 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortizing Federated Adaptation: Hypernetwork Driven LoRA for Personalized Foundation Models
Jun 04, 2026Federated fine-tuning of foundation models using Low-Rank Adaptation (LoRA) offers a communication efficient solution for distributed learning. However, existing federated LoRA methods suffer from two fundamental limitations: (1) structural aggregation bias, where independently averaging low rank factors fails to approximate the true combined update, and (2) client side initialization lag, as clients repeatedly reinitialize LoRA parameters across communication rounds, slowing convergence. We propose HyperLoRA, a unified framework that addresses both issues through amortized federated adaptation through hypernetwork-driven LoRA generation and product space aggregation. Instead of iterative per-client optimization, HyperLoRA employs a learned generator that maps client distribution signatures to LoRA initializations, effectively amortizing per client adaptation. On the server side, we introduce a learned aggregation module that directly synthesizes updates in the low-rank product space, eliminating the inconsistencies of factor-wise averaging. A lightweight residual correction module further improves stability under heterogenous (non-IID) client distributions.By replacing iterative optimization and heuristic averaging with learned operators, HyperLoRA jointly enables efficient personalization, unbiased aggregation, and faster convergence. Experiments on federated vision and vision-language benchmarks show that HyperLoRA achieves improved convergence speed, greater robustness to distribution shift, and stronger personalization performance compared to prior federated LoRA methods.
Inverse Design of Realizable Metasurface based Absorbers using Improved Conditioning and Diversity Enhanced Progressively Growing GANs
Jun 04, 2026Metasurfaces enable precise manipulation of electromagnetic waves for applications such as beam steering, sensing, and stealth technology. However, inverse design of metasurfaces with targeted EM responses remains challenging due to the computational expense of iterative full wave simulation driven optimization and the limited conditioning fidelity and diversity of existing generative approaches. To address these challenges, this paper presents a generative inverse design framework for controllable and physically consistent metasurface synthesis under continuous spectral constraints. The proposed approach employs a progressively growing Wasserstein generative adversarial network with gradient penalty integrated with feature wise linear modulation based conditioning for stable propagation of continuous spectral and fabrication constraints. EM consistency is embedded directly into the generative learning process through a surrogate assisted spectral alignment loss, enabling physics constrained generation during training. Further, a determinantal point process based diversity regularization strategy is incorporated to generate geometrically diverse yet spectrally consistent realizations for the same target response. The effectiveness of the proposed framework is demonstrated through the generation of practically realizable metasurface absorbers exhibiting diverse reflection characteristics in the frequency range of 2 to 18 GHz. EM simulations validate that the generated designs meet the target specifications with high accuracy. The final proposed framework achieved an average mean squared error of 0.0052, diversity score of 0.8730, band alignment accuracy of 0.8533, and a valid EM design generation percentage of 89.57, clearly demonstrating its capability to generate highly accurate, diverse, electromagnetically consistent and fabrication realizable metasurface configurations.
Inverse Design of Metasurface based Absorbers using Physics Guided Conditional Diffusion Models
May 19, 2026Inverse design of metasurfaces for specific electromagnetic responses requires generating geometries that satisfy stringent spectral constraints while maintaining manufacturability. Conventional design methodologies rely on iterative optimization routines using full wave simulations, which become extremely time consuming and computationally intensive for large design spaces. In addition, commonly employed generative approaches often exhibit limited conditional fidelity and the generated designs often contain fine or irregular features that are impractical to fabricate. In this regard, we propose a physics guided condition quality enhanced diffusion framework for the inverse design of metasurface based absorbers. Here, the conditioning information consisting of target reflection characteristics is integrated into the model using feature wise linear modulation (FiLM). Furthermore, to enforce adherence to target spectra, a pre trained surrogate EM simulator is embedded into the framework introducing physics aware regularization through spectrum level loss functions. The efficiency of the proposed model is demonstrated by generating practically realizable metasurfaces for different types of reflection characteristics in the frequency range of 2 to 18 GHz. The proposed framework achieves an average spectral mean squared error of 0.0006 and band alignment accuracy of 0.958 between the target spectra and the spectra produced by the generated designs, demonstrating high conditional accuracy. In addition, the model generates multiple geometries for the same condition, thereby providing diverse design alternatives to the engineer. The proposed model produces the suitable design in approximately 30 seconds, whereas the conventional approach can take several months under comparable computational resources. The efficiency of the model is also established via experimental measurements.
