 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Localize? A Risk-Constrained Reinforcement Learning Approach
Paper and Code
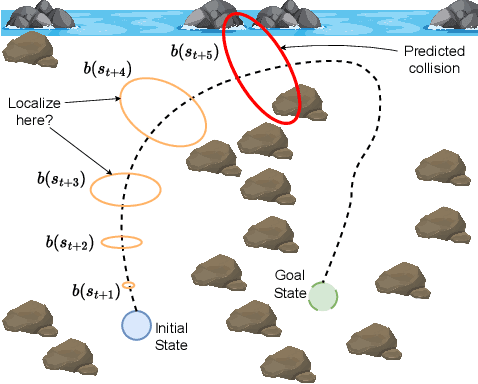
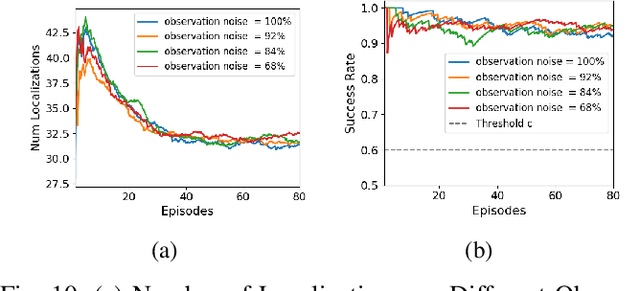
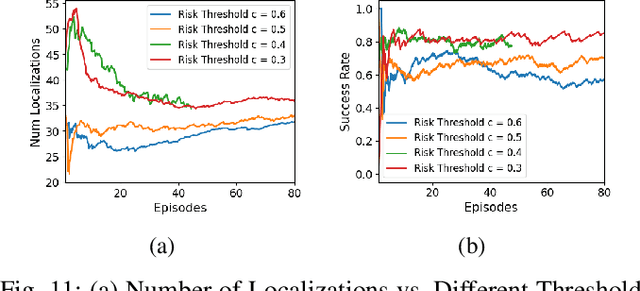
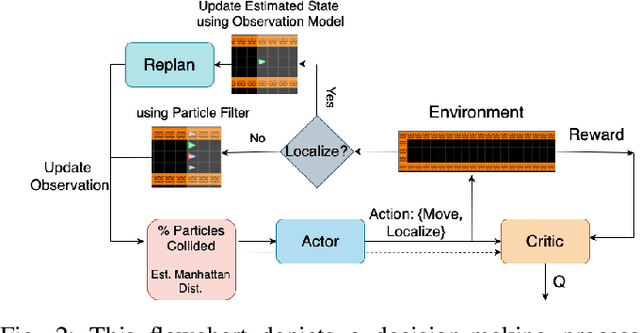
In a standard navigation pipeline, a robot localizes at every time step to lower navigational errors. However, in some scenarios, a robot needs to selectively localize when it is expensive to obtain observations. For example, an underwater robot surfacing to localize too often hinders it from searching for critical items underwater, such as black boxes from crashed aircraft. On the other hand, if the robot never localizes, poor state estimates cause failure to find the items due to inadvertently leaving the search area or entering hazardous, restricted areas. Motivated by these scenarios, we investigate approaches to help a robot determine "when to localize?" We formulate this as a bi-criteria optimization problem: minimize the number of localization actions while ensuring the probability of failure (due to collision or not reaching a desired goal) remains bounded. In recent work, we showed how to formulate this active localization problem as a constrained Partially Observable Markov Decision Process (POMDP), which was solved using an online POMDP solver. However, this approach is too slow and requires full knowledge of the robot transition and observation models. In this paper, we present RiskRL, a constrained Reinforcement Learning (RL) framework that overcomes these limitations. RiskRL uses particle filtering and recurrent Soft Actor-Critic network to learn a policy that minimizes the number of localizations while ensuring the probability of failure constraint is met. Our numerical experiments show that RiskRL learns a robust policy that outperforms the baseline by at least 13% while also generalizing to unseen environments.