 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed-CAM: Minimal Evidence for Explaining Medical Decision Making
Apr 15, 2026Reliable and interpretable decision-making is essential in medical imaging, where diagnostic outcomes directly influence patient care. Despite advances in deep learning, most medical AI systems operate as opaque black boxes, providing little insight into why a particular diagnosis was reached. In this paper, we introduce Med-CAM, a framework for generating minimal and sharp maps as evidence-based explanations for Medical decision making via Classifier Activation Matching. Med-CAM trains a segmentation network from scratch to produce a mask that highlights the minimal evidence critical to model's decision for any seen or unseen image. This ensures that the explanation is both faithful to the network's behaviour and interpretable to clinicians. Experiments show, unlike prior spatial explanation methods, such as Grad-CAM and attention maps, which yield only fuzzy regions of relative importance, Med-CAM with its superior spatial awareness to shapes, textures, and boundaries, delivers conclusive, evidence-based explanations that faithfully replicate the model's prediction for any given image. By explicitly constraining explanations to be compact, consistent with model activations, and diagnostic alignment, Med-CAM advances transparent AI to foster clinician understanding and trust in high-stakes medical applications such as pathology and radiology.
Network Inversion for Uncertainty-Aware Out-of-Distribution Detection
May 29, 2025Out-of-distribution (OOD) detection and uncertainty estimation (UE) are critical components for building safe machine learning systems, especially in real-world scenarios where unexpected inputs are inevitable. In this work, we propose a novel framework that combines network inversion with classifier training to simultaneously address both OOD detection and uncertainty estimation. For a standard n-class classification task, we extend the classifier to an (n+1)-class model by introducing a "garbage" class, initially populated with random gaussian noise to represent outlier inputs. After each training epoch, we use network inversion to reconstruct input images corresponding to all output classes that initially appear as noisy and incoherent and are therefore excluded to the garbage class for retraining the classifier. This cycle of training, inversion, and exclusion continues iteratively till the inverted samples begin to resemble the in-distribution data more closely, suggesting that the classifier has learned to carve out meaningful decision boundaries while sanitising the class manifolds by pushing OOD content into the garbage class. During inference, this training scheme enables the model to effectively detect and reject OOD samples by classifying them into the garbage class. Furthermore, the confidence scores associated with each prediction can be used to estimate uncertainty for both in-distribution and OOD inputs. Our approach is scalable, interpretable, and does not require access to external OOD datasets or post-hoc calibration techniques while providing a unified solution to the dual challenges of OOD detection and uncertainty estimation.
Network Inversion for Generating Confidently Classified Counterfeits
Mar 26, 2025In machine learning, especially with vision classifiers, generating inputs that are confidently classified by the model is essential for understanding its decision boundaries and behavior. However, creating such samples that are confidently classified yet distinct from the training data distribution is a challenge. Traditional methods often modify existing inputs, but they don't always ensure confident classification. In this work, we extend network inversion techniques to generate Confidently Classified Counterfeits-synthetic samples that are confidently classified by the model despite being significantly different from the training data. We achieve this by modifying the generator's conditioning mechanism from soft vector conditioning to one-hot vector conditioning and applying Kullback-Leibler divergence (KLD) between the one-hot vectors and the classifier's output distribution. This encourages the generator to produce samples that are both plausible and confidently classified. Generating Confidently Classified Counterfeits is crucial for ensuring the safety and reliability of machine learning systems, particularly in safety-critical applications where models must exhibit confidence only on data within the training distribution. By generating such counterfeits, we challenge the assumption that high-confidence predictions are always indicative of in-distribution data, providing deeper insights into the model's limitations and decision-making process.
