 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWESPR: Wind-adaptive Energy-Efficient Safe Perception & Planning for Robust Flight with Quadrotors
Mar 10, 2026Local wind conditions strongly influence drone performance: headwinds increase flight time, crosswinds and wind shear hinder agility in cluttered spaces, while tailwinds reduce travel time. Although adaptive controllers can mitigate turbulence, they remain unaware of the surrounding geometry that generates it, preventing proactive avoidance. Existing methods that model how wind interacts with the environment typically rely on computationally expensive fluid dynamics simulations, limiting real-time adaptation to new environments and conditions. To bridge this gap, we present WESPR, a fast framework that predicts how environmental geometry affects local wind conditions, enabling proactive path planning and control adaptation. Our lightweight pipeline integrates geometric perception and local weather data to estimate wind fields, compute cost-efficient paths, and adjust control strategies-all within 10 seconds. We validate WESPR on a Crazyflie drone navigating turbulent obstacle courses. Our results show a 12.5-58.7% reduction in maximum trajectory deviation and a 24.6% improvement in stability compared to a wind-agnostic adaptive controller.
When to Localize? A POMDP Approach
Nov 13, 2024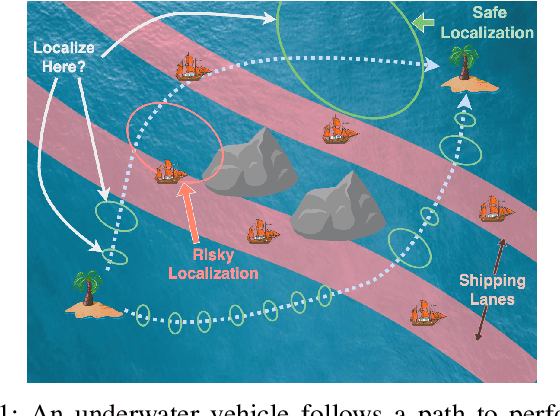
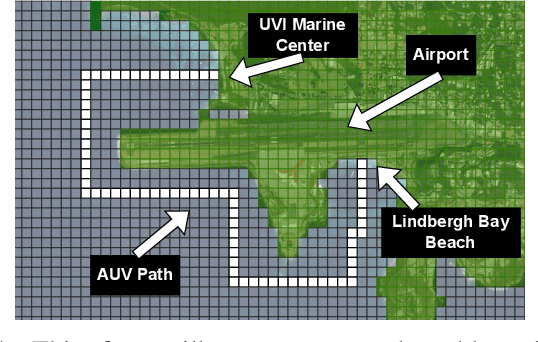
Robots often localize to lower navigational errors and facilitate downstream, high-level tasks. However, a robot may want to selectively localize when localization is costly (such as with resource-constrained robots) or inefficient (for example, submersibles that need to surface), especially when navigating in environments with variable numbers of hazards such as obstacles and shipping lanes. In this study, we propose a method that helps a robot determine ``when to localize'' to 1) minimize such actions and 2) not exceed the probability of failure (such as surfacing within high-traffic shipping lanes). We formulate our method as a Constrained Partially Observable Markov Decision Process and use the Cost-Constrained POMCP solver to plan the robot's actions. The solver simulates failure probabilities to decide if a robot moves to its goal or localizes to prevent failure. We performed numerical experiments with multiple baselines.
When to Localize? A Risk-Constrained Reinforcement Learning Approach
Nov 05, 2024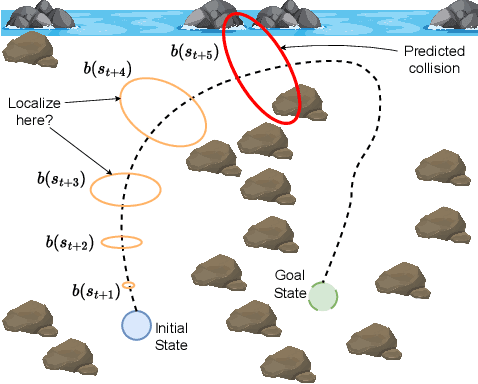
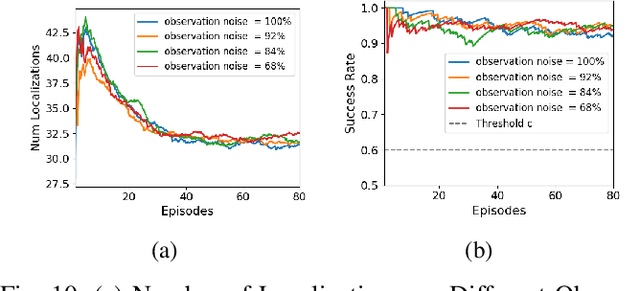
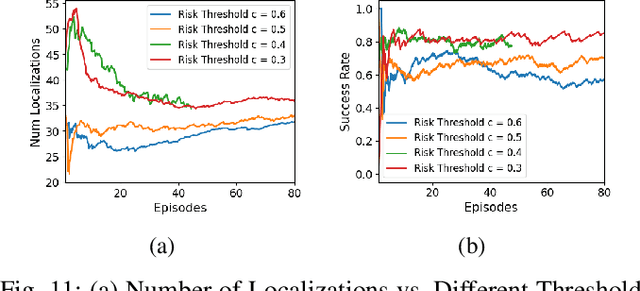
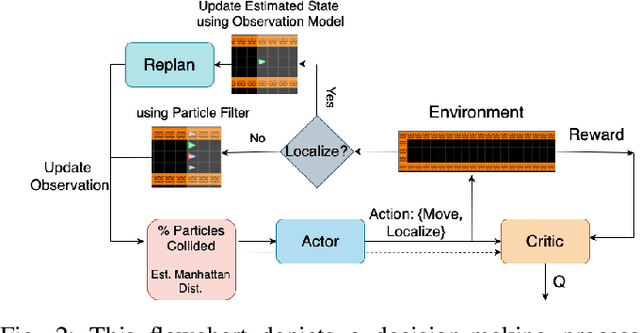
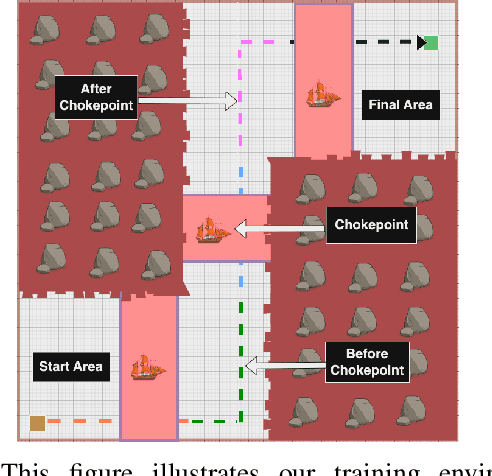
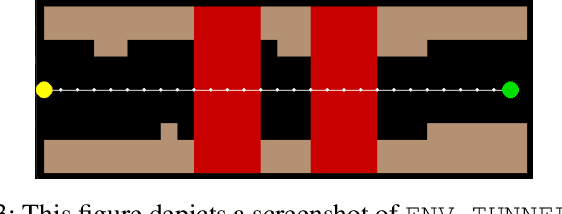
