 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Frame Is the Place to Go for Video Content Customization
Nov 19, 2025What role does the first frame play in video generation models? Traditionally, it's viewed as the spatial-temporal starting point of a video, merely a seed for subsequent animation. In this work, we reveal a fundamentally different perspective: video models implicitly treat the first frame as a conceptual memory buffer that stores visual entities for later reuse during generation. Leveraging this insight, we show that it's possible to achieve robust and generalized video content customization in diverse scenarios, using only 20-50 training examples without architectural changes or large-scale finetuning. This unveils a powerful, overlooked capability of video generation models for reference-based video customization.
Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
Jun 18, 2025Evaluating open-ended long-form generation is challenging because it is hard to define what clearly separates good from bad outputs. Existing methods often miss key aspects like coherence, style, or relevance, or are biased by pretraining data, making open-ended long-form evaluation an underexplored problem. To address this gap, we propose PrefBERT, a scoring model for evaluating open-ended long-form generation in GRPO and guiding its training with distinct rewards for good and bad outputs. Trained on two response evaluation datasets with diverse long-form styles and Likert-rated quality, PrefBERT effectively supports GRPO by offering better semantic reward feedback than traditional metrics ROUGE-L and BERTScore do. Through comprehensive evaluations, including LLM-as-a-judge, human ratings, and qualitative analysis, we show that PrefBERT, trained on multi-sentence and paragraph-length responses, remains reliable across varied long passages and aligns well with the verifiable rewards GRPO needs. Human evaluations confirm that using PrefBERT as the reward signal to train policy models yields responses better aligned with human preferences than those trained with traditional metrics. Our code is available at https://github.com/zli12321/long_form_rl.
VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
May 02, 2025Synthetic video generation with foundation models has gained attention for its realism and wide applications. While these models produce high-quality frames, they often fail to respect common sense and physical laws, resulting in abnormal content. Existing metrics like VideoScore emphasize general quality but ignore such violations and lack interpretability. A more insightful approach is using multi-modal large language models (MLLMs) as interpretable evaluators, as seen in FactScore. Yet, MLLMs' ability to detect abnormalities in synthetic videos remains underexplored. To address this, we introduce VideoHallu, a benchmark featuring synthetic videos from models like Veo2, Sora, and Kling, paired with expert-designed QA tasks solvable via human-level reasoning across various categories. We assess several SoTA MLLMs, including GPT-4o, Gemini-2.5-Pro, Qwen-2.5-VL, and newer models like Video-R1 and VideoChat-R1. Despite strong real-world performance on MVBench and MovieChat, these models still hallucinate on basic commonsense and physics tasks in synthetic settings, underscoring the challenge of hallucination. We further fine-tune SoTA MLLMs using Group Relative Policy Optimization (GRPO) on real and synthetic commonsense/physics data. Results show notable accuracy gains, especially with counterexample integration, advancing MLLMs' reasoning capabilities. Our data is available at https://github.com/zli12321/VideoHallu.
Benchmark Evaluations, Applications, and Challenges of Large Vision Language Models: A Survey
Jan 04, 2025



Multimodal Vision Language Models (VLMs) have emerged as a transformative technology at the intersection of computer vision and natural language processing, enabling machines to perceive and reason about the world through both visual and textual modalities. For example, models such as CLIP, Claude, and GPT-4V demonstrate strong reasoning and understanding abilities on visual and textual data and beat classical single modality vision models on zero-shot classification. Despite their rapid advancements in research and growing popularity in applications, a comprehensive survey of existing studies on VLMs is notably lacking, particularly for researchers aiming to leverage VLMs in their specific domains. To this end, we provide a systematic overview of VLMs in the following aspects: model information of the major VLMs developed over the past five years (2019-2024); the main architectures and training methods of these VLMs; summary and categorization of the popular benchmarks and evaluation metrics of VLMs; the applications of VLMs including embodied agents, robotics, and video generation; the challenges and issues faced by current VLMs such as hallucination, fairness, and safety. Detailed collections including papers and model repository links are listed in https://github.com/zli12321/Awesome-VLM-Papers-And-Models.git.
SOAR: Self-supervision Optimized UAV Action Recognition with Efficient Object-Aware Pretraining
Sep 26, 2024
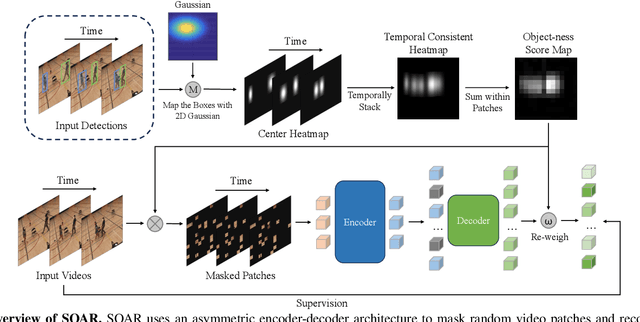
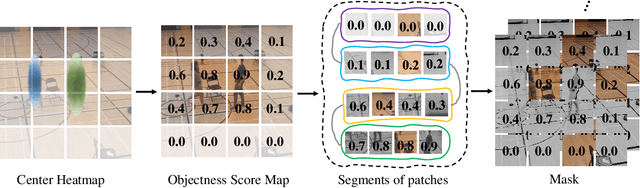
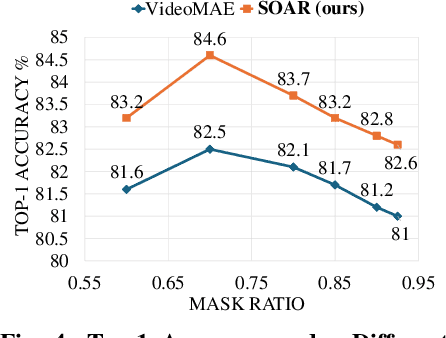
We introduce SOAR, a novel Self-supervised pretraining algorithm for aerial footage captured by Unmanned Aerial Vehicles (UAVs). We incorporate human object knowledge throughout the pretraining process to enhance UAV video pretraining efficiency and downstream action recognition performance. This is in contrast to prior works that primarily incorporate object information during the fine-tuning stage. Specifically, we first propose a novel object-aware masking strategy designed to retain the visibility of certain patches related to objects throughout the pretraining phase. Second, we introduce an object-aware loss function that utilizes object information to adjust the reconstruction loss, preventing bias towards less informative background patches. In practice, SOAR with a vanilla ViT backbone, outperforms best UAV action recognition models, recording a 9.7% and 21.4% boost in top-1 accuracy on the NEC-Drone and UAV-Human datasets, while delivering an inference speed of 18.7ms per video, making it 2x to 5x faster. Additionally, SOAR obtains comparable accuracy to prior self-supervised learning (SSL) methods while requiring 87.5% less pretraining time and 25% less memory usage
AUTOHALLUSION: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
Jun 16, 2024



