 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHQA: A Diverse, Knowledge Intensive Mental Health Question Answering Challenge for Language Models
Feb 21, 2025
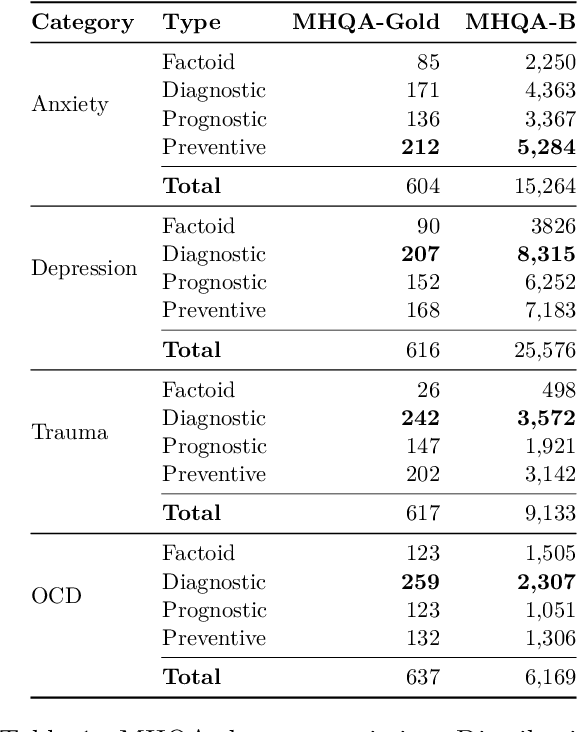
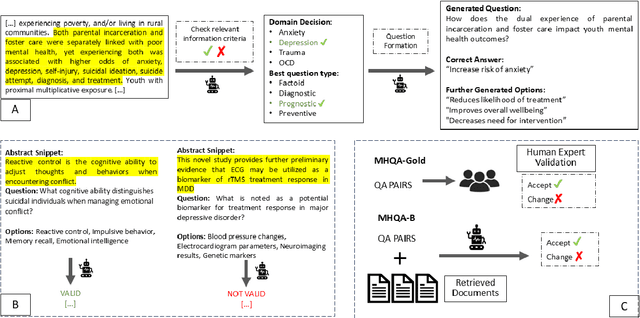
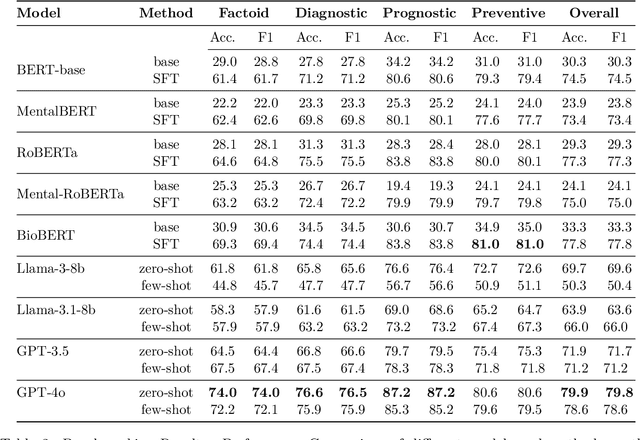
Mental health remains a challenging problem all over the world, with issues like depression, anxiety becoming increasingly common. Large Language Models (LLMs) have seen a vast application in healthcare, specifically in answering medical questions. However, there is a lack of standard benchmarking datasets for question answering (QA) in mental health. Our work presents a novel multiple choice dataset, MHQA (Mental Health Question Answering), for benchmarking Language models (LMs). Previous mental health datasets have focused primarily on text classification into specific labels or disorders. MHQA, on the other hand, presents question-answering for mental health focused on four key domains: anxiety, depression, trauma, and obsessive/compulsive issues, with diverse question types, namely, factoid, diagnostic, prognostic, and preventive. We use PubMed abstracts as the primary source for QA. We develop a rigorous pipeline for LLM-based identification of information from abstracts based on various selection criteria and converting it into QA pairs. Further, valid QA pairs are extracted based on post-hoc validation criteria. Overall, our MHQA dataset consists of 2,475 expert-verified gold standard instances called MHQA-gold and ~56.1k pairs pseudo labeled using external medical references. We report F1 scores on different LLMs along with few-shot and supervised fine-tuning experiments, further discussing the insights for the scores.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.