 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGLAMP: Knowledge Graph-guided Language model for Adaptive Multi-robot Planning and Replanning
Feb 04, 2026Heterogeneous multi-robot systems are increasingly deployed in long-horizon missions that require coordination among robots with diverse capabilities. However, existing planning approaches struggle to construct accurate symbolic representations and maintain plan consistency in dynamic environments. Classical PDDL planners require manually crafted symbolic models, while LLM-based planners often ignore agent heterogeneity and environmental uncertainty. We introduce KGLAMP, a knowledge-graph-guided LLM planning framework for heterogeneous multi-robot teams. The framework maintains a structured knowledge graph encoding object relations, spatial reachability, and robot capabilities, which guides the LLM in generating accurate PDDL problem specifications. The knowledge graph serves as a persistent, dynamically updated memory that incorporates new observations and triggers replanning upon detecting inconsistencies, enabling symbolic plans to adapt to evolving world states. Experiments on the MAT-THOR benchmark show that KGLAMP improves performance by at least 25.5% over both LLM-only and PDDL-based variants.
Multi-Agent Trust Region Policy Optimisation: A Joint Constraint Approach
Aug 14, 2025Multi-agent reinforcement learning (MARL) requires coordinated and stable policy updates among interacting agents. Heterogeneous-Agent Trust Region Policy Optimization (HATRPO) enforces per-agent trust region constraints using Kullback-Leibler (KL) divergence to stabilize training. However, assigning each agent the same KL threshold can lead to slow and locally optimal updates, especially in heterogeneous settings. To address this limitation, we propose two approaches for allocating the KL divergence threshold across agents: HATRPO-W, a Karush-Kuhn-Tucker-based (KKT-based) method that optimizes threshold assignment under global KL constraints, and HATRPO-G, a greedy algorithm that prioritizes agents based on improvement-to-divergence ratio. By connecting sequential policy optimization with constrained threshold scheduling, our approach enables more flexible and effective learning in heterogeneous-agent settings. Experimental results demonstrate that our methods significantly boost the performance of HATRPO, achieving faster convergence and higher final rewards across diverse MARL benchmarks. Specifically, HATRPO-W and HATRPO-G achieve comparable improvements in final performance, each exceeding 22.5%. Notably, HATRPO-W also demonstrates more stable learning dynamics, as reflected by its lower variance.
Learning Multi-Robot Coordination through Locality-Based Factorized Multi-Agent Actor-Critic Algorithm
Mar 24, 2025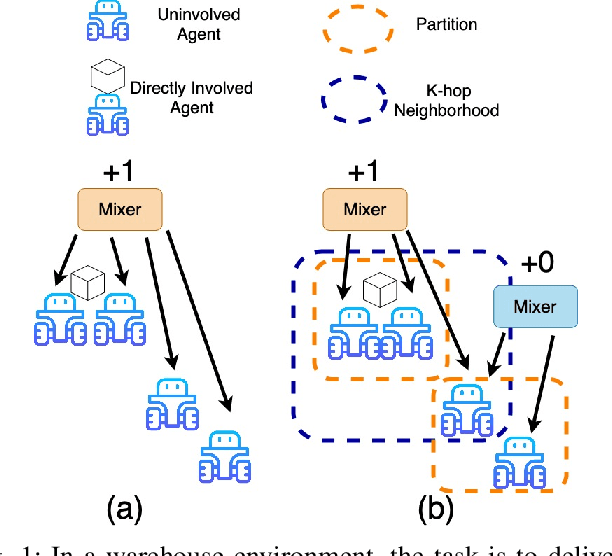
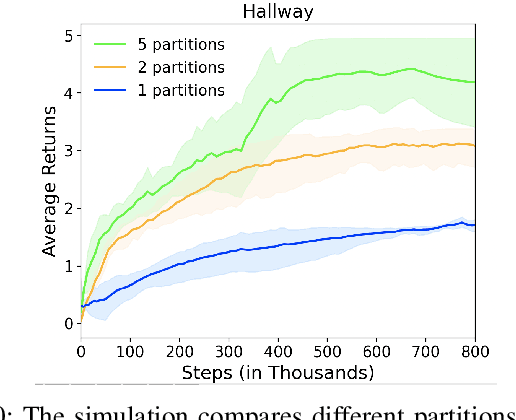
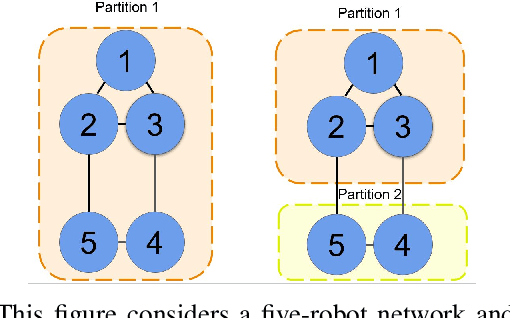
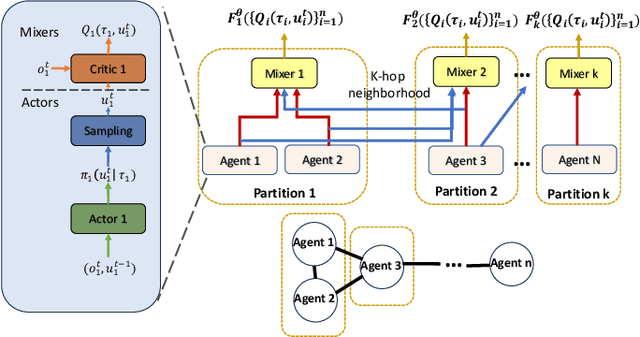