Med-CAM: Minimal Evidence for Explaining Medical Decision Making
Apr 15, 2026Reliable and interpretable decision-making is essential in medical imaging, where diagnostic outcomes directly influence patient care. Despite advances in deep learning, most medical AI systems operate as opaque black boxes, providing little insight into why a particular diagnosis was reached. In this paper, we introduce Med-CAM, a framework for generating minimal and sharp maps as evidence-based explanations for Medical decision making via Classifier Activation Matching. Med-CAM trains a segmentation network from scratch to produce a mask that highlights the minimal evidence critical to model's decision for any seen or unseen image. This ensures that the explanation is both faithful to the network's behaviour and interpretable to clinicians. Experiments show, unlike prior spatial explanation methods, such as Grad-CAM and attention maps, which yield only fuzzy regions of relative importance, Med-CAM with its superior spatial awareness to shapes, textures, and boundaries, delivers conclusive, evidence-based explanations that faithfully replicate the model's prediction for any given image. By explicitly constraining explanations to be compact, consistent with model activations, and diagnostic alignment, Med-CAM advances transparent AI to foster clinician understanding and trust in high-stakes medical applications such as pathology and radiology.
BiPrompt: Bilateral Prompt Optimization for Visual and Textual Debiasing in Vision-Language Models
Jan 05, 2026Vision language foundation models such as CLIP exhibit impressive zero-shot generalization yet remain vulnerable to spurious correlations across visual and textual modalities. Existing debiasing approaches often address a single modality either visual or textual leading to partial robustness and unstable adaptation under distribution shifts. We propose a bilateral prompt optimization framework (BiPrompt) that simultaneously mitigates non-causal feature reliance in both modalities during test-time adaptation. On the visual side, it employs structured attention-guided erasure to suppress background activations and enforce orthogonal prediction consistency between causal and spurious regions. On the textual side, it introduces balanced prompt normalization, a learnable re-centering mechanism that aligns class embeddings toward an isotropic semantic space. Together, these modules jointly minimize conditional mutual information between spurious cues and predictions, steering the model toward causal, domain invariant reasoning without retraining or domain supervision. Extensive evaluations on real-world and synthetic bias benchmarks demonstrate consistent improvements in both average and worst-group accuracies over prior test-time debiasing methods, establishing a lightweight yet effective path toward trustworthy and causally grounded vision-language adaptation.
FedHypeVAE: Federated Learning with Hypernetwork Generated Conditional VAEs for Differentially Private Embedding Sharing
Jan 02, 2026Federated data sharing promises utility without centralizing raw data, yet existing embedding-level generators struggle under non-IID client heterogeneity and provide limited formal protection against gradient leakage. We propose FedHypeVAE, a differentially private, hypernetwork-driven framework for synthesizing embedding-level data across decentralized clients. Building on a conditional VAE backbone, we replace the single global decoder and fixed latent prior with client-aware decoders and class-conditional priors generated by a shared hypernetwork from private, trainable client codes. This bi-level design personalizes the generative layerrather than the downstream modelwhile decoupling local data from communicated parameters. The shared hypernetwork is optimized under differential privacy, ensuring that only noise-perturbed, clipped gradients are aggregated across clients. A local MMD alignment between real and synthetic embeddings and a Lipschitz regularizer on hypernetwork outputs further enhance stability and distributional coherence under non-IID conditions. After training, a neutral meta-code enables domain agnostic synthesis, while mixtures of meta-codes provide controllable multi-domain coverage. FedHypeVAE unifies personalization, privacy, and distribution alignment at the generator level, establishing a principled foundation for privacy-preserving data synthesis in federated settings. Code: github.com/sunnyinAI/FedHypeVAE
Spatially-Aware Mixture of Experts with Log-Logistic Survival Modeling for Whole-Slide Images
Nov 17, 2025Accurate survival prediction from histopathology whole-slide images (WSIs) remains challenging due to their gigapixel resolution, strong spatial heterogeneity, and complex survival distributions. We introduce a comprehensive computational pathology framework that addresses these limitations through four complementary innovations: (1) Quantile-Gated Patch Selection for dynamically identifying prognostically relevant regions, (2) Graph-Guided Clustering to group patches by spatial and morphological similarity, (3) Hierarchical Context Attention to model both local tissue interactions and global slide-level context, and (4) an Expert-Driven Mixture of Log-Logistics module that flexibly models complex survival distributions. Across large TCGA cohorts, our method achieves state-of-the-art performance, yielding time-dependent concordance indices of 0.644 on LUAD, 0.751 on KIRC, and 0.752 on BRCA, consistently outperforming both histology-only and multimodal baselines. The framework further provides improved calibration and interpretability, advancing the use of WSIs for personalized cancer prognosis.
