 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFFORD2ACT: Affordance-Guided Automatic Keypoint Selection for Generalizable and Lightweight Robotic Manipulation
Oct 01, 2025Vision-based robot learning often relies on dense image or point-cloud inputs, which are computationally heavy and entangle irrelevant background features. Existing keypoint-based approaches can focus on manipulation-centric features and be lightweight, but either depend on manual heuristics or task-coupled selection, limiting scalability and semantic understanding. To address this, we propose AFFORD2ACT, an affordance-guided framework that distills a minimal set of semantic 2D keypoints from a text prompt and a single image. AFFORD2ACT follows a three-stage pipeline: affordance filtering, category-level keypoint construction, and transformer-based policy learning with embedded gating to reason about the most relevant keypoints, yielding a compact 38-dimensional state policy that can be trained in 15 minutes, which performs well in real-time without proprioception or dense representations. Across diverse real-world manipulation tasks, AFFORD2ACT consistently improves data efficiency, achieving an 82% success rate on unseen objects, novel categories, backgrounds, and distractors.
When to Localize? A POMDP Approach
Nov 13, 2024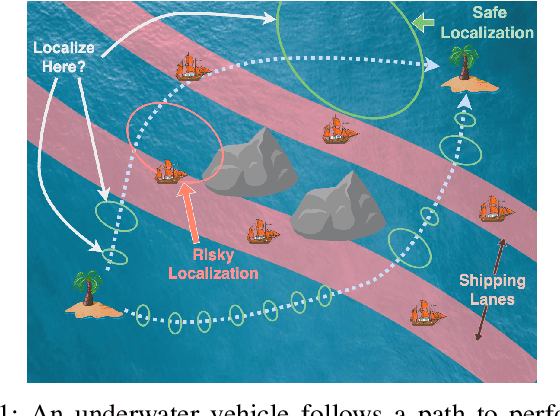
Robots often localize to lower navigational errors and facilitate downstream, high-level tasks. However, a robot may want to selectively localize when localization is costly (such as with resource-constrained robots) or inefficient (for example, submersibles that need to surface), especially when navigating in environments with variable numbers of hazards such as obstacles and shipping lanes. In this study, we propose a method that helps a robot determine ``when to localize'' to 1) minimize such actions and 2) not exceed the probability of failure (such as surfacing within high-traffic shipping lanes). We formulate our method as a Constrained Partially Observable Markov Decision Process and use the Cost-Constrained POMCP solver to plan the robot's actions. The solver simulates failure probabilities to decide if a robot moves to its goal or localizes to prevent failure. We performed numerical experiments with multiple baselines.
