 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiPrompt: Bilateral Prompt Optimization for Visual and Textual Debiasing in Vision-Language Models
Jan 05, 2026Vision language foundation models such as CLIP exhibit impressive zero-shot generalization yet remain vulnerable to spurious correlations across visual and textual modalities. Existing debiasing approaches often address a single modality either visual or textual leading to partial robustness and unstable adaptation under distribution shifts. We propose a bilateral prompt optimization framework (BiPrompt) that simultaneously mitigates non-causal feature reliance in both modalities during test-time adaptation. On the visual side, it employs structured attention-guided erasure to suppress background activations and enforce orthogonal prediction consistency between causal and spurious regions. On the textual side, it introduces balanced prompt normalization, a learnable re-centering mechanism that aligns class embeddings toward an isotropic semantic space. Together, these modules jointly minimize conditional mutual information between spurious cues and predictions, steering the model toward causal, domain invariant reasoning without retraining or domain supervision. Extensive evaluations on real-world and synthetic bias benchmarks demonstrate consistent improvements in both average and worst-group accuracies over prior test-time debiasing methods, establishing a lightweight yet effective path toward trustworthy and causally grounded vision-language adaptation.
FedHypeVAE: Federated Learning with Hypernetwork Generated Conditional VAEs for Differentially Private Embedding Sharing
Jan 02, 2026Federated data sharing promises utility without centralizing raw data, yet existing embedding-level generators struggle under non-IID client heterogeneity and provide limited formal protection against gradient leakage. We propose FedHypeVAE, a differentially private, hypernetwork-driven framework for synthesizing embedding-level data across decentralized clients. Building on a conditional VAE backbone, we replace the single global decoder and fixed latent prior with client-aware decoders and class-conditional priors generated by a shared hypernetwork from private, trainable client codes. This bi-level design personalizes the generative layerrather than the downstream modelwhile decoupling local data from communicated parameters. The shared hypernetwork is optimized under differential privacy, ensuring that only noise-perturbed, clipped gradients are aggregated across clients. A local MMD alignment between real and synthetic embeddings and a Lipschitz regularizer on hypernetwork outputs further enhance stability and distributional coherence under non-IID conditions. After training, a neutral meta-code enables domain agnostic synthesis, while mixtures of meta-codes provide controllable multi-domain coverage. FedHypeVAE unifies personalization, privacy, and distribution alignment at the generator level, establishing a principled foundation for privacy-preserving data synthesis in federated settings. Code: github.com/sunnyinAI/FedHypeVAE
Federated Cross-Modal Style-Aware Prompt Generation
Aug 17, 2025Prompt learning has propelled vision-language models like CLIP to excel in diverse tasks, making them ideal for federated learning due to computational efficiency. However, conventional approaches that rely solely on final-layer features miss out on rich multi-scale visual cues and domain-specific style variations in decentralized client data. To bridge this gap, we introduce FedCSAP (Federated Cross-Modal Style-Aware Prompt Generation). Our framework harnesses low, mid, and high-level features from CLIP's vision encoder alongside client-specific style indicators derived from batch-level statistics. By merging intricate visual details with textual context, FedCSAP produces robust, context-aware prompt tokens that are both distinct and non-redundant, thereby boosting generalization across seen and unseen classes. Operating within a federated learning paradigm, our approach ensures data privacy through local training and global aggregation, adeptly handling non-IID class distributions and diverse domain-specific styles. Comprehensive experiments on multiple image classification datasets confirm that FedCSAP outperforms existing federated prompt learning methods in both accuracy and overall generalization.