In this work, we present a novel cooperative multi-agent reinforcement learning method called \textbf{Loc}ality based \textbf{Fac}torized \textbf{M}ulti-Agent \textbf{A}ctor-\textbf{C}ritic (Loc-FACMAC). Existing state-of-the-art algorithms, such as FACMAC, rely on global reward information, which may not accurately reflect the quality of individual robots' actions in decentralized systems. We integrate the concept of locality into critic learning, where strongly related robots form partitions during training. Robots within the same partition have a greater impact on each other, leading to more precise policy evaluation. Additionally, we construct a dependency graph to capture the relationships between robots, facilitating the partitioning process. This approach mitigates the curse of dimensionality and prevents robots from using irrelevant information. Our method improves existing algorithms by focusing on local rewards and leveraging partition-based learning to enhance training efficiency and performance. We evaluate the performance of Loc-FACMAC in three environments: Hallway, Multi-cartpole, and Bounded-Cooperative-Navigation. We explore the impact of partition sizes on the performance and compare the result with baseline MARL algorithms such as LOMAQ, FACMAC, and QMIX. The experiments reveal that, if the locality structure is defined properly, Loc-FACMAC outperforms these baseline algorithms up to 108\%, indicating that exploiting the locality structure in the actor-critic framework improves the MARL performance.
Option Discovery Using LLM-guided Semantic Hierarchical Reinforcement Learning
Mar 24, 2025



Large Language Models (LLMs) have shown remarkable promise in reasoning and decision-making, yet their integration with Reinforcement Learning (RL) for complex robotic tasks remains underexplored. In this paper, we propose an LLM-guided hierarchical RL framework, termed LDSC, that leverages LLM-driven subgoal selection and option reuse to enhance sample efficiency, generalization, and multi-task adaptability. Traditional RL methods often suffer from inefficient exploration and high computational cost. Hierarchical RL helps with these challenges, but existing methods often fail to reuse options effectively when faced with new tasks. To address these limitations, we introduce a three-stage framework that uses LLMs for subgoal generation given natural language description of the task, a reusable option learning and selection method, and an action-level policy, enabling more effective decision-making across diverse tasks. By incorporating LLMs for subgoal prediction and policy guidance, our approach improves exploration efficiency and enhances learning performance. On average, LDSC outperforms the baseline by 55.9\% in average reward, demonstrating its effectiveness in complex RL settings. More details and experiment videos could be found in \href{https://raaslab.org/projects/LDSC/}{this link\footnote{https://raaslab.org/projects/LDSC}}.
