 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMIND: Framework for Knowledge Grounded Finetuning and Multi-Turn Dialogue Benchmark for Mental Health LLMs
Mar 26, 2026Large Language Models (LLMs) have shown remarkable capabilities for complex tasks, yet adaptation in medical domain, specifically mental health, poses specific challenges. Mental health is a rising concern globally with LLMs having large potential to help address the same. We highlight three primary challenges for LLMs in mental health - lack of high quality interpretable and knowledge grounded training data; training paradigms restricted to core capabilities, and evaluation of multi turn dialogue settings. Addressing it, we present oMind framework which includes training and aligning LLM agents for diverse capabilities including conversations; high quality ~164k multi-task SFT dataset, as a result of our generation pipeline based on Structured Knowledge retrieval, LLM based pruning, and review actions. We also introduce oMind-Chat - a novel multi turn benchmark dataset with expert annotated turn level and conversation level rubrics. Our diverse experiments on both core capabilities and conversations shows oMind LLMs consistently outperform baselines. oMind-LLM also shows significantly better reasoning with up to 80% win rate.
Inducing Robustness in a 2 Dimensional Direct Preference Optimization Paradigm
May 03, 2025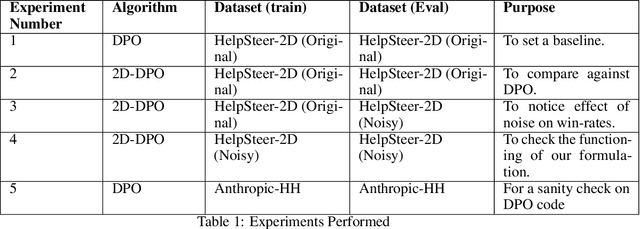
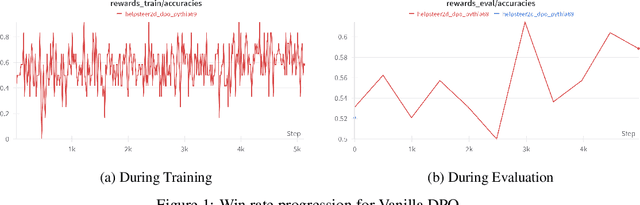
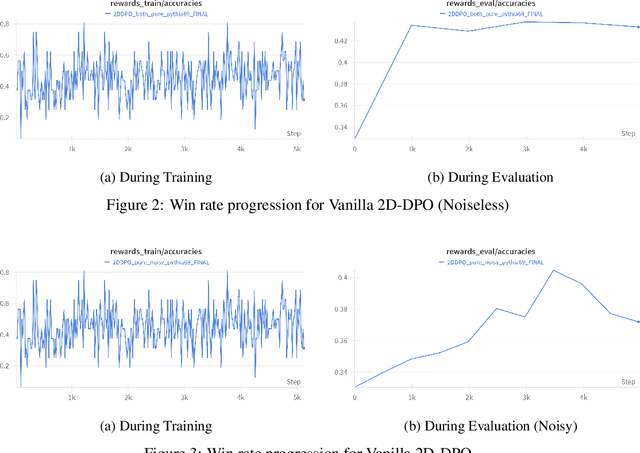

Direct Preference Optimisation (DPO) has emerged as a powerful method for aligning Large Language Models (LLMs) with human preferences, offering a stable and efficient alternative to approaches that use Reinforcement learning via Human Feedback. In this work, we investigate the performance of DPO using open-source preference datasets. One of the major drawbacks of DPO is that it doesn't induce granular scoring and treats all the segments of the responses with equal propensity. However, this is not practically true for human preferences since even "good" responses have segments that may not be preferred by the annotator. To resolve this, a 2-dimensional scoring for DPO alignment called 2D-DPO was proposed. We explore the 2D-DPO alignment paradigm and the advantages it provides over the standard DPO by comparing their win rates. It is observed that these methods, even though effective, are not robust to label/score noise. To counter this, we propose an approach of incorporating segment-level score noise robustness to the 2D-DPO algorithm. Along with theoretical backing, we also provide empirical verification in favour of the algorithm and introduce other noise models that can be present.
Subset Selection for Fine-Tuning: A Utility-Diversity Balanced Approach for Mathematical Domain Adaptation
May 02, 2025
We propose a refined approach to efficiently fine-tune large language models (LLMs) on specific domains like the mathematical domain by employing a budgeted subset selection method. Our approach combines utility and diversity metrics to select the most informative and representative training examples. The final goal is to achieve near-full dataset performance with meticulously selected data points from the entire dataset while significantly reducing computational cost and training time and achieving competitive performance as the full dataset. The utility metric incorporates both perplexity and Chain-of-Thought (CoT) loss to identify challenging examples that contribute most to model learning, while the diversity metric ensures broad coverage across mathematical subdomains. We evaluate our method on LLaMA-3 8B and Phi-3 models, comparing against several baseline approaches, including random selection, diversity-based sampling, and existing state-of-the-art subset selection techniques.
