 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Search for Sparsely Distributed Visual Phenomena through Environmental Context Modeling
Mar 10, 2026Autonomous underwater vehicles (AUVs) are increasingly used to survey coral reefs, yet efficiently locating specific coral species of interest remains difficult: target species are often sparsely distributed across the reef, and an AUV with limited battery life cannot afford to search everywhere. When detections of the target itself are too sparse to provide directional guidance, the robot benefits from an additional signal to decide where to look next. We propose using the visual environmental context -- the habitat features that tend to co-occur with a target species -- as that signal. Because context features are spatially denser and often vary more smoothly than target detections, we hypothesize that a reward function targeted at broader environmental context will enable adaptive planners to make better decisions on where to go next, even in regions where no target has yet been observed. Starting from a single labeled image, our method uses patch-level DINOv2 embeddings to perform one-shot detections of both the target species and its surrounding context online. We validate our approach using real imagery collected by an AUV at two reef sites in St. John, U.S. Virgin Islands, simulating the robot's motion offline. Our results demonstrate that one-shot detection combined with adaptive context modeling enables efficient autonomous surveying, sampling up to 75$\%$ of the target in roughly half the time required by exhaustive coverage when the target is sparsely distributed, and outperforming search strategies that only use target detections.
AG-CVG: Coverage Planning with a Mobile Recharging UGV and an Energy-Constrained UAV
Oct 11, 2023



In this paper, we present an approach for coverage path planning for a team of an energy-constrained Unmanned Aerial Vehicle (UAV) and an Unmanned Ground Vehicle (UGV). Both the UAV and the UGV have predefined areas that they have to cover. The goal is to perform complete coverage by both robots while minimizing the coverage time. The UGV can also serve as a mobile recharging station. The UAV and UGV need to occasionally rendezvous for recharging. We propose a heuristic method to address this NP-Hard planning problem. Our approach involves initially determining coverage paths without factoring in energy constraints. Subsequently, we cluster segments of these paths and employ graph matching to assign UAV clusters to UGV clusters for efficient recharging management. We perform numerical analysis on real-world coverage applications and show that compared with a greedy approach our method reduces rendezvous overhead on average by 11.33\%. We demonstrate proof-of-concept with a team of a VOXL m500 drone and a Clearpath Jackal ground vehicle, providing a complete system from the offline algorithm to the field execution.
Decision-Oriented Intervention Cost Prediction for Multi-robot Persistent Monitoring
Oct 02, 2023
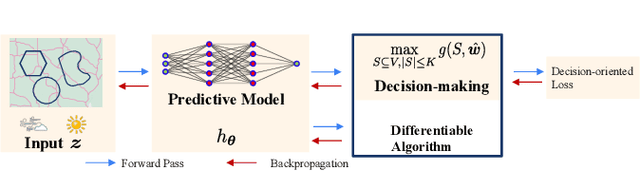

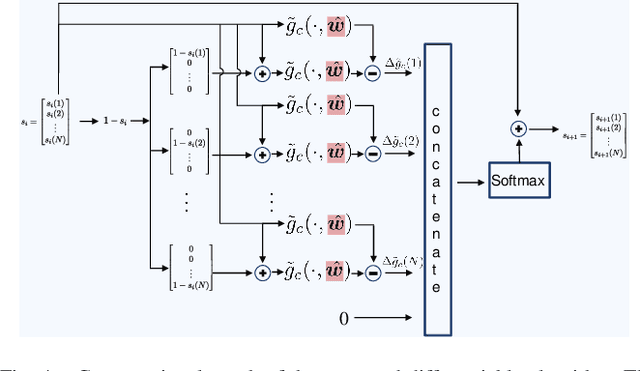
In this paper, we present a differentiable, decision-oriented learning technique for a class of vehicle routing problems. Specifically, we consider a scenario where a team of Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs) are persistently monitoring an environment. The UGVs are occasionally taken over by humans to take detours to recharge the depleted UAVs. The goal is to select routes for the UGVs so that they can efficiently monitor the environment while reducing the cost of interventions. The former is modeled as a monotone, submodular function whereas the latter is a linear function of the routes of the UGVs. We consider a scenario where the former is known but the latter depends on the context (e.g., wind and terrain conditions) that must be learned. Typically, we first learn to predict the cost function and then solve the optimization problem. However, the loss function used in prediction may be misaligned with our final goal of finding good routes. We propose a \emph{decision-oriented learning} framework that incorporates task optimization as a differentiable layer in the prediction phase. To make the task optimization (which is a non-monotone submodular function) differentiable, we propose the Differentiable Cost Scaled Greedy algorithm. We demonstrate the efficacy of the proposed framework through numerical simulations. The results show that the proposed framework can result in better performance than the traditional approach.
