 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Performer RS-IMLE for Single-pass Multisensory Imitation Learning
Feb 02, 2026Robotic imitation learning typically requires models that capture multimodal action distributions while operating at real-time control rates and accommodating multiple sensing modalities. Although recent generative approaches such as diffusion models, flow matching, and Implicit Maximum Likelihood Estimation (IMLE) have achieved promising results, they often satisfy only a subset of these requirements. To address this, we introduce PRISM, a single-pass policy based on a batch-global rejection-sampling variant of IMLE. PRISM couples a temporal multisensory encoder (integrating RGB, depth, tactile, audio, and proprioception) with a linear-attention generator using a Performer architecture. We demonstrate the efficacy of PRISM on a diverse real-world hardware suite, including loco-manipulation using a Unitree Go2 with a 7-DoF arm D1 and tabletop manipulation with a UR5 manipulator. Across challenging physical tasks such as pre-manipulation parking, high-precision insertion, and multi-object pick-and-place, PRISM outperforms state-of-the-art diffusion policies by 10-25% in success rate while maintaining high-frequency (30-50 Hz) closed-loop control. We further validate our approach on large-scale simulation benchmarks, including CALVIN, MetaWorld, and Robomimic. In CALVIN (10% data split), PRISM improves success rates by approximately 25% over diffusion and approximately 20% over flow matching, while simultaneously reducing trajectory jerk by 20x-50x. These results position PRISM as a fast, accurate, and multisensory imitation policy that retains multimodal action coverage without the latency of iterative sampling.
VARP: Reinforcement Learning from Vision-Language Model Feedback with Agent Regularized Preferences
Mar 18, 2025Designing reward functions for continuous-control robotics often leads to subtle misalignments or reward hacking, especially in complex tasks. Preference-based RL mitigates some of these pitfalls by learning rewards from comparative feedback rather than hand-crafted signals, yet scaling human annotations remains challenging. Recent work uses Vision-Language Models (VLMs) to automate preference labeling, but a single final-state image generally fails to capture the agent's full motion. In this paper, we present a two-part solution that both improves feedback accuracy and better