 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructFormer: Document Structure-based Masked Attention and its Impact on Language Model Pre-Training
Paper and Code
Nov 25, 2024
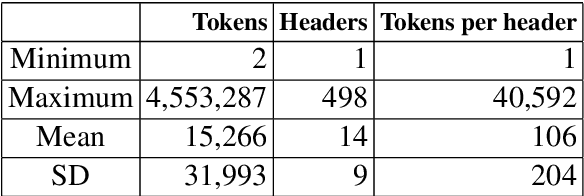

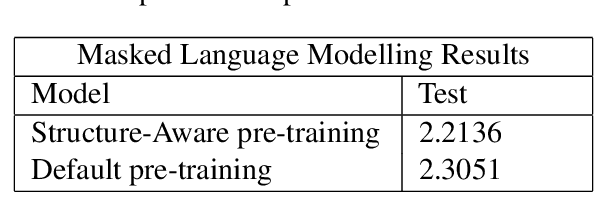
Most state-of-the-art techniques for Language Models (LMs) today rely on transformer-based architectures and their ubiquitous attention mechanism. However, the exponential growth in computational requirements with longer input sequences confines Transformers to handling short passages. Recent efforts have aimed to address this limitation by introducing selective attention mechanisms, notably local and global attention. While sparse attention mechanisms, akin to full attention in being Turing-complete, have been theoretically established, their practical impact on pre-training remains unexplored. This study focuses on empirically assessing the influence of global attention on BERT pre-training. The primary steps involve creating an extensive corpus of structure-aware text through arXiv data, alongside a text-only counterpart. We carry out pre-training on these two datasets, investigate shifts in attention patterns, and assess their implications for downstream tasks. Our analysis underscores the significance of incorporating document structure into LM models, demonstrating their capacity to excel in more abstract tasks, such as document understanding.