 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Safety Subspaces are Not Distinct: A Fine-Tuning Case Study
May 20, 2025
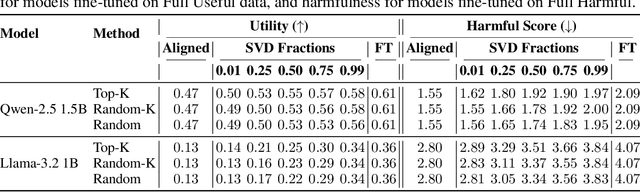


Large Language Models (LLMs) rely on safety alignment to produce socially acceptable responses. This is typically achieved through instruction tuning and reinforcement learning from human feedback. However, this alignment is known to be brittle: further fine-tuning, even on benign or lightly contaminated data, can degrade safety and reintroduce harmful behaviors. A growing body of work suggests that alignment may correspond to identifiable geometric directions in weight space, forming subspaces that could, in principle, be isolated or preserved to defend against misalignment. In this work, we conduct a comprehensive empirical study of this geometric perspective. We examine whether safety-relevant behavior is concentrated in specific subspaces, whether it can be separated from general-purpose learning, and whether harmfulness arises from distinguishable patterns in internal representations. Across both parameter and activation space, our findings are consistent: subspaces that amplify safe behaviors also amplify unsafe ones, and prompts with different safety implications activate overlapping representations. We find no evidence of a subspace that selectively governs safety. These results challenge the assumption that alignment is geometrically localized. Rather than residing in distinct directions, safety appears to emerge from entangled, high-impact components of the model's broader learning dynamics. This suggests that subspace-based defenses may face fundamental limitations and underscores the need for alternative strategies to preserve alignment under continued training. We corroborate these findings through multiple experiments on five open-source LLMs. Our code is publicly available at: https://github.com/CERT-Lab/safety-subspaces.
ABBA: Highly Expressive Hadamard Product Adaptation for Large Language Models
May 20, 2025



Large Language Models have demonstrated strong performance across a wide range of tasks, but adapting them efficiently to new domains remains a key challenge. Parameter-Efficient Fine-Tuning (PEFT) methods address this by introducing lightweight, trainable modules while keeping most pre-trained weights fixed. The prevailing approach, LoRA, models updates using a low-rank decomposition, but its expressivity is inherently constrained by the rank. Recent methods like HiRA aim to increase expressivity by incorporating a Hadamard product with the frozen weights, but still rely on the structure of the pre-trained model. We introduce ABBA, a new PEFT architecture that reparameterizes the update as a Hadamard product of two independently learnable low-rank matrices. In contrast to prior work, ABBA fully decouples the update from the pre-trained weights, enabling both components to be optimized freely. This leads to significantly higher expressivity under the same parameter budget. We formally analyze ABBA's expressive capacity and validate its advantages through matrix reconstruction experiments. Empirically, ABBA achieves state-of-the-art results on arithmetic and commonsense reasoning benchmarks, consistently outperforming existing PEFT methods by a significant margin across multiple models. Our code is publicly available at: https://github.com/CERT-Lab/abba.
Fed-SB: A Silver Bullet for Extreme Communication Efficiency and Performance in (Private) Federated LoRA Fine-Tuning
Feb 21, 2025



Low-Rank Adaptation (LoRA) has become ubiquitous for efficiently fine-tuning foundation models. However, federated fine-tuning using LoRA is challenging due to suboptimal updates arising from traditional federated averaging of individual adapters. Existing solutions either incur prohibitively high communication cost that scales linearly with the number of clients or suffer from performance degradation due to limited expressivity. We introduce Federated Silver Bullet (Fed-SB), a novel approach for federated fine-tuning of LLMs using LoRA-SB, a recently proposed low-rank adaptation method. LoRA-SB optimally aligns the optimization trajectory with the ideal low-rank full fine-tuning projection by learning a small square matrix (R) between adapters B and A, keeping other components fixed. Direct averaging of R guarantees exact updates, substantially reducing communication cost, which remains independent of the number of clients, and enables scalability. Fed-SB achieves state-of-the-art performance across commonsense reasoning, arithmetic reasoning, and language inference tasks while reducing communication costs by up to 230x. In private settings, Fed-SB further improves performance by (1) reducing trainable parameters, thereby lowering the noise required for differential privacy and (2) avoiding noise amplification introduced by other methods. Overall, Fed-SB establishes a new Pareto frontier in the tradeoff between communication and performance, offering an efficient and scalable solution for both private and non-private federated fine-tuning. Our code is publicly available at https://github.com/CERT-Lab/fed-sb.
A Lightweight Method to Disrupt Memorized Sequences in LLM
Feb 07, 2025Large language models (LLMs) demonstrate impressive capabilities across many tasks yet risk reproducing copyrighted content verbatim, raising legal and ethical concerns. Although methods like differential privacy or neuron editing can reduce memorization, they typically require costly retraining or direct access to model weights and may degrade performance. To address these challenges, we propose TokenSwap, a lightweight, post-hoc approach that replaces the probabilities of grammar-related tokens with those from a small auxiliary model (e.g., DistilGPT-2). We run extensive experiments on commercial grade models such as Pythia-6.9b and LLaMA-3-8b and demonstrate that our method effectively reduces well-known cases of memorized generation by upto 10x with little to no impact on downstream tasks. Our approach offers a uniquely accessible and effective solution to users of real-world systems.
Initialization using Update Approximation is a Silver Bullet for Extremely Efficient Low-Rank Fine-Tuning
Nov 29, 2024