aligns reward learning with the agent's policy. First, we overlay trajectory sketches on final observations to reveal the path taken, allowing VLMs to provide more reliable preferences-improving preference accuracy by approximately 15-20% in metaworld tasks. Second, we regularize reward learning by incorporating the agent's performance, ensuring that the reward model is optimized based on data generated by the current policy; this addition boosts episode returns by 20-30% in locomotion tasks. Empirical studies on metaworld demonstrate that our method achieves, for instance, around 70-80% success rate in all tasks, compared to below 50% for standard approaches. These results underscore the efficacy of combining richer visual representations with agent-aware reward regularization.
Sketch-to-Skill: Bootstrapping Robot Learning with Human Drawn Trajectory Sketches
Mar 14, 2025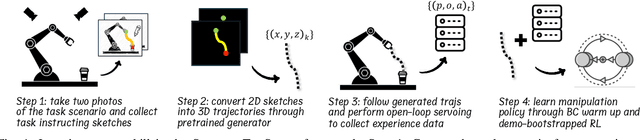
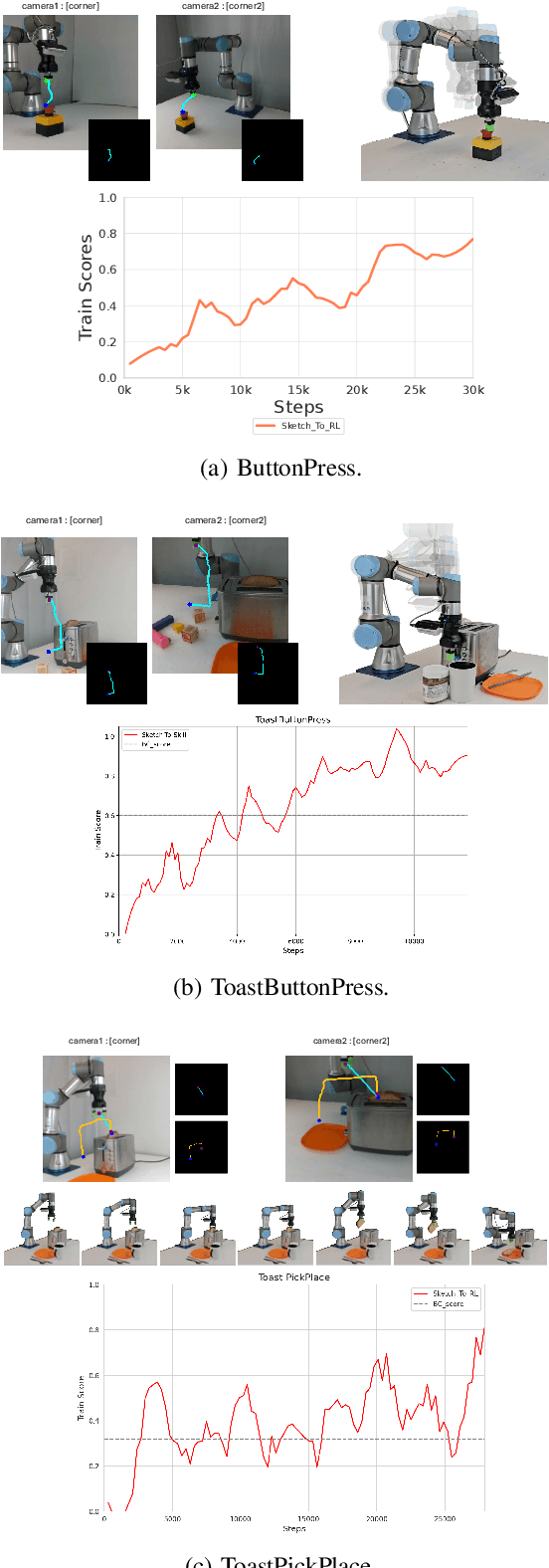
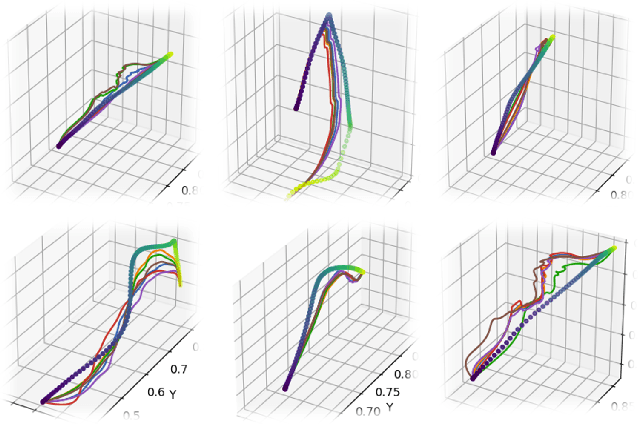
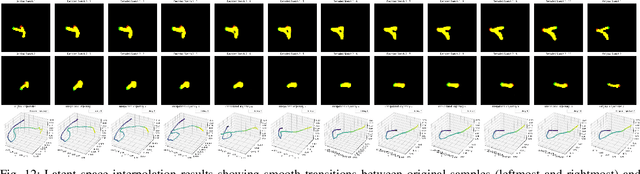
Training robotic manipulation policies traditionally requires numerous demonstrations and/or environmental rollouts. While recent Imitation Learning (IL) and Reinforcement Learning (RL) methods have reduced the number of required demonstrations, they still rely on expert knowledge to collect high-quality data, limiting scalability and accessibility. We propose Sketch-to-Skill, a novel framework that leverages human-drawn 2D sketch trajectories to bootstrap and guide RL for robotic manipulation. Our approach extends beyond previous sketch-based methods, which were primarily focused on imitation learning or policy conditioning, limited to specific trained tasks. Sketch-to-Skill employs a Sketch-to-3D Trajectory Generator that translates 2D sketches into 3D trajectories, which are then used to autonomously collect initial demonstrations. We utilize these sketch-generated demonstrations in two ways: to pre-train an initial policy through behavior cloning and to refine this policy through RL with guided exploration. Experimental results demonstrate that Sketch-to-Skill achieves ~96% of the performance of the baseline model that leverages teleoperated demonstration data, while exceeding the performance of a pure reinforcement learning policy by ~170%, only from sketch inputs. This makes robotic manipulation learning more accessible and potentially broadens its applications across various domains.