When to Localize? A Risk-Constrained Reinforcement Learning Approach
Nov 05, 2024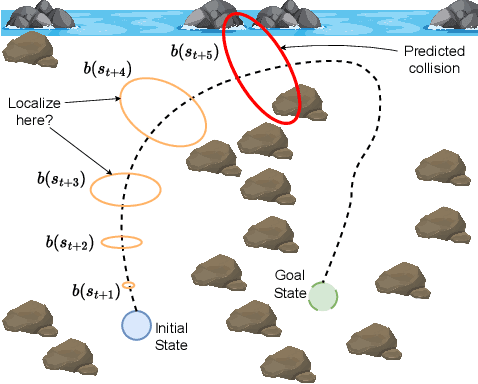
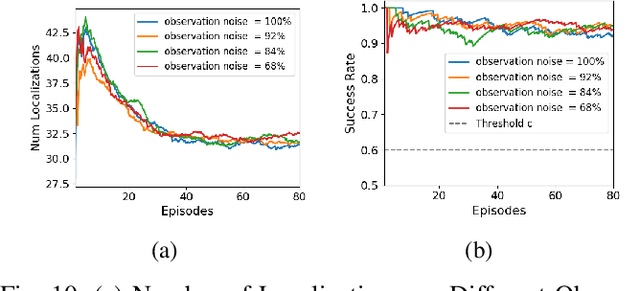
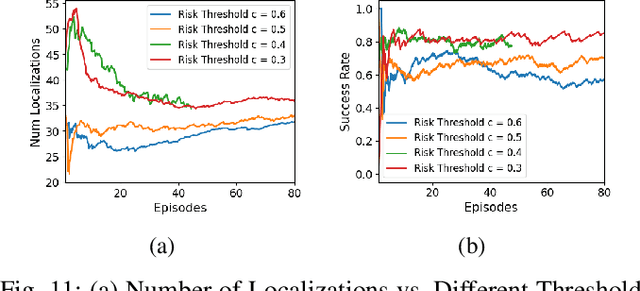
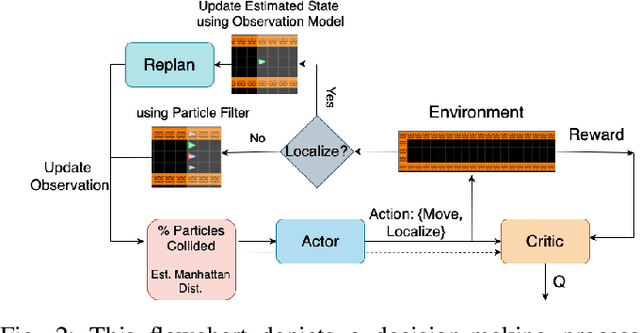
In a standard navigation pipeline, a robot localizes at every time step to lower navigational errors. However, in some scenarios, a robot needs to selectively localize when it is expensive to obtain observations. For example, an underwater robot surfacing to localize too often hinders it from searching for critical items underwater, such as black boxes from crashed aircraft. On the other hand, if the robot never localizes, poor state estimates cause failure to find the items due to inadvertently leaving the search area or entering hazardous, restricted areas. Motivated by these scenarios, we investigate approaches to help a robot determine "when to localize?" We formulate this as a bi-criteria optimization problem: minimize the number of localization actions while ensuring the probability of failure (due to collision or not reaching a desired goal) remains bounded. In recent work, we showed how to formulate this active localization problem as a constrained Partially Observable Markov Decision Process (POMDP), which was solved using an online POMDP solver. However, this approach is too slow and requires full knowledge of the robot transition and observation models. In this paper, we present RiskRL, a constrained Reinforcement Learning (RL) framework that overcomes these limitations. RiskRL uses particle filtering and recurrent Soft Actor-Critic network to learn a policy that minimizes the number of localizations while ensuring the probability of failure constraint is met. Our numerical experiments show that RiskRL learns a robust policy that outperforms the baseline by at least 13% while also generalizing to unseen environments.