Mix, Align, Distil: Reliable Cross-Domain Atypical Mitosis Classification
Aug 28, 2025Atypical mitotic figures (AMFs) are important histopathological markers yet remain challenging to identify consistently, particularly under domain shift stemming from scanner, stain, and acquisition differences. We present a simple training-time recipe for domain-robust AMF classification in MIDOG 2025 Task 2. The approach (i) increases feature diversity via style perturbations inserted at early and mid backbone stages, (ii) aligns attention-refined features across sites using weak domain labels (Scanner, Origin, Species, Tumor) through an auxiliary alignment loss, and (iii) stabilizes predictions by distilling from an exponential moving average (EMA) teacher with temperature-scaled KL divergence. On the organizer-run preliminary leaderboard for atypical mitosis classification, our submission attains balanced accuracy of 0.8762, sensitivity of 0.8873, specificity of 0.8651, and ROC AUC of 0.9499. The method incurs negligible inference-time overhead, relies only on coarse domain metadata, and delivers strong, balanced performance, positioning it as a competitive submission for the MIDOG 2025 challenge.
Federated Cross-Modal Style-Aware Prompt Generation
Aug 17, 2025Prompt learning has propelled vision-language models like CLIP to excel in diverse tasks, making them ideal for federated learning due to computational efficiency. However, conventional approaches that rely solely on final-layer features miss out on rich multi-scale visual cues and domain-specific style variations in decentralized client data. To bridge this gap, we introduce FedCSAP (Federated Cross-Modal Style-Aware Prompt Generation). Our framework harnesses low, mid, and high-level features from CLIP's vision encoder alongside client-specific style indicators derived from batch-level statistics. By merging intricate visual details with textual context, FedCSAP produces robust, context-aware prompt tokens that are both distinct and non-redundant, thereby boosting generalization across seen and unseen classes. Operating within a federated learning paradigm, our approach ensures data privacy through local training and global aggregation, adeptly handling non-IID class distributions and diverse domain-specific styles. Comprehensive experiments on multiple image classification datasets confirm that FedCSAP outperforms existing federated prompt learning methods in both accuracy and overall generalization.
Survival Modeling from Whole Slide Images via Patch-Level Graph Clustering and Mixture Density Experts
Jul 22, 2025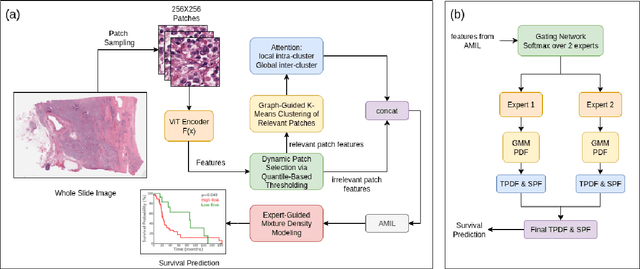
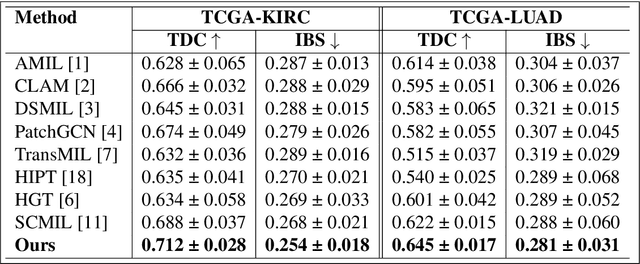
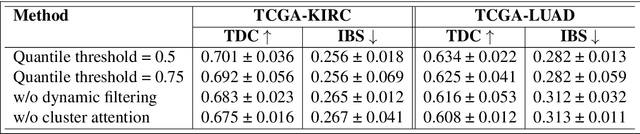
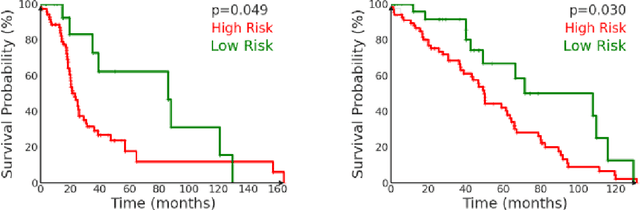
We introduce a modular framework for predicting cancer-specific survival from whole slide pathology images (WSIs) that significantly improves upon the state-of-the-art accuracy. Our method integrating four key components. Firstly, to tackle large size of WSIs, we use dynamic patch selection via quantile-based thresholding for isolating prognostically informative tissue regions. Secondly, we use graph-guided k-means clustering to capture phenotype-level heterogeneity through spatial and morphological coherence. Thirdly, we use attention mechanisms that model both intra- and inter-cluster relationships to contextualize local features within global spatial relations between various types of tissue compartments. Finally, we use an expert-guided mixture density modeling for estimating complex survival distributions using Gaussian mixture models. The proposed model achieves a concordance index of $0.712 \pm 0.028$ and Brier score of $0.254 \pm 0.018$ on TCGA-KIRC (renal cancer), and a concordance index of $0.645 \pm 0.017$ and Brier score of $0.281 \pm 0.031$ on TCGA-LUAD (lung adenocarcinoma). These results are significantly better than the state-of-art and demonstrate predictive potential of the proposed method across diverse cancer types.