Low-rank adapters have become a standard approach for efficiently fine-tuning large language models (LLMs), but they often fall short of achieving the performance of full fine-tuning. We propose a method, LoRA Silver Bullet or LoRA-SB, that approximates full fine-tuning within low-rank subspaces using a carefully designed initialization strategy. We theoretically demonstrate that the architecture of LoRA-XS, which inserts a trainable (r x r) matrix between B and A while keeping other matrices fixed, provides the precise conditions needed for this approximation. We leverage its constrained update space to achieve optimal scaling for high-rank gradient updates while removing the need for hyperparameter tuning. We prove that our initialization offers an optimal low-rank approximation of the initial gradient and preserves update directions throughout training. Extensive experiments across mathematical reasoning, commonsense reasoning, and language understanding tasks demonstrate that our approach exceeds the performance of standard LoRA while using 27-90x fewer parameters, and comprehensively outperforms LoRA-XS. Our findings establish that it is possible to simulate full fine-tuning in low-rank subspaces, and achieve significant efficiency gains without sacrificing performance. Our code is publicly available at https://github.com/RaghavSinghal10/lora-sb.
StructFormer: Document Structure-based Masked Attention and its Impact on Language Model Pre-Training
Nov 25, 2024
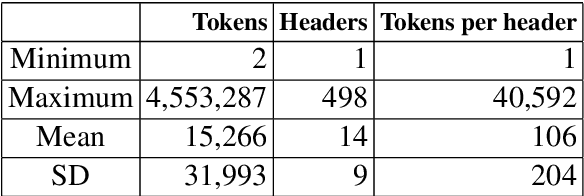