Decision-Oriented Intervention Cost Prediction for Multi-robot Persistent Monitoring
Oct 02, 2023
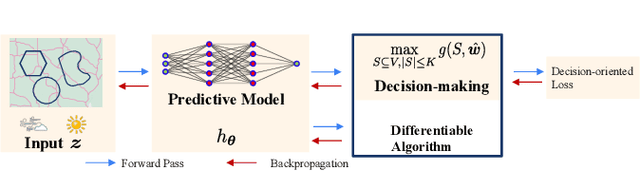

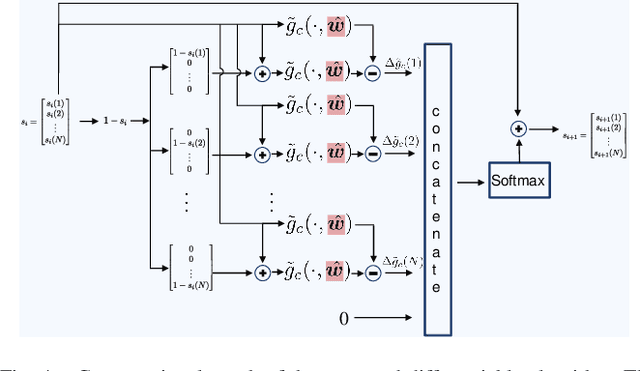
In this paper, we present a differentiable, decision-oriented learning technique for a class of vehicle routing problems. Specifically, we consider a scenario where a team of Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs) are persistently monitoring an environment. The UGVs are occasionally taken over by humans to take detours to recharge the depleted UAVs. The goal is to select routes for the UGVs so that they can efficiently monitor the environment while reducing the cost of interventions. The former is modeled as a monotone, submodular function whereas the latter is a linear function of the routes of the UGVs. We consider a scenario where the former is known but the latter depends on the context (e.g., wind and terrain conditions) that must be learned. Typically, we first learn to predict the cost function and then solve the optimization problem. However, the loss function used in prediction may be misaligned with our final goal of finding good routes. We propose a \emph{decision-oriented learning} framework that incorporates task optimization as a differentiable layer in the prediction phase. To make the task optimization (which is a non-monotone submodular function) differentiable, we propose the Differentiable Cost Scaled Greedy algorithm. We demonstrate the efficacy of the proposed framework through numerical simulations. The results show that the proposed framework can result in better performance than the traditional approach.
LANCAR: Leveraging Language for Context-Aware Robot Locomotion in Unstructured Environments
Sep 30, 2023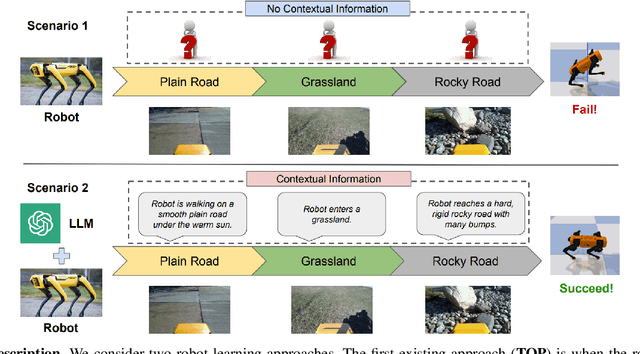
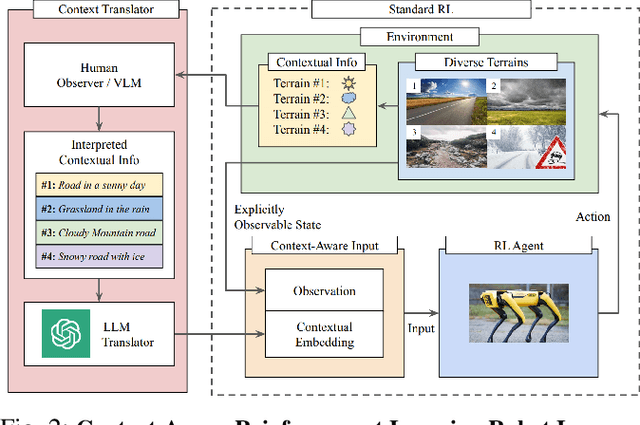
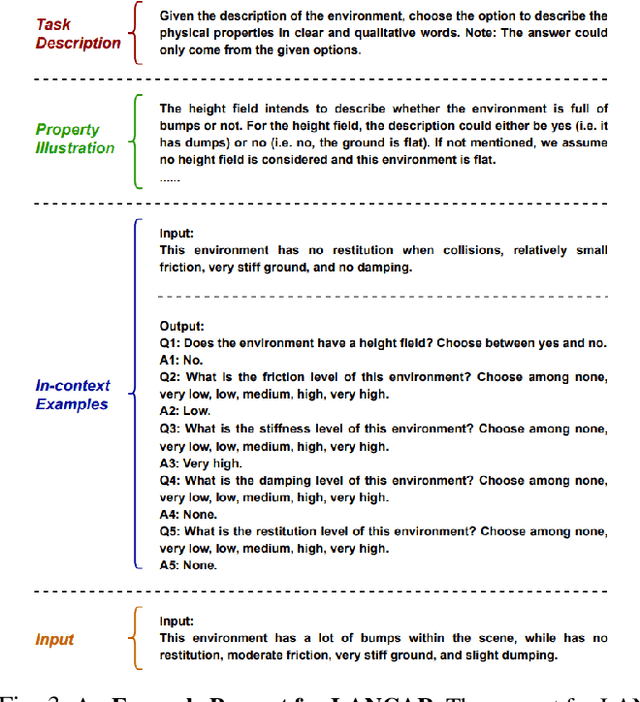

Robotic locomotion is a challenging task, especially in unstructured terrains. In practice, the optimal locomotion policy can be context-dependent by using the contextual information of encountered terrains in decision-making. Humans can interpret the environmental context for robots, but the ambiguity of human language makes it challenging to use in robot locomotion directly. In this paper, we propose a novel approach, LANCAR, that introduces a context translator that works with reinforcement learning (RL) agents for context-aware locomotion. Our formulation allows a robot to interpret the contextual information from environments generated by human observers or Vision-Language Models (VLM) with Large Language Models (LLM) and use this information to generate contextual embeddings. We incorporate the contextual embeddings with the robot's internal environmental observations as the input to the RL agent's decision neural network. We evaluate LANCAR with contextual information in varying ambiguity levels and compare its performance using several alternative approaches. Our experimental results demonstrate that our approach exhibits good generalizability and adaptability across diverse terrains, by achieving at least 10% of performance improvement in episodic reward over baselines. The experiment video can be found at the following link: https://raaslab.org/projects/LLM_Context_Estimation/.