UIVNAV: Underwater Information-driven Vision-based Navigation via Imitation Learning
Sep 15, 2023Autonomous navigation in the underwater environment is challenging due to limited visibility, dynamic changes, and the lack of a cost-efficient accurate localization system. We introduce UIVNav, a novel end-to-end underwater navigation solution designed to drive robots over Objects of Interest (OOI) while avoiding obstacles, without relying on localization. UIVNav uses imitation learning and is inspired by the navigation strategies used by human divers who do not rely on localization. UIVNav consists of the following phases: (1) generating an intermediate representation (IR), and (2) training the navigation policy based on human-labeled IR. By training the navigation policy on IR instead of raw data, the second phase is domain-invariant -- the navigation policy does not need to be retrained if the domain or the OOI changes. We show this by deploying the same navigation policy for surveying two different OOIs, oyster and rock reefs, in two different domains, simulation, and a real pool. We compared our method with complete coverage and random walk methods which showed that our method is more efficient in gathering information for OOIs while also avoiding obstacles. The results show that UIVNav chooses to visit the areas with larger area sizes of oysters or rocks with no prior information about the environment or localization. Moreover, a robot using UIVNav compared to complete coverage method surveys on average 36% more oysters when traveling the same distances. We also demonstrate the feasibility of real-time deployment of UIVNavin pool experiments with BlueROV underwater robot for surveying a bed of oyster shells.
Whale Detection Enhancement through Synthetic Satellite Images
Aug 15, 2023
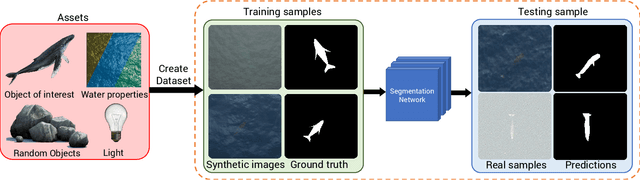
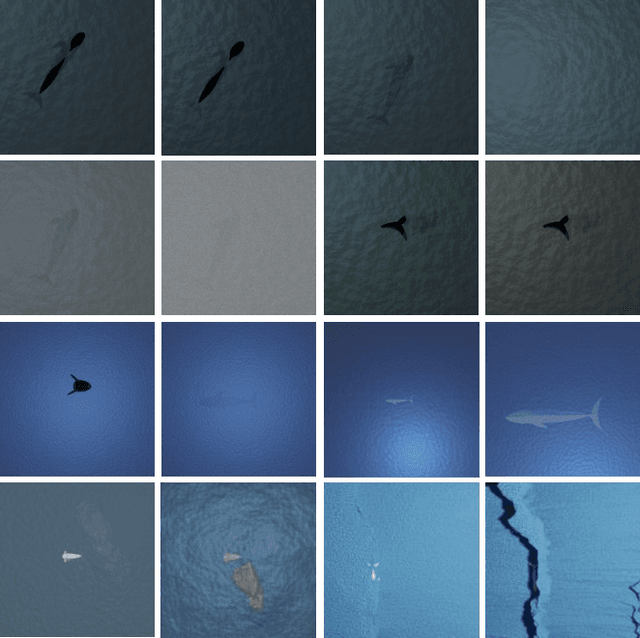

With a number of marine populations in rapid decline, collecting and analyzing data about marine populations has become increasingly important to develop effective conservation policies for a wide range of marine animals, including whales. Modern computer vision algorithms allow us to detect whales in images in a wide range of domains, further speeding up and enhancing the monitoring process. However, these algorithms heavily rely on large training datasets, which are challenging and time-consuming to collect particularly in marine or aquatic environments. Recent advances in AI however have made it possible to synthetically create datasets for training machine learning algorithms, thus enabling new solutions that were not possible before. In this work, we present a solution - SeaDroneSim2 benchmark suite, which addresses this challenge by generating aerial, and satellite synthetic image datasets to improve the detection of whales and reduce the effort required for training data collection. We show that we can achieve a 15% performance boost on whale detection compared to using the real data alone for training, by augmenting a 10% real data. We open source both the code of the simulation platform SeaDroneSim2 and the dataset generated through it.
