 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time gravitational-wave inference for binary neutron stars using machine learning
Jul 12, 2024



Mergers of binary neutron stars (BNSs) emit signals in both the gravitational-wave (GW) and electromagnetic (EM) spectra. Famously, the 2017 multi-messenger observation of GW170817 led to scientific discoveries across cosmology, nuclear physics, and gravity. Central to these results were the sky localization and distance obtained from GW data, which, in the case of GW170817, helped to identify the associated EM transient, AT 2017gfo, 11 hours after the GW signal. Fast analysis of GW data is critical for directing time-sensitive EM observations; however, due to challenges arising from the length and complexity of signals, it is often necessary to make approximations that sacrifice accuracy. Here, we develop a machine learning approach that performs complete BNS inference in just one second without making any such approximations. This is enabled by a new method for explicit integration of physical domain knowledge into neural networks. Our approach enhances multi-messenger observations by providing (i) accurate localization even before the merger; (ii) improved localization precision by $\sim30\%$ compared to approximate low-latency methods; and (iii) detailed information on luminosity distance, inclination, and masses, which can be used to prioritize expensive telescope time. Additionally, the flexibility and reduced cost of our method open new opportunities for equation-of-state and waveform systematics studies. Finally, we demonstrate that our method scales to extremely long signals, up to an hour in length, thus serving as a blueprint for data analysis for next-generation ground- and space-based detectors.
Utilizing Radiomic Feature Analysis For Automated MRI Keypoint Detection: Enhancing Graph Applications
Nov 30, 2023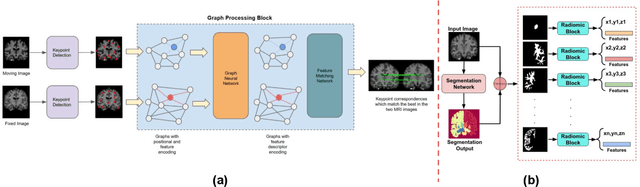

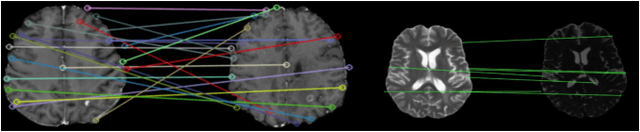
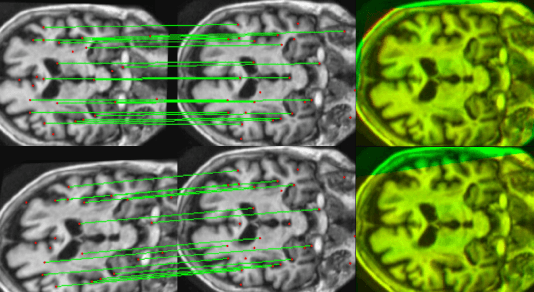
Graph neural networks (GNNs) present a promising alternative to CNNs and transformers in certain image processing applications due to their parameter-efficiency in modeling spatial relationships. Currently, a major area of research involves the converting non-graph input data for GNN-based models, notably in scenarios where the data originates from images. One approach involves converting images into nodes by identifying significant keypoints within them. Super-Retina, a semi-supervised technique, has been utilized for detecting keypoints in retinal images. However, its limitations lie in the dependency on a small initial set of ground truth keypoints, which is progressively expanded to detect more keypoints. Having encountered difficulties in detecting consistent initial keypoints in brain images using SIFT and LoFTR, we proposed a new approach: radiomic feature-based keypoint detection. Demonstrating the anatomical significance of the detected keypoints was achieved by showcasing their efficacy in improving registration processes guided by these keypoints. Subsequently, these keypoints were employed as the ground truth for the keypoint detection method (LK-SuperRetina). Furthermore, the study showcases the application of GNNs in image matching, highlighting their superior performance in terms of both the number of good matches and confidence scores. This research sets the stage for expanding GNN applications into various other applications, including but not limited to image classification, segmentation, and registration.
Reverse Knowledge Distillation: Training a Large Model using a Small One for Retinal Image Matching on Limited Data
Jul 21, 2023Retinal image matching plays a crucial role in monitoring disease progression and treatment response. However, datasets with matched keypoints between temporally separated pairs of images are not available in abundance to train transformer-based model. We propose a novel approach based on reverse knowledge distillation to train large models with limited data while preventing overfitting. Firstly, we propose architectural modifications to a CNN-based semi-supervised method called SuperRetina that help us improve its results on a publicly available dataset. Then, we train a computationally heavier model based on a vision transformer encoder using the lighter CNN-based model, which is counter-intuitive in the field knowledge-distillation research where training lighter models based on heavier ones is the norm. Surprisingly, such reverse knowledge distillation improves generalization even further. Our experiments suggest that high-dimensional fitting in representation space may prevent overfitting unlike training directly to match the final output. We also provide a public dataset with annotations for retinal image keypoint detection and matching to help the research community develop algorithms for retinal image applications.