Where to Drop Sensors from Aerial Robots to Monitor a Surface-Level Phenomenon?
Jul 10, 2023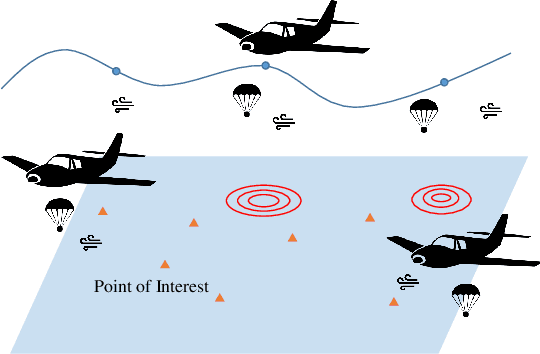
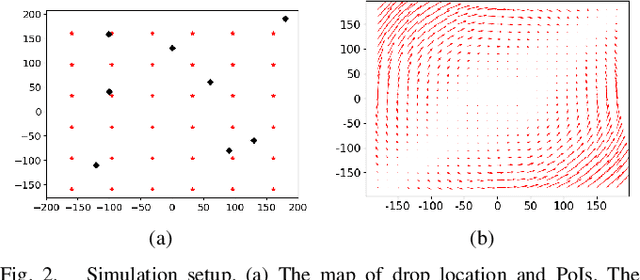
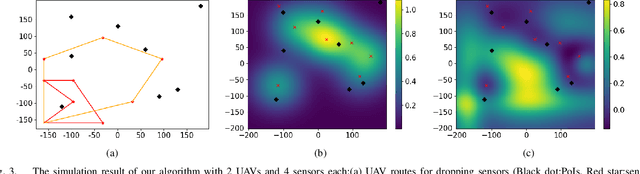
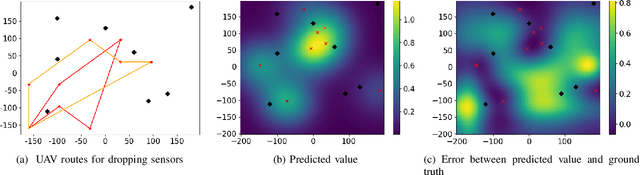
We consider the problem of routing a team of energy-constrained Unmanned Aerial Vehicles (UAVs) to drop unmovable sensors for monitoring a task area in the presence of stochastic wind disturbances. In prior work on mobile sensor routing problems, sensors and their carrier are one integrated platform, and sensors are assumed to be able to take measurements at exactly desired locations. By contrast, airdropping the sensors onto the ground can introduce stochasticity in the landing locations of the sensors. We focus on addressing this stochasticity in sensor locations from the path-planning perspective. Specifically, we formulate the problem (Multi-UAV Sensor Drop) as a variant of the Submodular Team Orienteering Problem with one additional constraint on the number of sensors on each UAV. The objective is to maximize the Mutual Information between the phenomenon at Points of Interest (PoIs) and the measurements that sensors will take at stochastic locations. We show that such an objective is computationally expensive to evaluate. To tackle this challenge, we propose a surrogate objective with a closed-form expression based on the expected mean and expected covariance of the Gaussian Process. We propose a heuristic algorithm to solve the optimization problem with the surrogate objective. The formulation and the algorithms are validated through extensive simulations.