ChatSim: Underwater Simulation with Natural Language Prompting
Aug 09, 2023Robots are becoming an essential part of many operations including marine exploration or environmental monitoring. However, the underwater environment presents many challenges, including high pressure, limited visibility, and harsh conditions that can damage equipment. Real-world experimentation can be expensive and difficult to execute. Therefore, it is essential to simulate the performance of underwater robots in comparable environments to ensure their optimal functionality within practical real-world contexts.OysterSim generates photo-realistic images and segmentation masks of objects in marine environments, providing valuable training data for underwater computer vision applications. By integrating ChatGPT into underwater simulations, users can convey their thoughts effortlessly and intuitively create desired underwater environments without intricate coding. \invis{Moreover, researchers can realize substantial time and cost savings by evaluating their algorithms across diverse underwater conditions in the simulation.} The objective of ChatSim is to integrate Large Language Models (LLM) with a simulation environment~(OysterSim), enabling direct control of the simulated environment via natural language input. This advancement can greatly enhance the capabilities of underwater simulation, with far-reaching benefits for marine exploration and broader scientific research endeavors.
OysterSim: Underwater Simulation for Enhancing Oyster Reef Monitoring
Sep 20, 2022
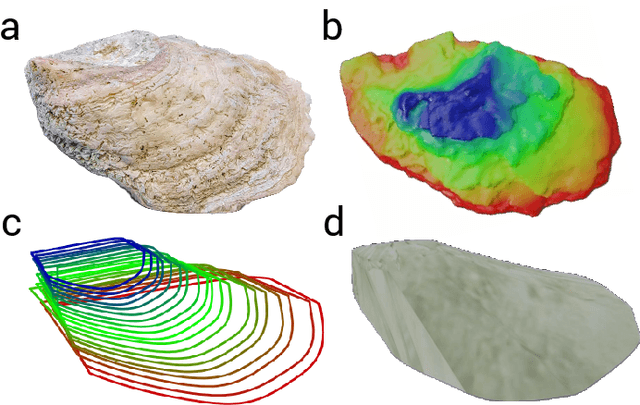

Oysters are the living vacuum cleaners of the oceans. There is an exponential decline in the oyster population due to over-harvesting. With the current development of the automation and AI, robots are becoming an integral part of the environmental monitoring process that can be also utilized for oyster reef preservation. Nevertheless, the underwater environment poses many difficulties, both from the practical - dangerous and time consuming operations, and the technical perspectives - distorted perception and unreliable navigation. To this end, we present a simulated environment that can be used to improve oyster reef monitoring. The simulated environment can be used to create photo-realistic image datasets with multiple sensor data and ground truth location of a remotely operated vehicle(ROV). Currently, there are no photo-realistic image datasets for oyster reef monitoring. Thus, we want to provide a new benchmark suite to the underwater community.
