 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEDTAIL: Federated Long-Tailed Domain Generalization with Sharpness-Guided Gradient Matching
Jun 10, 2025Domain Generalization (DG) seeks to train models that perform reliably on unseen target domains without access to target data during training. While recent progress in smoothing the loss landscape has improved generalization, existing methods often falter under long-tailed class distributions and conflicting optimization objectives. We introduce FedTAIL, a federated domain generalization framework that explicitly addresses these challenges through sharpness-guided, gradient-aligned optimization. Our method incorporates a gradient coherence regularizer to mitigate conflicts between classification and adversarial objectives, leading to more stable convergence. To combat class imbalance, we perform class-wise sharpness minimization and propose a curvature-aware dynamic weighting scheme that adaptively emphasizes underrepresented tail classes. Furthermore, we enhance conditional distribution alignment by integrating sharpness-aware perturbations into entropy regularization, improving robustness under domain shift. FedTAIL unifies optimization harmonization, class-aware regularization, and conditional alignment into a scalable, federated-compatible framework. Extensive evaluations across standard domain generalization benchmarks demonstrate that FedTAIL achieves state-of-the-art performance, particularly in the presence of domain shifts and label imbalance, validating its effectiveness in both centralized and federated settings. Code: https://github.com/sunnyinAI/FedTail
UniVarFL: Uniformity and Variance Regularized Federated Learning for Heterogeneous Data
Jun 09, 2025Federated Learning (FL) often suffers from severe performance degradation when faced with non-IID data, largely due to local classifier bias. Traditional remedies such as global model regularization or layer freezing either incur high computational costs or struggle to adapt to feature shifts. In this work, we propose UniVarFL, a novel FL framework that emulates IID-like training dynamics directly at the client level, eliminating the need for global model dependency. UniVarFL leverages two complementary regularization strategies during local training: Classifier Variance Regularization, which aligns class-wise probability distributions with those expected under IID conditions, effectively mitigating local classifier bias; and Hyperspherical Uniformity Regularization, which encourages a uniform distribution of feature representations across the hypersphere, thereby enhancing the model's ability to generalize under diverse data distributions. Extensive experiments on multiple benchmark datasets demonstrate that UniVarFL outperforms existing methods in accuracy, highlighting its potential as a highly scalable and efficient solution for real-world FL deployments, especially in resource-constrained settings. Code: https://github.com/sunnyinAI/UniVarFL
MHQA: A Diverse, Knowledge Intensive Mental Health Question Answering Challenge for Language Models