Shortcut Learning Susceptibility in Vision Classifiers
Feb 13, 2025


Shortcut learning, where machine learning models exploit spurious correlations in data instead of capturing meaningful features, poses a significant challenge to building robust and generalizable models. This phenomenon is prevalent across various machine learning applications, including vision, natural language processing, and speech recognition, where models may find unintended cues that minimize training loss but fail to capture the underlying structure of the data. Vision classifiers such as Convolutional Neural Networks (CNNs), Multi-Layer Perceptrons (MLPs), and Vision Transformers (ViTs) leverage distinct architectural principles to process spatial and structural information, making them differently susceptible to shortcut learning. In this study, we systematically evaluate these architectures by introducing deliberate shortcuts into the dataset that are positionally correlated with class labels, creating a controlled setup to assess whether models rely on these artificial cues or learn actual distinguishing features. We perform both quantitative evaluation by training on the shortcut-modified dataset and testing them on two different test sets -- one containing the same shortcuts and another without them -- to determine the extent of reliance on shortcuts. Additionally, qualitative evaluation is performed by using network inversion-based reconstruction techniques to analyze what the models internalize in their weights, aiming to reconstruct the training data as perceived by the classifiers. We evaluate shortcut learning behavior across multiple benchmark datasets, including MNIST, Fashion-MNIST, SVHN, and CIFAR-10, to compare the susceptibility of different vision classifier architectures to shortcut reliance and assess their varying degrees of sensitivity to spurious correlations.
Privacy Preserving Properties of Vision Classifiers
Feb 02, 2025


Vision classifiers are often trained on proprietary datasets containing sensitive information, yet the models themselves are frequently shared openly under the privacy-preserving assumption. Although these models are assumed to protect sensitive information in their training data, the extent to which this assumption holds for different architectures remains unexplored. This assumption is challenged by inversion attacks which attempt to reconstruct training data from model weights, exposing significant privacy vulnerabilities. In this study, we systematically evaluate the privacy-preserving properties of vision classifiers across diverse architectures, including Multi-Layer Perceptrons (MLPs), Convolutional Neural Networks (CNNs), and Vision Transformers (ViTs). Using network inversion-based reconstruction techniques, we assess the extent to which these architectures memorize and reveal training data, quantifying the relative ease of reconstruction across models. Our analysis highlights how architectural differences, such as input representation, feature extraction mechanisms, and weight structures, influence privacy risks. By comparing these architectures, we identify which are more resilient to inversion attacks and examine the trade-offs between model performance and privacy preservation, contributing to the development of secure and privacy-respecting machine learning models for sensitive applications. Our findings provide actionable insights into the design of secure and privacy-aware machine learning systems, emphasizing the importance of evaluating architectural decisions in sensitive applications involving proprietary or personal data.
Network Inversion and Its Applications
Nov 26, 2024



Neural networks have emerged as powerful tools across various applications, yet their decision-making process often remains opaque, leading to them being perceived as "black boxes." This opacity raises concerns about their interpretability and reliability, especially in safety-critical scenarios. Network inversion techniques offer a solution by allowing us to peek inside these black boxes, revealing the features and patterns learned by the networks behind their decision-making processes and thereby provide valuable insights into how neural networks arrive at their conclusions, making them more interpretable and trustworthy. This paper presents a simple yet effective approach to network inversion using a meticulously conditioned generator that learns the data distribution in the input space of the trained neural network, enabling the reconstruction of inputs that would most likely lead to the desired outputs. To capture the diversity in the input space for a given output, instead of simply revealing the conditioning labels to the generator, we encode the conditioning label information into vectors and intermediate matrices and further minimize the cosine similarity between features of the generated images. Additionally, we incorporate feature orthogonality as a regularization term to boost image diversity which penalises the deviations of the Gram matrix of the features from the identity matrix, ensuring orthogonality and promoting distinct, non-redundant representations for each label. The paper concludes by exploring immediate applications of the proposed network inversion approach in interpretability, out-of-distribution detection, and training data reconstruction.
