 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioME: A Resource-Efficient Bioacoustic Foundational Model for IoT Applications
Feb 10, 2026Passive acoustic monitoring has become a key strategy in biodiversity assessment, conservation, and behavioral ecology, especially as Internet-of-Things (IoT) devices enable continuous in situ audio collection at scale. While recent self-supervised learning (SSL)-based audio encoders, such as BEATs and AVES, have shown strong performance in bioacoustic tasks, their computational cost and limited robustness to unseen environments hinder deployment on resource-constrained platforms. In this work, we introduce BioME, a resource-efficient audio encoder designed for bioacoustic applications. BioME is trained via layer-to-layer distillation from a high-capacity teacher model, enabling strong representational transfer while reducing the parameter count by 75%. To further improve ecological generalization, the model is pretrained on multi-domain data spanning speech, environmental sounds, and animal vocalizations. A key contribution is the integration of modulation-aware acoustic features via FiLM conditioning, injecting a DSP-inspired inductive bias that enhances feature disentanglement in low-capacity regimes. Across multiple bioacoustic tasks, BioME matches or surpasses the performance of larger models, including its teacher, while being suitable for resource-constrained IoT deployments. For reproducibility, code and pretrained checkpoints are publicly available.
Quantum-Assisted Machine Learning Models for Enhanced Weather Prediction
Mar 30, 2025Quantum Machine Learning (QML) presents as a revolutionary approach to weather forecasting by using quantum computing to improve predictive modeling capabilities. In this study, we apply QML models, including Quantum Gated Recurrent Units (QGRUs), Quantum Neural Networks (QNNs), Quantum Long Short-Term Memory(QLSTM), Variational Quantum Circuits(VQCs), and Quantum Support Vector Machines(QSVMs), to analyze meteorological time-series data from the ERA5 dataset. Our methodology includes preprocessing meteorological features, implementing QML architectures for both classification and regression tasks. The results demonstrate that QML models can achieve reasonable accuracy in both prediction and classification tasks, particularly in binary classification. However, challenges such as quantum hardware limitations and noise affect scalability and generalization. This research provides insights into the feasibility of QML for weather prediction, paving the way for further exploration of hybrid quantum-classical frameworks to enhance meteorological forecasting.
Taming the Tail: Leveraging Asymmetric Loss and Pade Approximation to Overcome Medical Image Long-Tailed Class Imbalance
Oct 05, 2024Long-tailed problems in healthcare emerge from data imbalance due to variability in the prevalence and representation of different medical conditions, warranting the requirement of precise and dependable classification methods. Traditional loss functions such as cross-entropy and binary cross-entropy are often inadequate due to their inability to address the imbalances between the classes with high representation and the classes with low representation found in medical image datasets. We introduce a novel polynomial loss function based on Pade approximation, designed specifically to overcome the challenges associated with long-tailed classification. This approach incorporates asymmetric sampling techniques to better classify under-represented classes. We conducted extensive evaluations on three publicly available medical datasets and a proprietary medical dataset. Our implementation of the proposed loss function is open-sourced in the public repository:https://github.com/ipankhi/ALPA.
Cross-Subject Statistical Shift Estimation for Generalized Electroencephalography-based Mental Workload Assessment
Jun 20, 2019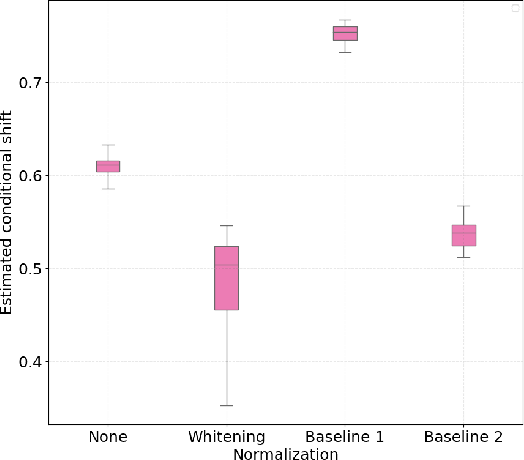
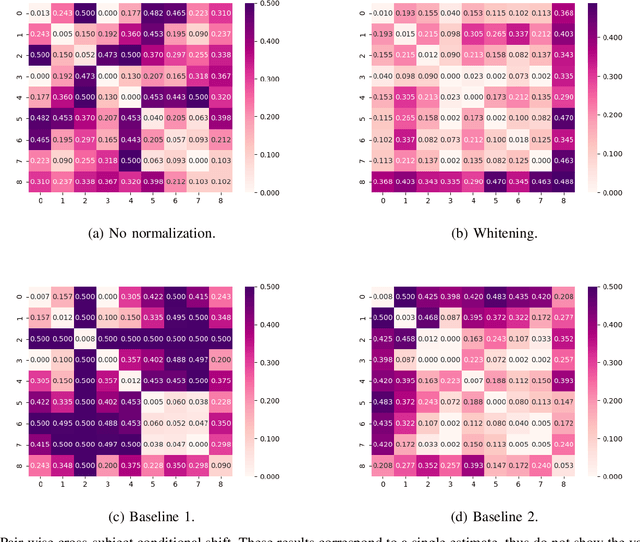
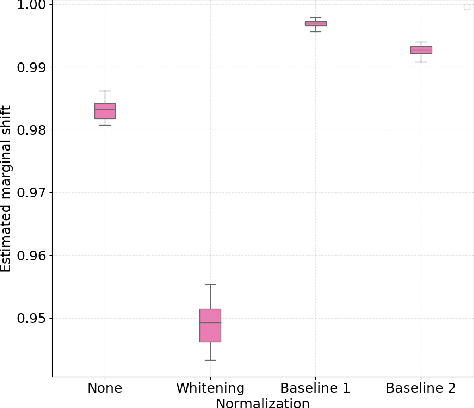
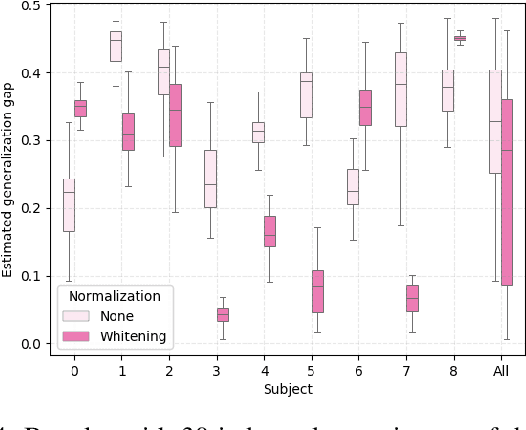
Assessment of mental workload in real world conditions is key to ensure the performance of workers executing tasks which demand sustained attention. Previous literature has employed electroencephalography (EEG) to this end. However, EEG correlates of mental workload vary across subjects and physical strain, thus making it difficult to devise models capable of simultaneously presenting reliable performance across users. The field of domain adaptation (DA) aims at developing methods that allow for generalization across different domains by learning domain-invariant representations. Such DA methods, however, rely on the so-called covariate shift assumption, which typically does not hold for EEG-based applications. As such, in this paper we propose a way to measure the statistical (marginal and conditional) shift observed on data obtained from different users and use this measure to quantitatively assess the effectiveness of different adaptation strategies. In particular, we use EEG data collected from individuals performing a mental task while running in a treadmill and explore the effects of different normalization strategies commonly used to mitigate cross-subject variability. We show the effects that different normalization schemes have on statistical shifts and their relationship with the accuracy of mental workload prediction as assessed on unseen participants at train time.