 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFANVID: A Benchmark for Face and License Plate Recognition in Low-Resolution Videos
Jun 08, 2025


Real-world surveillance often renders faces and license plates unrecognizable in individual low-resolution (LR) frames, hindering reliable identification. To advance temporal recognition models, we present FANVID, a novel video-based benchmark comprising nearly 1,463 LR clips (180 x 320, 20--60 FPS) featuring 63 identities and 49 license plates from three English-speaking countries. Each video includes distractor faces and plates, increasing task difficulty and realism. The dataset contains 31,096 manually verified bounding boxes and labels. FANVID defines two tasks: (1) face matching -- detecting LR faces and matching them to high-resolution mugshots, and (2) license plate recognition -- extracting text from LR plates without a predefined database. Videos are downsampled from high-resolution sources to ensure that faces and text are indecipherable in single frames, requiring models to exploit temporal information. We introduce evaluation metrics adapted from mean Average Precision at IoU > 0.5, prioritizing identity correctness for faces and character-level accuracy for text. A baseline method with pre-trained video super-resolution, detection, and recognition achieved performance scores of 0.58 (face matching) and 0.42 (plate recognition), highlighting both the feasibility and challenge of the tasks. FANVID's selection of faces and plates balances diversity with recognition challenge. We release the software for data access, evaluation, baseline, and annotation to support reproducibility and extension. FANVID aims to catalyze innovation in temporal modeling for LR recognition, with applications in surveillance, forensics, and autonomous vehicles.
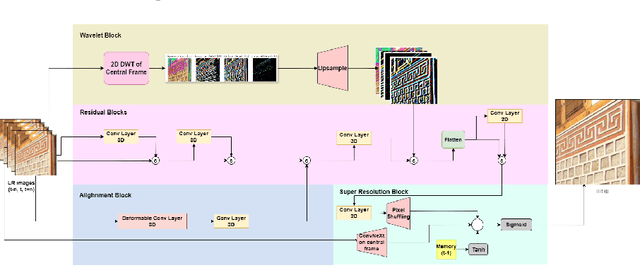
Low Resource Video Super-resolution using Memory and Residual Deformable Convolutions
Feb 03, 2025



Transformer-based video super-resolution (VSR) models have set new benchmarks in recent years, but their substantial computational demands make most of them unsuitable for deployment on resource-constrained devices. Achieving a balance between model complexity and output quality remains a formidable challenge in VSR. Although lightweight models have been introduced to address this issue, they often struggle to deliver state-of-the-art performance. We propose a novel lightweight, parameter-efficient deep residual deformable convolution network for VSR. Unlike prior methods, our model enhances feature utilization through residual connections and employs deformable convolution for precise frame alignment, addressing motion dynamics effectively. Furthermore, we introduce a single memory tensor to capture information accrued from the past frames and improve motion estimation across frames. This design enables an efficient balance between computational cost and reconstruction quality. With just 2.3 million parameters, our model achieves state-of-the-art SSIM of 0.9175 on the REDS4 dataset, surpassing existing lightweight and many heavy models in both accuracy and resource efficiency. Architectural insights from our model pave the way for real-time VSR on streaming data.
WaveMix-Lite: A Resource-efficient Neural Network for Image Analysis
Jun 01, 2022
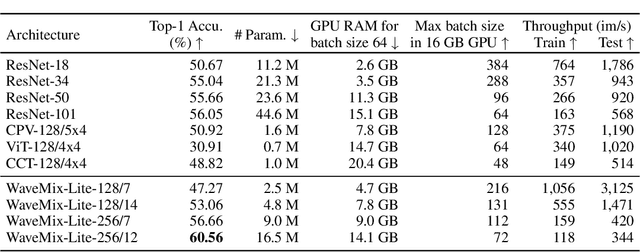

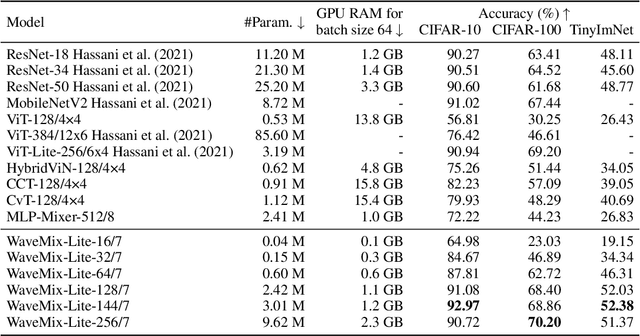
Gains in the ability to generalize on image analysis tasks for neural networks have come at the cost of increased number of parameters and layers, dataset sizes, training and test computations, and GPU RAM. We introduce a new architecture -- WaveMix-Lite -- that can generalize on par with contemporary transformers and convolutional neural networks (CNNs) while needing fewer resources. WaveMix-Lite uses 2D-discrete wavelet transform to efficiently mix spatial information from pixels. WaveMix-Lite seems to be a versatile and scalable architectural framework that can be used for multiple vision tasks, such as image classification and semantic segmentation, without requiring significant architectural changes, unlike transformers and CNNs. It is able to meet or exceed several accuracy benchmarks while training on a single GPU. For instance, it achieves state-of-the-art accuracy on five EMNIST datasets, outperforms CNNs and transformers in ImageNet-1K (64$\times$64 images), and achieves an mIoU of 75.32 % on Cityscapes validation set, while using less than one-fifth the number parameters and half the GPU RAM of comparable CNNs or transformers. Our experiments show that while the convolutional elements of neural architectures exploit the shift-invariance property of images, new types of layers (e.g., wavelet transform) can exploit additional properties of images, such as scale-invariance and finite spatial extents of objects.