 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Resource Video Super-resolution using Memory and Residual Deformable Convolutions
Feb 03, 2025



Transformer-based video super-resolution (VSR) models have set new benchmarks in recent years, but their substantial computational demands make most of them unsuitable for deployment on resource-constrained devices. Achieving a balance between model complexity and output quality remains a formidable challenge in VSR. Although lightweight models have been introduced to address this issue, they often struggle to deliver state-of-the-art performance. We propose a novel lightweight, parameter-efficient deep residual deformable convolution network for VSR. Unlike prior methods, our model enhances feature utilization through residual connections and employs deformable convolution for precise frame alignment, addressing motion dynamics effectively. Furthermore, we introduce a single memory tensor to capture information accrued from the past frames and improve motion estimation across frames. This design enables an efficient balance between computational cost and reconstruction quality. With just 2.3 million parameters, our model achieves state-of-the-art SSIM of 0.9175 on the REDS4 dataset, surpassing existing lightweight and many heavy models in both accuracy and resource efficiency. Architectural insights from our model pave the way for real-time VSR on streaming data.
Utilizing Radiomic Feature Analysis For Automated MRI Keypoint Detection: Enhancing Graph Applications
Nov 30, 2023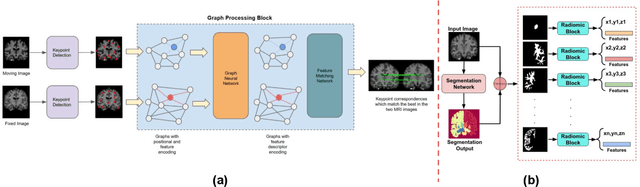

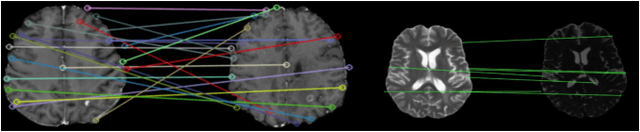
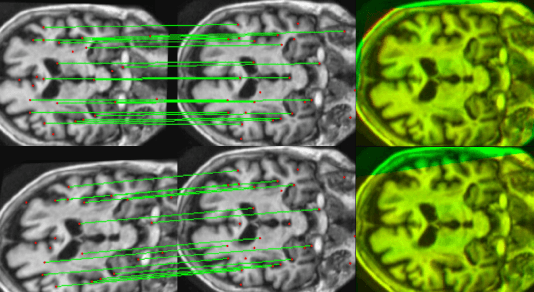
Graph neural networks (GNNs) present a promising alternative to CNNs and transformers in certain image processing applications due to their parameter-efficiency in modeling spatial relationships. Currently, a major area of research involves the converting non-graph input data for GNN-based models, notably in scenarios where the data originates from images. One approach involves converting images into nodes by identifying significant keypoints within them. Super-Retina, a semi-supervised technique, has been utilized for detecting keypoints in retinal images. However, its limitations lie in the dependency on a small initial set of ground truth keypoints, which is progressively expanded to detect more keypoints. Having encountered difficulties in detecting consistent initial keypoints in brain images using SIFT and LoFTR, we proposed a new approach: radiomic feature-based keypoint detection. Demonstrating the anatomical significance of the detected keypoints was achieved by showcasing their efficacy in improving registration processes guided by these keypoints. Subsequently, these keypoints were employed as the ground truth for the keypoint detection method (LK-SuperRetina). Furthermore, the study showcases the application of GNNs in image matching, highlighting their superior performance in terms of both the number of good matches and confidence scores. This research sets the stage for expanding GNN applications into various other applications, including but not limited to image classification, segmentation, and registration.