OysterNet: Enhanced Oyster Detection Using Simulation
Sep 16, 2022
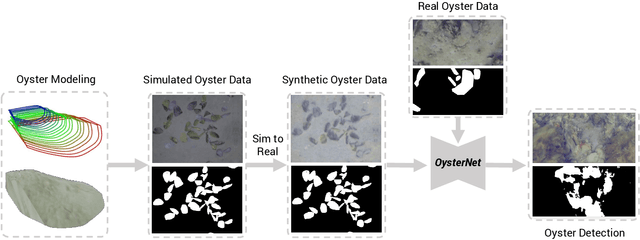

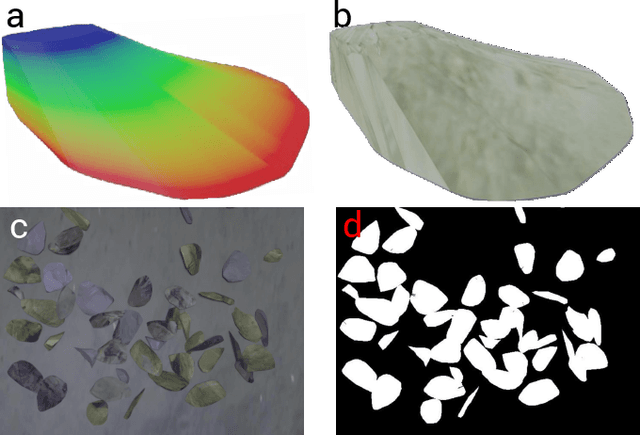
Oysters play a pivotal role in the bay living ecosystem and are considered the living filters for the ocean. In recent years, oyster reefs have undergone major devastation caused by commercial over-harvesting, requiring preservation to maintain ecological balance. The foundation of this preservation is to estimate the oyster density which requires accurate oyster detection. However, systems for accurate oyster detection require large datasets obtaining which is an expensive and labor-intensive task in underwater environments. To this end, we present a novel method to mathematically model oysters and render images of oysters in simulation to boost the detection performance with minimal real data. Utilizing our synthetic data along with real data for oyster detection, we obtain up to 35.1% boost in performance as compared to using only real data with our OysterNet network. We also improve the state-of-the-art by 12.7%. This shows that using underlying geometrical properties of objects can help to enhance recognition task accuracy on limited datasets successfully and we hope more researchers adopt such a strategy for hard-to-obtain datasets.
Risk-aware Resource Allocation for Multiple UAVs-UGVs Recharging Rendezvous
Sep 13, 2022

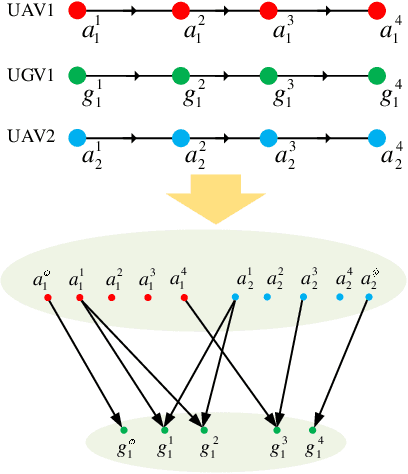
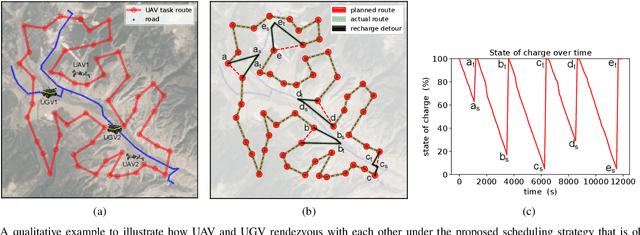
We study a resource allocation problem for the cooperative aerial-ground vehicle routing application, in which multiple Unmanned Aerial Vehicles (UAVs) with limited battery capacity and multiple Unmanned Ground Vehicles (UGVs) that can also act as a mobile recharging stations need to jointly accomplish a mission such as persistently monitoring a set of points. Due to the limited battery capacity of the UAVs, they sometimes have to deviate from their task to rendezvous with the UGVs and get recharged. Each UGV can serve a limited number of UAVs at a time. In contrast to prior work on deterministic multi-robot scheduling, we consider the challenge imposed by the stochasticity of the energy consumption of the UAV. We are interested in finding the optimal recharging schedule of the UAVs such that the travel cost is minimized and the probability that no UAV runs out of charge within the planning horizon is greater than a user-defined tolerance. We formulate this problem ({Risk-aware Recharging Rendezvous Problem (RRRP))} as an Integer Linear Program (ILP), in which the matching constraint captures the resource availability constraints and the knapsack constraint captures the success probability constraints. We propose a bicriteria approximation algorithm to solve RRRP. We demonstrate the effectiveness of our formulation and algorithm in the context of one persistent monitoring mission.