MHQA: A Diverse, Knowledge Intensive Mental Health Question Answering Challenge for Language Models
Feb 21, 2025
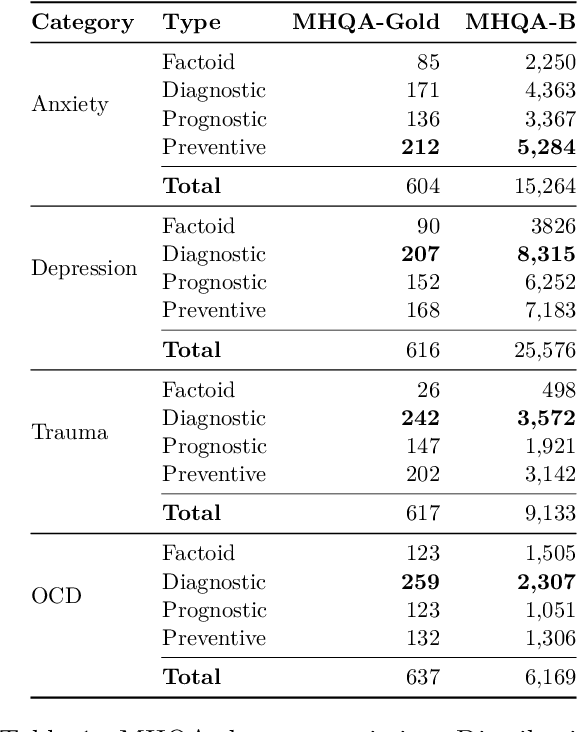
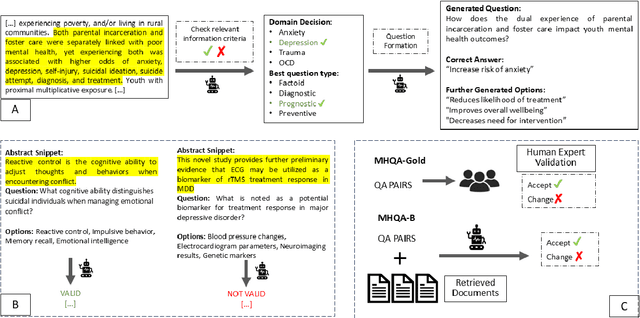
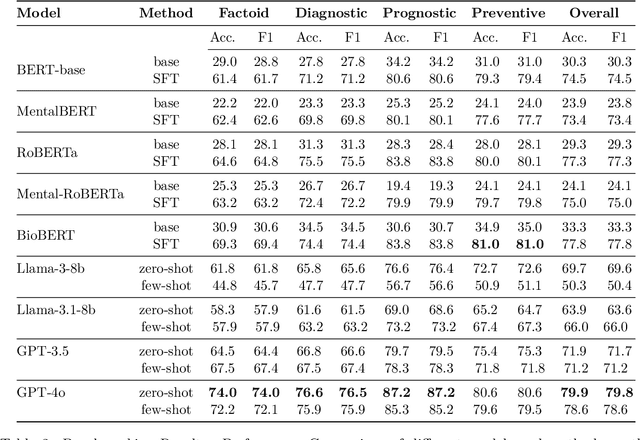
Mental health remains a challenging problem all over the world, with issues like depression, anxiety becoming increasingly common. Large Language Models (LLMs) have seen a vast application in healthcare, specifically in answering medical questions. However, there is a lack of standard benchmarking datasets for question answering (QA) in mental health. Our work presents a novel multiple choice dataset, MHQA (Mental Health Question Answering), for benchmarking Language models (LMs). Previous mental health datasets have focused primarily on text classification into specific labels or disorders. MHQA, on the other hand, presents question-answering for mental health focused on four key domains: anxiety, depression, trauma, and obsessive/compulsive issues, with diverse question types, namely, factoid, diagnostic, prognostic, and preventive. We use PubMed abstracts as the primary source for QA. We develop a rigorous pipeline for LLM-based identification of information from abstracts based on various selection criteria and converting it into QA pairs. Further, valid QA pairs are extracted based on post-hoc validation criteria. Overall, our MHQA dataset consists of 2,475 expert-verified gold standard instances called MHQA-gold and ~56.1k pairs pseudo labeled using external medical references. We report F1 scores on different LLMs along with few-shot and supervised fine-tuning experiments, further discussing the insights for the scores.