Mitigating Memorization in LLMs using Activation Steering
Mar 08, 2025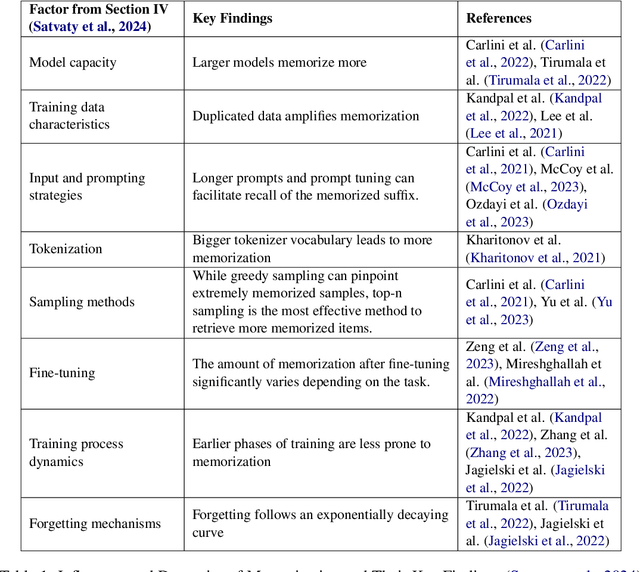
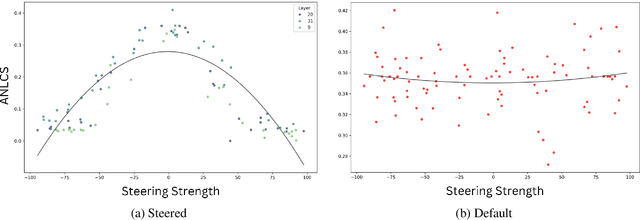
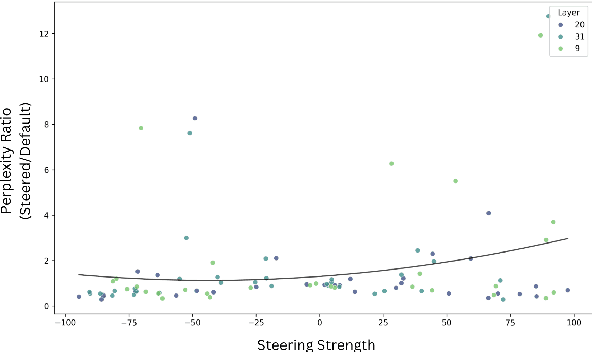
The memorization of training data by Large Language Models (LLMs) poses significant risks, including privacy leaks and the regurgitation of copyrighted content. Activation steering, a technique that directly intervenes in model activations, has emerged as a promising approach for manipulating LLMs. In this work, we explore the effectiveness of activation steering in reducing memorization while preserving generalization capabilities. We conduct empirical evaluations using a controlled memorization benchmark of literary material and demonstrate that our method successfully suppresses memorized content with minimal degradation in model performance in Gemma. Additionally, we analyze the trade-offs between suppression effectiveness and linguistic fluency, highlighting the advantages and limitations of activation-based interventions. Our findings contribute to ongoing efforts in developing safer and more privacy-preserving LLMs by providing a practical and efficient mechanism to mitigate unintended memorization.