Network Inversion for Training-Like Data Reconstruction
Oct 22, 2024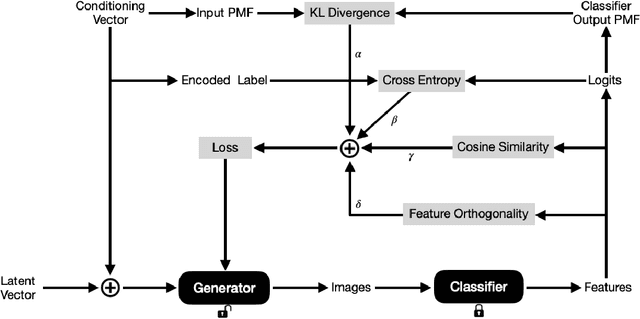
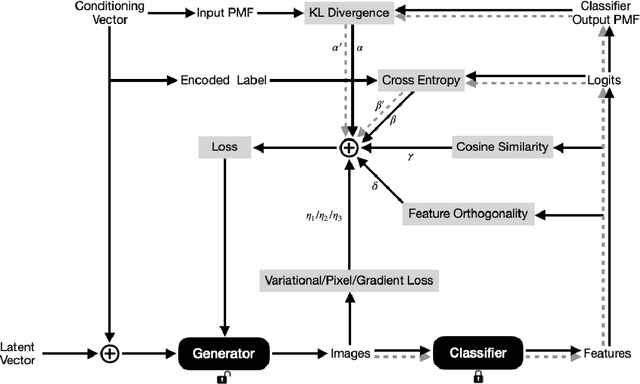
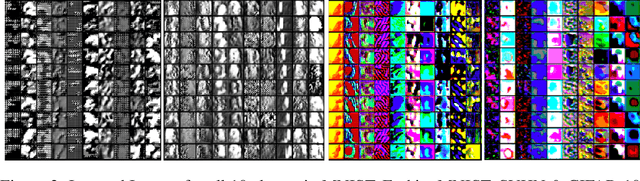
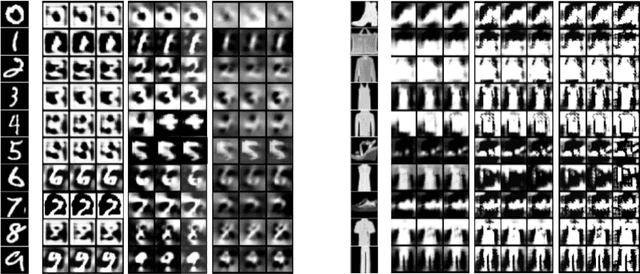
Machine Learning models are often trained on proprietary and private data that cannot be shared, though the trained models themselves are distributed openly assuming that sharing model weights is privacy preserving, as training data is not expected to be inferred from the model weights. In this paper, we present Training-Like Data Reconstruction (TLDR), a network inversion-based approach to reconstruct training-like data from trained models. To begin with, we introduce a comprehensive network inversion technique that learns the input space corresponding to different classes in the classifier using a single conditioned generator. While inversion may typically return random and arbitrary input images for a given output label, we modify the inversion process to incentivize the generator to reconstruct training-like data by exploiting key properties of the classifier with respect to the training data along with some prior knowledge about the images. To validate our approach, we conduct empirical evaluations on multiple standard vision classification datasets, thereby highlighting the potential privacy risks involved in sharing machine learning models.
Network Inversion of Convolutional Neural Nets
Jul 25, 2024



Neural networks have emerged as powerful tools across various applications, yet their decision-making process often remains opaque, leading to them being perceived as "black boxes." This opacity raises concerns about their interpretability and reliability, especially in safety-critical scenarios. Network inversion techniques offer a solution by allowing us to peek inside these black boxes, revealing the features and patterns learned by the networks behind their decision-making processes and thereby provide valuable insights into how neural networks arrive at their conclusions, making them more interpretable and trustworthy. This paper presents a simple yet effective approach to network inversion using a carefully conditioned generator that learns the data distribution in the input space of the trained neural network, enabling the reconstruction of inputs that would most likely lead to the desired outputs. To capture the diversity in the input space for a given output, instead of simply revealing the conditioning labels to the generator, we hideously encode the conditioning label information into vectors, further exemplified by heavy dropout in the generation process and minimisation of cosine similarity between the features corresponding to the generated images. The paper concludes with immediate applications of Network Inversion including in interpretability, explainability and generation of adversarial samples.
Network Inversion of Binarised Neural Nets
Feb 19, 2024While the deployment of neural networks, yielding impressive results, becomes more prevalent in various applications, their interpretability and understanding remain a critical challenge. Network inversion, a technique that aims to reconstruct the input space from the model's learned internal representations, plays a pivotal role in unraveling the black-box nature of input to output mappings in neural networks. In safety-critical scenarios, where model outputs may influence pivotal decisions, the integrity of the corresponding input space is paramount, necessitating the elimination of any extraneous "garbage" to ensure the trustworthiness of the network. Binarised Neural Networks (BNNs), characterized by binary weights and activations, offer computational efficiency and reduced memory requirements, making them suitable for resource-constrained environments. This paper introduces a novel approach to invert a trained BNN by encoding it into a CNF formula that captures the network's structure, allowing for both inference and inversion.