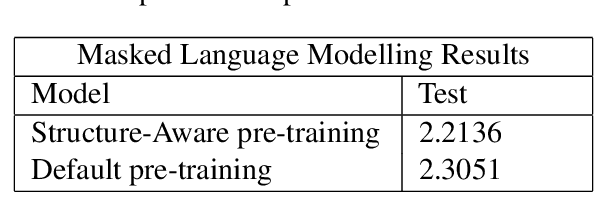
Most state-of-the-art techniques for Language Models (LMs) today rely on transformer-based architectures and their ubiquitous attention mechanism. However, the exponential growth in computational requirements with longer input sequences confines Transformers to handling short passages. Recent efforts have aimed to address this limitation by introducing selective attention mechanisms, notably local and global attention. While sparse attention mechanisms, akin to full attention in being Turing-complete, have been theoretically established, their practical impact on pre-training remains unexplored. This study focuses on empirically assessing the influence of global attention on BERT pre-training. The primary steps involve creating an extensive corpus of structure-aware text through arXiv data, alongside a text-only counterpart. We carry out pre-training on these two datasets, investigate shifts in attention patterns, and assess their implications for downstream tasks. Our analysis underscores the significance of incorporating document structure into LM models, demonstrating their capacity to excel in more abstract tasks, such as document understanding.
GUIDEQ: Framework for Guided Questioning for progressive informational collection and classification
Nov 08, 2024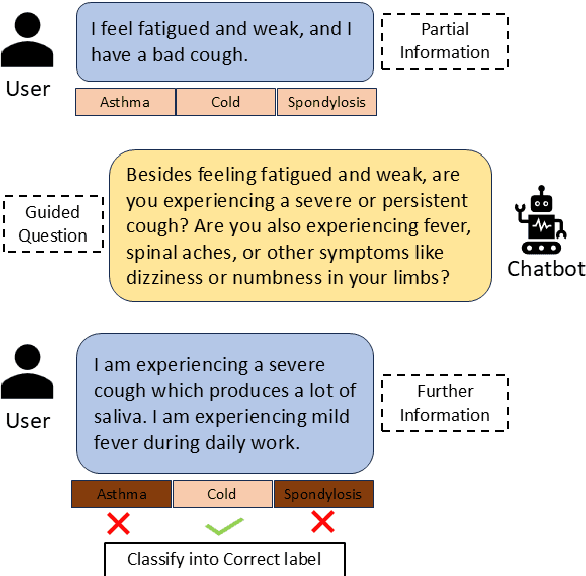
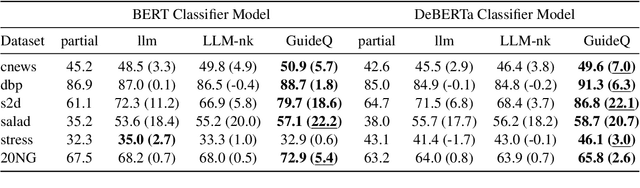
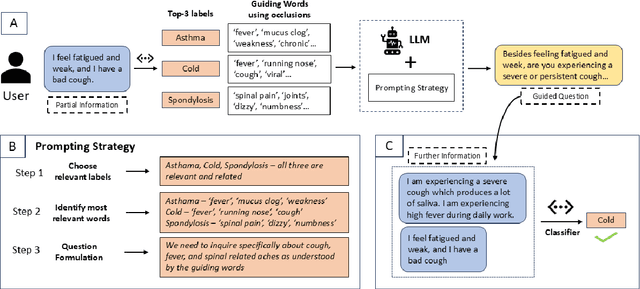
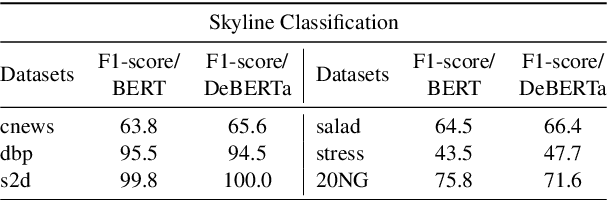
Question Answering (QA) is an important part of tasks like text classification through information gathering. These are finding increasing use in sectors like healthcare, customer support, legal services, etc., to collect and classify responses into actionable categories. LLMs, although can support QA systems, they face a significant challenge of insufficient or missing information for classification. Although LLMs excel in reasoning, the models rely on their parametric knowledge to answer. However, questioning the user requires domain-specific information aiding to collect accurate information. Our work, GUIDEQ, presents a novel framework for asking guided questions to further progress a partial information. We leverage the explainability derived from the classifier model for along with LLMs for asking guided questions to further enhance the information. This further information helps in more accurate classification of a text. GUIDEQ derives the most significant key-words representative of a label using occlusions. We develop GUIDEQ's prompting strategy for guided questions based on the top-3 classifier label outputs and the significant words, to seek specific and relevant information, and classify in a targeted manner. Through our experimental results, we demonstrate that GUIDEQ outperforms other LLM-based baselines, yielding improved F1-Score through the accurate collection of relevant further information. We perform various analytical studies and also report better question quality compared to our method.
Exact Aggregation for Federated and Efficient Fine-Tuning of Foundation Models
Oct 12, 2024



Low-Rank Adaptation (LoRA) is a popular technique for efficient fine-tuning of foundation models. However, applying LoRA in federated learning environments, where data is distributed across multiple clients, presents unique challenges. Existing methods rely on traditional federated averaging of LoRA adapters, resulting in inexact updates. To address this, we propose Federated Exact LoRA, or FedEx-LoRA, which adds a residual error term to the pretrained frozen weight matrix. Our approach achieves exact updates with minimal computational and communication overhead, preserving LoRA's efficiency. We evaluate the method on various Natural Language Understanding (NLU) and Natural Language Generation (NLG) tasks, showing consistent performance gains over state-of-the-art methods across multiple settings. Through extensive analysis, we quantify that the deviations in updates from the ideal solution are significant, highlighting the need for exact aggregation. Our method's simplicity, efficiency, and broad applicability position it as a promising solution for accurate and effective federated fine-tuning of foundation models.