IMRL: Integrating Visual, Physical, Temporal, and Geometric Representations for Enhanced Food Acquisition
Sep 18, 2024Robotic assistive feeding holds significant promise for improving the quality of life for individuals with eating disabilities. However, acquiring diverse food items under varying conditions and generalizing to unseen food presents unique challenges. Existing methods that rely on surface-level geometric information (e.g., bounding box and pose) derived from visual cues (e.g., color, shape, and texture) often lacks adaptability and robustness, especially when foods share similar physical properties but differ in visual appearance. We employ imitation learning (IL) to learn a policy for food acquisition. Existing methods employ IL or Reinforcement Learning (RL) to learn a policy based on off-the-shelf image encoders such as ResNet-50. However, such representations are not robust and struggle to generalize across diverse acquisition scenarios. To address these limitations, we propose a novel approach, IMRL (Integrated Multi-Dimensional Representation Learning), which integrates visual, physical, temporal, and geometric representations to enhance the robustness and generalizability of IL for food acquisition. Our approach captures food types and physical properties (e.g., solid, semi-solid, granular, liquid, and mixture), models temporal dynamics of acquisition actions, and introduces geometric information to determine optimal scooping points and assess bowl fullness. IMRL enables IL to adaptively adjust scooping strategies based on context, improving the robot's capability to handle diverse food acquisition scenarios. Experiments on a real robot demonstrate our approach's robustness and adaptability across various foods and bowl configurations, including zero-shot generalization to unseen settings. Our approach achieves improvement up to $35\%$ in success rate compared with the best-performing baseline.
NAVINACT: Combining Navigation and Imitation Learning for Bootstrapping Reinforcement Learning
Aug 07, 2024Reinforcement Learning (RL) has shown remarkable progress in simulation environments, yet its application to real-world robotic tasks remains limited due to challenges in exploration and generalisation. To address these issues, we introduce NAVINACT, a framework that chooses when the robot should use classical motion planning-based navigation and when it should learn a policy. To further improve the efficiency in exploration, we use imitation data to bootstrap the exploration. NAVINACT dynamically switches between two modes of operation: navigating to a waypoint using classical techniques when away from the objects and reinforcement learning for fine-grained manipulation control when about to interact with objects. NAVINACT consists of a multi-head architecture composed of ModeNet for mode classification, NavNet for waypoint prediction, and InteractNet for precise manipulation. By combining the strengths of RL and Imitation Learning (IL), NAVINACT improves sample efficiency and mitigates distribution shift, ensuring robust task execution. We evaluate our approach across multiple challenging simulation environments and real-world tasks, demonstrating superior performance in terms of adaptability, efficiency, and generalization compared to existing methods. In both simulated and real-world settings, NAVINACT demonstrates robust performance. In simulations, NAVINACT surpasses baseline methods by 10-15\% in training success rates at 30k samples and by 30-40\% during evaluation phases. In real-world scenarios, it demonstrates a 30-40\% higher success rate on simpler tasks compared to baselines and uniquely succeeds in complex, two-stage manipulation tasks. Datasets and supplementary materials can be found on our website: {https://raaslab.org/projects/NAVINACT/}.
LAVA: Long-horizon Visual Action based Food Acquisition
Mar 19, 2024



Robotic Assisted Feeding (RAF) addresses the fundamental need for individuals with mobility impairments to regain autonomy in feeding themselves. The goal of RAF is to use a robot arm to acquire and transfer food to individuals from the table. Existing RAF methods primarily focus on solid foods, leaving a gap in manipulation strategies for semi-solid and deformable foods. This study introduces Long-horizon Visual Action (LAVA) based food acquisition of liquid, semisolid, and deformable foods. Long-horizon refers to the goal of "clearing the bowl" by sequentially acquiring the food from the bowl. LAVA employs a hierarchical policy for long-horizon food acquisition tasks. The framework uses high-level policy to determine primitives by leveraging ScoopNet. At the mid-level, LAVA finds parameters for primitives using vision. To carry out sequential plans in the real world, LAVA delegates action execution which is driven by Low-level policy that uses parameters received from mid-level policy and behavior cloning ensuring precise trajectory execution. We validate our approach on complex real-world acquisition trials involving granular, liquid, semisolid, and deformable food types along with fruit chunks and soup acquisition. Across 46 bowls, LAVA acquires much more efficiently than baselines with a success rate of 89 +/- 4% and generalizes across realistic plate variations such as different positions, varieties, and amount of food in the bowl. Code, datasets, videos, and supplementary materials can be found on our website.