FEDTAIL: Federated Long-Tailed Domain Generalization with Sharpness-Guided Gradient Matching
Jun 10, 2025Domain Generalization (DG) seeks to train models that perform reliably on unseen target domains without access to target data during training. While recent progress in smoothing the loss landscape has improved generalization, existing methods often falter under long-tailed class distributions and conflicting optimization objectives. We introduce FedTAIL, a federated domain generalization framework that explicitly addresses these challenges through sharpness-guided, gradient-aligned optimization. Our method incorporates a gradient coherence regularizer to mitigate conflicts between classification and adversarial objectives, leading to more stable convergence. To combat class imbalance, we perform class-wise sharpness minimization and propose a curvature-aware dynamic weighting scheme that adaptively emphasizes underrepresented tail classes. Furthermore, we enhance conditional distribution alignment by integrating sharpness-aware perturbations into entropy regularization, improving robustness under domain shift. FedTAIL unifies optimization harmonization, class-aware regularization, and conditional alignment into a scalable, federated-compatible framework. Extensive evaluations across standard domain generalization benchmarks demonstrate that FedTAIL achieves state-of-the-art performance, particularly in the presence of domain shifts and label imbalance, validating its effectiveness in both centralized and federated settings. Code: https://github.com/sunnyinAI/FedTail
UniVarFL: Uniformity and Variance Regularized Federated Learning for Heterogeneous Data
Jun 09, 2025Federated Learning (FL) often suffers from severe performance degradation when faced with non-IID data, largely due to local classifier bias. Traditional remedies such as global model regularization or layer freezing either incur high computational costs or struggle to adapt to feature shifts. In this work, we propose UniVarFL, a novel FL framework that emulates IID-like training dynamics directly at the client level, eliminating the need for global model dependency. UniVarFL leverages two complementary regularization strategies during local training: Classifier Variance Regularization, which aligns class-wise probability distributions with those expected under IID conditions, effectively mitigating local classifier bias; and Hyperspherical Uniformity Regularization, which encourages a uniform distribution of feature representations across the hypersphere, thereby enhancing the model's ability to generalize under diverse data distributions. Extensive experiments on multiple benchmark datasets demonstrate that UniVarFL outperforms existing methods in accuracy, highlighting its potential as a highly scalable and efficient solution for real-world FL deployments, especially in resource-constrained settings. Code: https://github.com/sunnyinAI/UniVarFL
FedAlign: Federated Domain Generalization with Cross-Client Feature Alignment
Jan 26, 2025



Federated Learning (FL) offers a decentralized paradigm for collaborative model training without direct data sharing, yet it poses unique challenges for Domain Generalization (DG), including strict privacy constraints, non-i.i.d. local data, and limited domain diversity. We introduce FedAlign, a lightweight, privacy-preserving framework designed to enhance DG in federated settings by simultaneously increasing feature diversity and promoting domain invariance. First, a cross-client feature extension module broadens local domain representations through domain-invariant feature perturbation and selective cross-client feature transfer, allowing each client to safely access a richer domain space. Second, a dual-stage alignment module refines global feature learning by aligning both feature embeddings and predictions across clients, thereby distilling robust, domain-invariant features. By integrating these modules, our method achieves superior generalization to unseen domains while maintaining data privacy and operating with minimal computational and communication overhead.
Sequential Compression Layers for Efficient Federated Learning in Foundational Models
Dec 09, 2024Federated Learning (FL) has gained popularity for fine-tuning large language models (LLMs) across multiple nodes, each with its own private data. While LoRA has been widely adopted for parameter efficient federated fine-tuning, recent theoretical and empirical studies highlight its suboptimal performance in the federated learning context. In response, we propose a novel, simple, and more effective parameter-efficient fine-tuning method that does not rely on LoRA. Our approach introduces a small multi-layer perceptron (MLP) layer between two existing MLP layers the up proj (the FFN projection layer following the self-attention module) and down proj within the feed forward network of the transformer block. This solution addresses the bottlenecks associated with LoRA in federated fine tuning and outperforms recent LoRA-based approaches, demonstrating superior performance for both language models and vision encoders.