When to Localize? A Risk-Constrained Reinforcement Learning Approach
Nov 05, 2024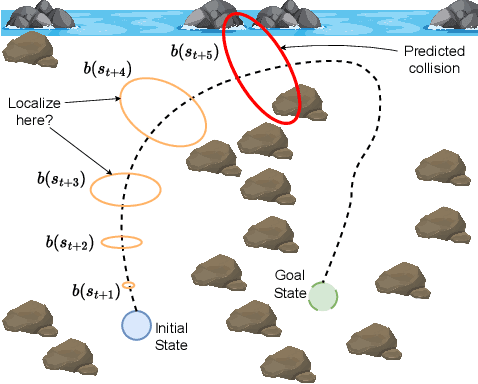
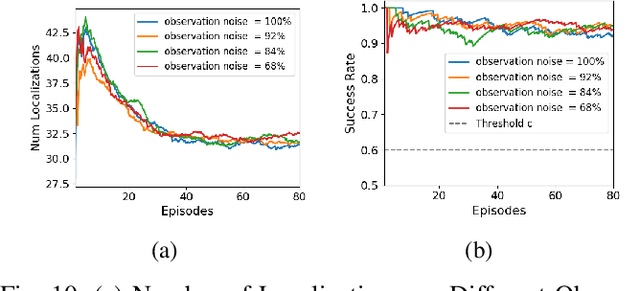
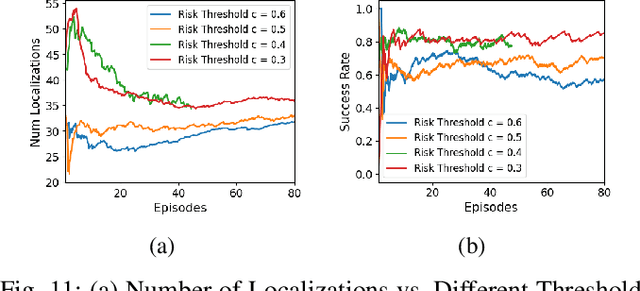
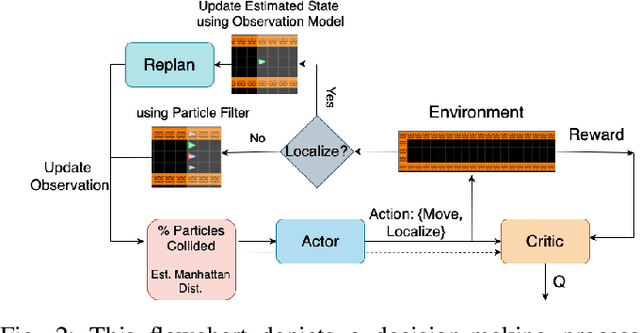
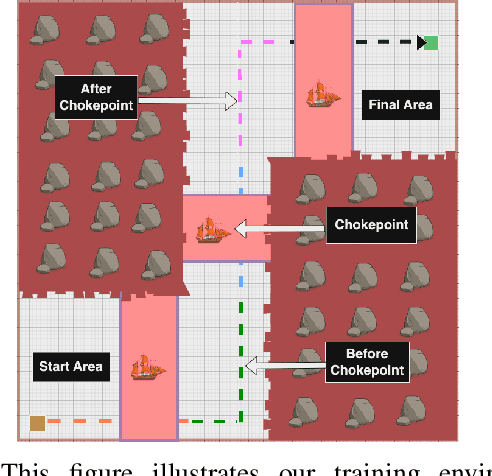
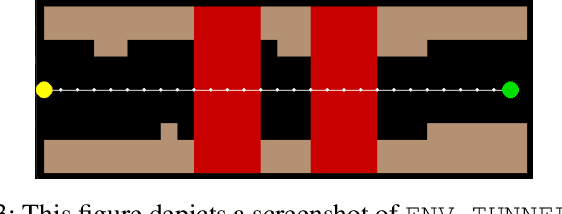
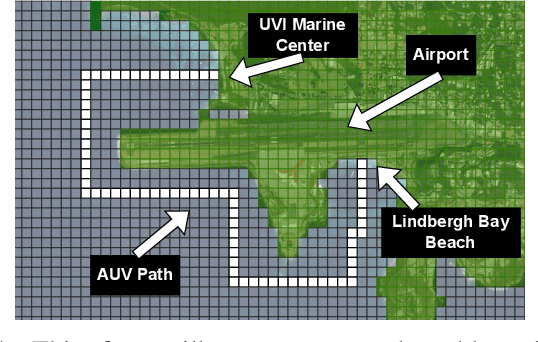
In a standard navigation pipeline, a robot localizes at every time step to lower navigational errors. However, in some scenarios, a robot needs to selectively localize when it is expensive to obtain observations. For example, an underwater robot surfacing to localize too often hinders it from searching for critical items underwater, such as black boxes from crashed aircraft. On the other hand, if the robot never localizes, poor state estimates cause failure to find the items due to inadvertently leaving the search area or entering hazardous, restricted areas. Motivated by these scenarios, we investigate approaches to help a robot determine "when to localize?" We formulate this as a bi-criteria optimization problem: minimize the number of localization actions while ensuring the probability of failure (due to collision or not reaching a desired goal) remains bounded. In recent work, we showed how to formulate this active localization problem as a constrained Partially Observable Markov Decision Process (POMDP), which was solved using an online POMDP solver. However, this approach is too slow and requires full knowledge of the robot transition and observation models. In this paper, we present RiskRL, a constrained Reinforcement Learning (RL) framework that overcomes these limitations. RiskRL uses particle filtering and recurrent Soft Actor-Critic network to learn a policy that minimizes the number of localizations while ensuring the probability of failure constraint is met. Our numerical experiments show that RiskRL learns a robust policy that outperforms the baseline by at least 13% while also generalizing to unseen environments.