Adaptive Visual Imitation Learning for Robotic Assisted Feeding Across Varied Bowl Configurations and Food Types
Mar 19, 2024



In this study, we introduce a novel visual imitation network with a spatial attention module for robotic assisted feeding (RAF). The goal is to acquire (i.e., scoop) food items from a bowl. However, achieving robust and adaptive food manipulation is particularly challenging. To deal with this, we propose a framework that integrates visual perception with imitation learning to enable the robot to handle diverse scenarios during scooping. Our approach, named AVIL (adaptive visual imitation learning), exhibits adaptability and robustness across different bowl configurations in terms of material, size, and position, as well as diverse food types including granular, semi-solid, and liquid, even in the presence of distractors. We validate the effectiveness of our approach by conducting experiments on a real robot. We also compare its performance with a baseline. The results demonstrate improvement over the baseline across all scenarios, with an enhancement of up to 2.5 times in terms of a success metric. Notably, our model, trained solely on data from a transparent glass bowl containing granular cereals, showcases generalization ability when tested zero-shot on other bowl configurations with different types of food.
REBEL: A Regularization-Based Solution for Reward Overoptimization in Reinforcement Learning from Human Feedback
Dec 22, 2023



In this work, we propose REBEL, an algorithm for sample efficient reward regularization based robotic reinforcement learning from human feedback (RRLHF). Reinforcement learning (RL) performance for continuous control robotics tasks is sensitive to the underlying reward function. In practice, the reward function often ends up misaligned with human intent, values, social norms, etc., leading to catastrophic failures in the real world. We leverage human preferences to learn regularized reward functions and eventually align the agents with the true intended behavior. We introduce a novel notion of reward regularization to the existing RRLHF framework, which is termed as agent preferences. So, we not only consider human feedback in terms of preferences, we also propose to take into account the preference of the underlying RL agent while learning the reward function. We show that this helps to improve the over-optimization associated with the design of reward functions in RL. We experimentally show that REBEL exhibits up to 70% improvement in sample efficiency to achieve a similar level of episodic reward returns as compared to the state-of-the-art methods such as PEBBLE and PEBBLE+SURF.
AG-CVG: Coverage Planning with a Mobile Recharging UGV and an Energy-Constrained UAV
Oct 11, 2023



In this paper, we present an approach for coverage path planning for a team of an energy-constrained Unmanned Aerial Vehicle (UAV) and an Unmanned Ground Vehicle (UGV). Both the UAV and the UGV have predefined areas that they have to cover. The goal is to perform complete coverage by both robots while minimizing the coverage time. The UGV can also serve as a mobile recharging station. The UAV and UGV need to occasionally rendezvous for recharging. We propose a heuristic method to address this NP-Hard planning problem. Our approach involves initially determining coverage paths without factoring in energy constraints. Subsequently, we cluster segments of these paths and employ graph matching to assign UAV clusters to UGV clusters for efficient recharging management. We perform numerical analysis on real-world coverage applications and show that compared with a greedy approach our method reduces rendezvous overhead on average by 11.33\%. We demonstrate proof-of-concept with a team of a VOXL m500 drone and a Clearpath Jackal ground vehicle, providing a complete system from the offline algorithm to the field execution.