Feb 21, 2025
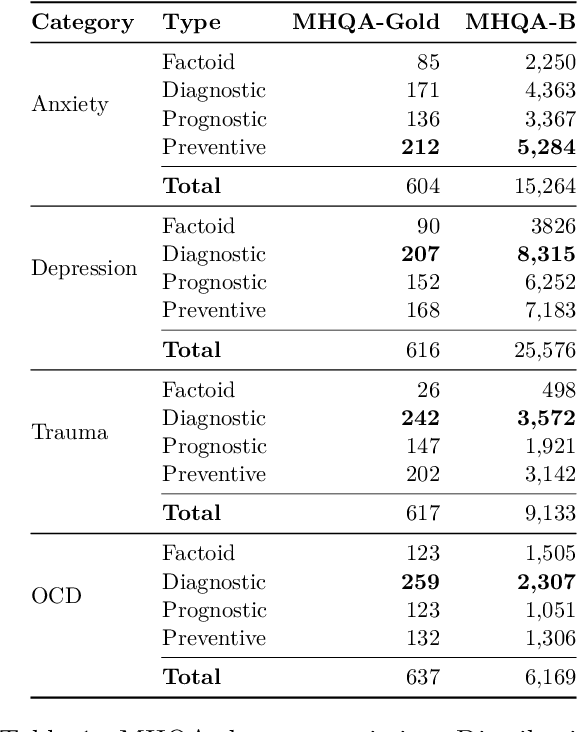
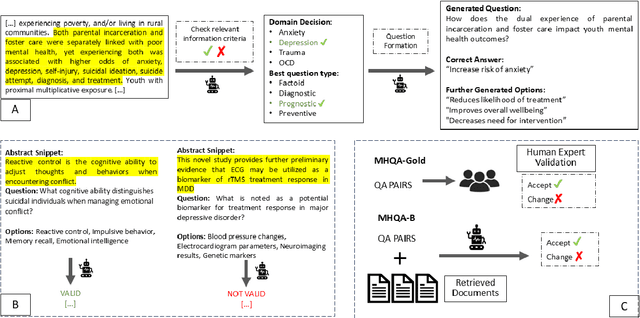
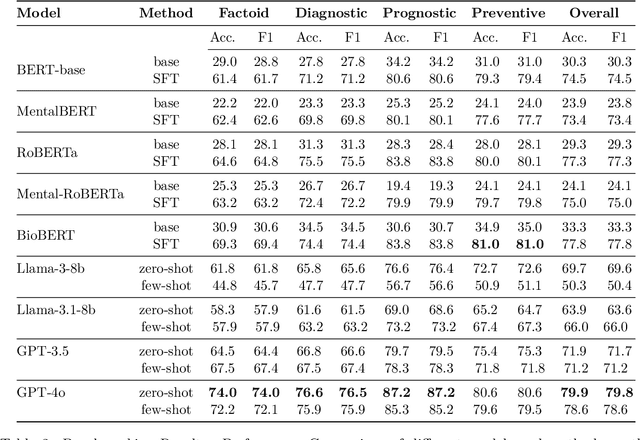
Mental health remains a challenging problem all over the world, with issues like depression, anxiety becoming increasingly common. Large Language Models (LLMs) have seen a vast application in healthcare, specifically in answering medical questions. However, there is a lack of standard benchmarking datasets for question answering (QA) in mental health. Our work presents a novel multiple choice dataset, MHQA (Mental Health Question Answering), for benchmarking Language models (LMs). Previous mental health datasets have focused primarily on text classification into specific labels or disorders. MHQA, on the other hand, presents question-answering for mental health focused on four key domains: anxiety, depression, trauma, and obsessive/compulsive issues, with diverse question types, namely, factoid, diagnostic, prognostic, and preventive. We use PubMed abstracts as the primary source for QA. We develop a rigorous pipeline for LLM-based identification of information from abstracts based on various selection criteria and converting it into QA pairs. Further, valid QA pairs are extracted based on post-hoc validation criteria. Overall, our MHQA dataset consists of 2,475 expert-verified gold standard instances called MHQA-gold and ~56.1k pairs pseudo labeled using external medical references. We report F1 scores on different LLMs along with few-shot and supervised fine-tuning experiments, further discussing the insights for the scores.
FedStein: Enhancing Multi-Domain Federated Learning Through James-Stein Estimator
Oct 04, 2024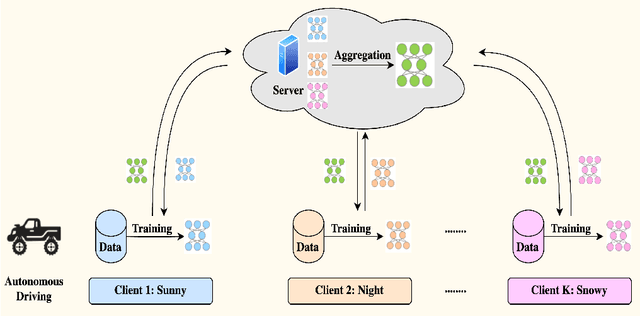

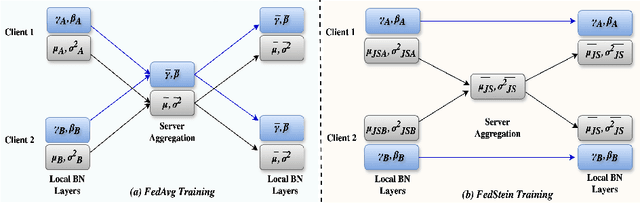

Federated Learning (FL) facilitates data privacy by enabling collaborative in-situ training across decentralized clients. Despite its inherent advantages, FL faces significant challenges of performance and convergence when dealing with data that is not independently and identically distributed (non-i.i.d.). While previous research has primarily addressed the issue of skewed label distribution across clients, this study focuses on the less explored challenge of multi-domain FL, where client data originates from distinct domains with varying feature distributions. We introduce a novel method designed to address these challenges FedStein: Enhancing Multi-Domain Federated Learning Through the James-Stein Estimator. FedStein uniquely shares only the James-Stein (JS) estimates of batch normalization (BN) statistics across clients, while maintaining local BN parameters. The non-BN layer parameters are exchanged via standard FL techniques. Extensive experiments conducted across three datasets and multiple models demonstrate that FedStein surpasses existing methods such as FedAvg and FedBN, with accuracy improvements exceeding 14% in certain domains leading to enhanced domain generalization. The code is available at https://github.com/sunnyinAI/FedStein