Framework for Co-distillation Driven Federated Learning to Address Class Imbalance in Healthcare
Nov 15, 2024



Federated Learning (FL) is a pioneering approach in distributed machine learning, enabling collaborative model training across multiple clients while retaining data privacy. However, the inherent heterogeneity due to imbalanced resource representations across multiple clients poses significant challenges, often introducing bias towards the majority class. This issue is particularly prevalent in healthcare settings, where hospitals acting as clients share medical images. To address class imbalance and reduce bias, we propose a co-distillation driven framework in a federated healthcare setting. Unlike traditional federated setups with a designated server client, our framework promotes knowledge sharing among clients to collectively improve learning outcomes. Our experiments demonstrate that in a federated healthcare setting, co-distillation outperforms other federated methods in handling class imbalance. Additionally, we demonstrate that our framework has the least standard deviation with increasing imbalance while outperforming other baselines, signifying the robustness of our framework for FL in healthcare.
GUIDEQ: Framework for Guided Questioning for progressive informational collection and classification
Nov 08, 2024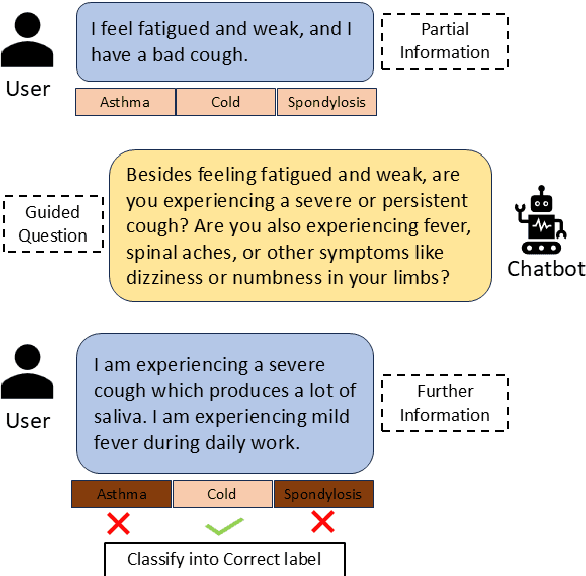
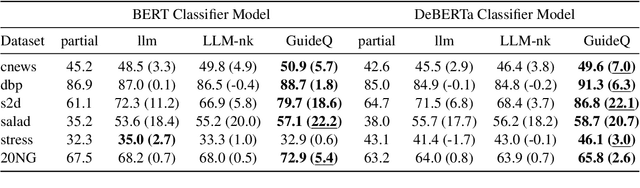
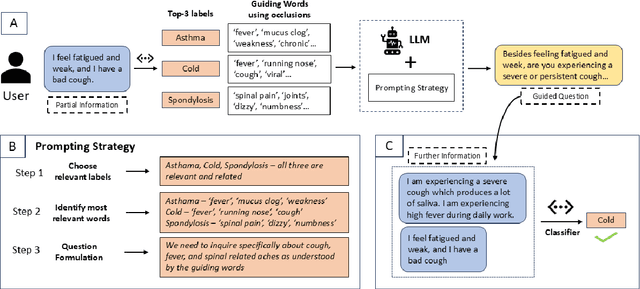
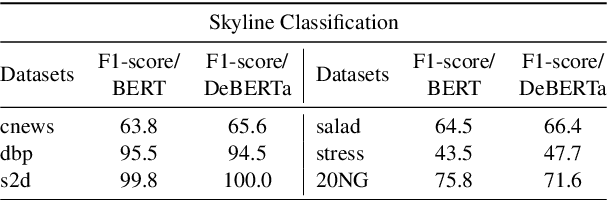
Question Answering (QA) is an important part of tasks like text classification through information gathering. These are finding increasing use in sectors like healthcare, customer support, legal services, etc., to collect and classify responses into actionable categories. LLMs, although can support QA systems, they face a significant challenge of insufficient or missing information for classification. Although LLMs excel in reasoning, the models rely on their parametric knowledge to answer. However, questioning the user requires domain-specific information aiding to collect accurate information. Our work, GUIDEQ, presents a novel framework for asking guided questions to further progress a partial information. We leverage the explainability derived from the classifier model for along with LLMs for asking guided questions to further enhance the information. This further information helps in more accurate classification of a text. GUIDEQ derives the most significant key-words representative of a label using occlusions. We develop GUIDEQ's prompting strategy for guided questions based on the top-3 classifier label outputs and the significant words, to seek specific and relevant information, and classify in a targeted manner. Through our experimental results, we demonstrate that GUIDEQ outperforms other LLM-based baselines, yielding improved F1-Score through the accurate collection of relevant further information. We perform various analytical studies and also report better question quality compared to our method.