HTRON:Efficient Outdoor Navigation with Sparse Rewards via Heavy Tailed Adaptive Reinforce Algorithm
Jul 08, 2022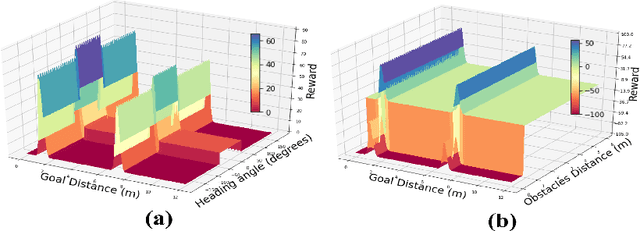
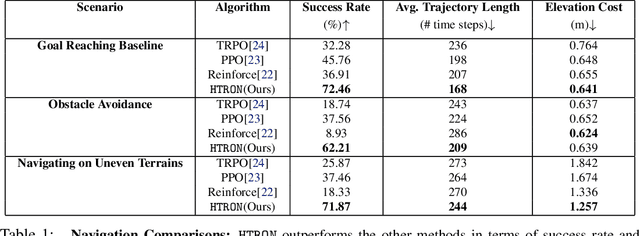
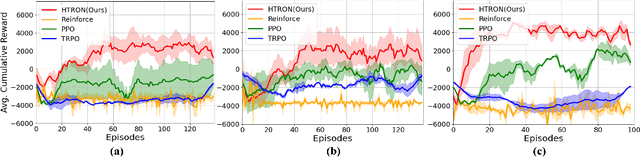
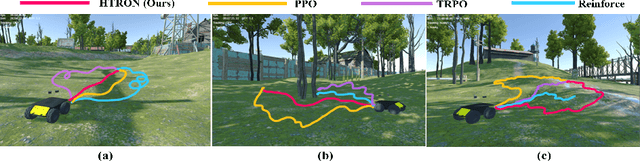
We present a novel approach to improve the performance of deep reinforcement learning (DRL) based outdoor robot navigation systems. Most, existing DRL methods are based on carefully designed dense reward functions that learn the efficient behavior in an environment. We circumvent this issue by working only with sparse rewards (which are easy to design), and propose a novel adaptive Heavy-Tailed Reinforce algorithm for Outdoor Navigation called HTRON. Our main idea is to utilize heavy-tailed policy parametrizations which implicitly induce exploration in sparse reward settings. We evaluate the performance of HTRON against Reinforce, PPO and TRPO algorithms in three different outdoor scenarios: goal-reaching, obstacle avoidance, and uneven terrain navigation. We observe in average an increase of 34.41% in terms of success rate, a 15.15% decrease in the average time steps taken to reach the goal, and a 24.9% decrease in the elevation cost compared to the navigation policies obtained by the other methods. Further, we demonstrate that our algorithm can be transferred directly into a Clearpath Husky robot to perform outdoor terrain navigation in real-world scenarios.