Taming the Tail: Leveraging Asymmetric Loss and Pade Approximation to Overcome Medical Image Long-Tailed Class Imbalance
Oct 05, 2024Long-tailed problems in healthcare emerge from data imbalance due to variability in the prevalence and representation of different medical conditions, warranting the requirement of precise and dependable classification methods. Traditional loss functions such as cross-entropy and binary cross-entropy are often inadequate due to their inability to address the imbalances between the classes with high representation and the classes with low representation found in medical image datasets. We introduce a novel polynomial loss function based on Pade approximation, designed specifically to overcome the challenges associated with long-tailed classification. This approach incorporates asymmetric sampling techniques to better classify under-represented classes. We conducted extensive evaluations on three publicly available medical datasets and a proprietary medical dataset. Our implementation of the proposed loss function is open-sourced in the public repository:https://github.com/ipankhi/ALPA.
FedStein: Enhancing Multi-Domain Federated Learning Through James-Stein Estimator
Oct 04, 2024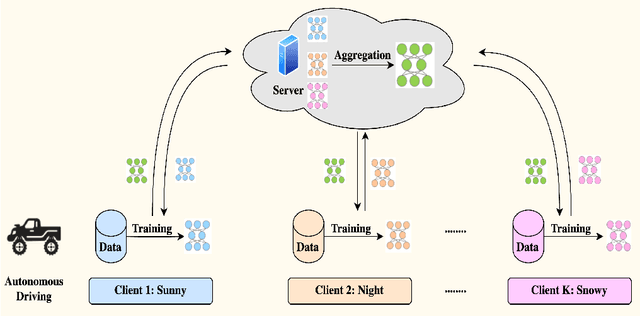

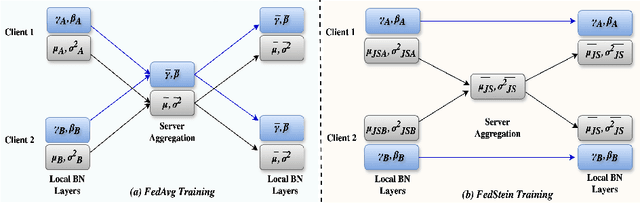

Federated Learning (FL) facilitates data privacy by enabling collaborative in-situ training across decentralized clients. Despite its inherent advantages, FL faces significant challenges of performance and convergence when dealing with data that is not independently and identically distributed (non-i.i.d.). While previous research has primarily addressed the issue of skewed label distribution across clients, this study focuses on the less explored challenge of multi-domain FL, where client data originates from distinct domains with varying feature distributions. We introduce a novel method designed to address these challenges FedStein: Enhancing Multi-Domain Federated Learning Through the James-Stein Estimator. FedStein uniquely shares only the James-Stein (JS) estimates of batch normalization (BN) statistics across clients, while maintaining local BN parameters. The non-BN layer parameters are exchanged via standard FL techniques. Extensive experiments conducted across three datasets and multiple models demonstrate that FedStein surpasses existing methods such as FedAvg and FedBN, with accuracy improvements exceeding 14% in certain domains leading to enhanced domain generalization. The code is available at https://github.com/sunnyinAI/FedStein
CCVA-FL: Cross-Client Variations Adaptive Federated Learning for Medical Imaging
Jul 16, 2024



Federated Learning (FL) offers a privacy-preserving approach to train models on decentralized data. Its potential in healthcare is significant, but challenges arise due to cross-client variations in medical image data, exacerbated by limited annotations. This paper introduces Cross-Client Variations Adaptive Federated Learning (CCVA-FL) to address these issues. CCVA-FL aims to minimize cross-client variations by transforming images into a common feature space. It involves expert annotation of a subset of images from each client, followed by the selection of a client with the least data complexity as the target. Synthetic medical images are then generated using Scalable Diffusion Models with Transformers (DiT) based on the target client's annotated images. These synthetic images, capturing diversity and representing the original data, are shared with other clients. Each client then translates its local images into the target image space using image-to-image translation. The translated images are subsequently used in a federated learning setting to develop a server model. Our results demonstrate that CCVA-FL outperforms Vanilla Federated Averaging by effectively addressing data distribution differences across clients without compromising privacy.