In a standard navigation pipeline, a robot localizes at every time step to lower navigational errors. However, in some scenarios, a robot needs to selectively localize when it is expensive to obtain observations. For example, an underwater robot surfacing to localize too often hinders it from searching for critical items underwater, such as black boxes from crashed aircraft. On the other hand, if the robot never localizes, poor state estimates cause failure to find the items due to inadvertently leaving the search area or entering hazardous, restricted areas. Motivated by these scenarios, we investigate approaches to help a robot determine "when to localize?" We formulate this as a bi-criteria optimization problem: minimize the number of localization actions while ensuring the probability of failure (due to collision or not reaching a desired goal) remains bounded. In recent work, we showed how to formulate this active localization problem as a constrained Partially Observable Markov Decision Process (POMDP), which was solved using an online POMDP solver. However, this approach is too slow and requires full knowledge of the robot transition and observation models. In this paper, we present RiskRL, a constrained Reinforcement Learning (RL) framework that overcomes these limitations. RiskRL uses particle filtering and recurrent Soft Actor-Critic network to learn a policy that minimizes the number of localizations while ensuring the probability of failure constraint is met. Our numerical experiments show that RiskRL learns a robust policy that outperforms the baseline by at least 13% while also generalizing to unseen environments.
Dynamically Finding Optimal Observer States to Minimize Localization Error with Complex State-Dependent Noise
Nov 30, 2022



We present DyFOS, an active perception method that Dynamically Finds Optimal States to minimize localization error while avoiding obstacles and occlusions. We consider the scenario where a ground target without any exteroceptive sensors must rely on an aerial observer for pose and uncertainty estimates to localize itself along an obstacle-filled path. The observer uses a downward-facing camera to estimate the target's pose and uncertainty. However, the pose uncertainty is a function of the states of the observer, target, and surrounding environment. To find an optimal state that minimizes the target's localization uncertainty, DyFOS uses a localization error prediction pipeline in an optimization search. Given the states mentioned above, the pipeline predicts the target's localization uncertainty with the help of a trained, complex state-dependent sensor measurement model (which is a probabilistic neural network in our case). Our pipeline also predicts target occlusion and obstacle collision to remove undesirable observer states. The output of the optimization search is an optimal observer state that minimizes target localization uncertainty while avoiding occlusion and collision. We evaluate the proposed method using numerical and simulated (Gazebo) experiments. Our results show that DyFOS is almost 100x faster than yet as good as brute force. Furthermore, DyFOS yielded lower localization errors than random and heuristic searches.