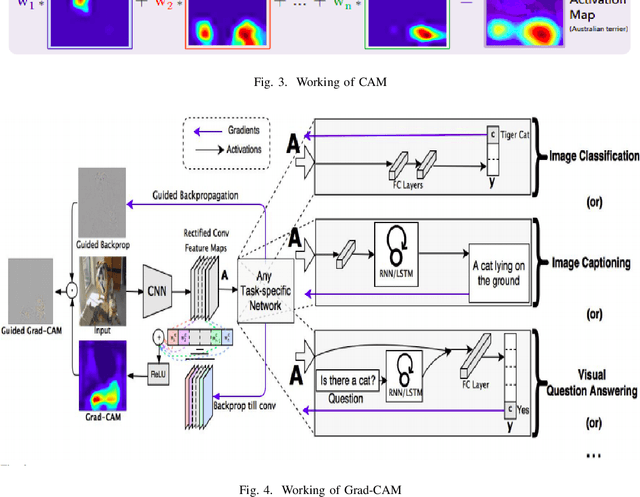
This document summarizes different visual explanations methods such as CAM, Grad-CAM, Localization using Multiple Instance Learning - Saliency-based methods, Saliency-driven Class-Impressions, Muting pixels in input image - Adversarial methods and Activation visualization, Convolution filter visualization - Feature-based methods. We have also shown the results produced by different methods and a comparison between CAM, GradCAM, and Guided Backpropagation.
Saliency-driven Class Impressions for Feature Visualization of Deep Neural Networks
Jul 31, 2020



In this paper, we propose a data-free method of extracting Impressions of each class from the classifier's memory. The Deep Learning regime empowers classifiers to extract distinct patterns (or features) of a given class from training data, which is the basis on which they generalize to unseen data. Before deploying these models on critical applications, it is advantageous to visualize the features considered to be essential for classification. Existing visualization methods develop high confidence images consisting of both background and foreground features. This makes it hard to judge what the crucial features of a given class are. In this work, we propose a saliency-driven approach to visualize discriminative features that are considered most important for a given task. Another drawback of existing methods is that confidence of the generated visualizations is increased by creating multiple instances of the given class. We restrict the algorithm to develop a single object per image, which helps further in extracting features of high confidence and also results in better visualizations. We further demonstrate the generation of negative images as naturally fused images of two or more classes.
Image-based phenotyping of diverse Rice (Oryza Sativa L.) Genotypes
Apr 06, 2020
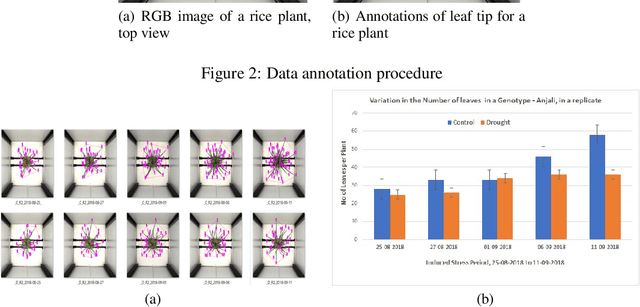
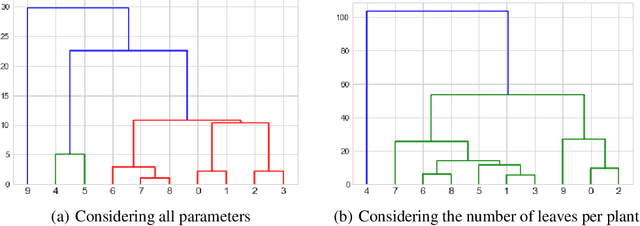
Development of either drought-resistant or drought-tolerant varieties in rice (Oryza sativa L.), especially for high yield in the context of climate change, is a crucial task across the world. The need for high yielding rice varieties is a prime concern for developing nations like India, China, and other Asian-African countries where rice is a primary staple food. The present investigation is carried out for discriminating drought tolerant, and susceptible genotypes. A total of 150 genotypes were grown under controlled conditions to evaluate at High Throughput Plant Phenomics facility, Nanaji Deshmukh Plant Phenomics Centre, Indian Council of Agricultural Research-Indian Agricultural Research Institute, New Delhi. A subset of 10 genotypes is taken out of 150 for the current investigation. To discriminate against the genotypes, we considered features such as the number of leaves per plant, the convex hull and convex hull area of a plant-convex hull formed by joining the tips of the leaves, the number of leaves per unit convex hull of a plant, canopy spread - vertical spread, and horizontal spread of a plant. We trained You Only Look Once (YOLO) deep learning algorithm for leaves tips detection and to estimate the number of leaves in a rice plant. With this proposed framework, we screened the genotypes based on selected traits. These genotypes were further grouped among different groupings of drought-tolerant and drought susceptible genotypes using the Ward method of clustering.