Large vision-language models (LVLMs) hallucinate: certain context cues in an image may trigger the language module's overconfident and incorrect reasoning on abnormal or hypothetical objects. Though a few benchmarks have been developed to investigate LVLM hallucinations, they mainly rely on hand-crafted corner cases whose fail patterns may hardly generalize, and finetuning on them could undermine their validity. These motivate us to develop the first automatic benchmark generation approach, AUTOHALLUSION, that harnesses a few principal strategies to create diverse hallucination examples. It probes the language modules in LVLMs for context cues and uses them to synthesize images by: (1) adding objects abnormal to the context cues; (2) for two co-occurring objects, keeping one and excluding the other; or (3) removing objects closely tied to the context cues. It then generates image-based questions whose ground-truth answers contradict the language module's prior. A model has to overcome contextual biases and distractions to reach correct answers, while incorrect or inconsistent answers indicate hallucinations. AUTOHALLUSION enables us to create new benchmarks at the minimum cost and thus overcomes the fragility of hand-crafted benchmarks. It also reveals common failure patterns and reasons, providing key insights to detect, avoid, or control hallucinations. Comprehensive evaluations of top-tier LVLMs, e.g., GPT-4V(ision), Gemini Pro Vision, Claude 3, and LLaVA-1.5, show a 97.7% and 98.7% success rate of hallucination induction on synthetic and real-world datasets of AUTOHALLUSION, paving the way for a long battle against hallucinations.
AGL-NET: Aerial-Ground Cross-Modal Global Localization with Varying Scales
Apr 04, 2024



We present AGL-NET, a novel learning-based method for global localization using LiDAR point clouds and satellite maps. AGL-NET tackles two critical challenges: bridging the representation gap between image and points modalities for robust feature matching, and handling inherent scale discrepancies between global view and local view. To address these challenges, AGL-NET leverages a unified network architecture with a novel two-stage matching design. The first stage extracts informative neural features directly from raw sensor data and performs initial feature matching. The second stage refines this matching process by extracting informative skeleton features and incorporating a novel scale alignment step to rectify scale variations between LiDAR and map data. Furthermore, a novel scale and skeleton loss function guides the network toward learning scale-invariant feature representations, eliminating the need for pre-processing satellite maps. This significantly improves real-world applicability in scenarios with unknown map scales. To facilitate rigorous performance evaluation, we introduce a meticulously designed dataset within the CARLA simulator specifically tailored for metric localization training and assessment. The code and dataset will be made publicly available.
On the Safety Concerns of Deploying LLMs/VLMs in Robotics: Highlighting the Risks and Vulnerabilities
Feb 24, 2024



In this paper, we highlight the critical issues of robustness and safety associated with integrating large language models (LLMs) and vision-language models (VLMs) into robotics applications. Recent works have focused on using LLMs and VLMs to improve the performance of robotics tasks, such as manipulation, navigation, etc. However, such integration can introduce significant vulnerabilities, in terms of their susceptibility to adversarial attacks due to the language models, potentially leading to catastrophic consequences. By examining recent works at the interface of LLMs/VLMs and robotics, we show that it is easy to manipulate or misguide the robot's actions, leading to safety hazards. We define and provide examples of several plausible adversarial attacks, and conduct experiments on three prominent robot frameworks integrated with a language model, including KnowNo VIMA, and Instruct2Act, to assess their susceptibility to these attacks. Our empirical findings reveal a striking vulnerability of LLM/VLM-robot integrated systems: simple adversarial attacks can significantly undermine the effectiveness of LLM/VLM-robot integrated systems. Specifically, our data demonstrate an average performance deterioration of 21.2% under prompt attacks and a more alarming 30.2% under perception attacks. These results underscore the critical need for robust countermeasures to ensure the safe and reliable deployment of the advanced LLM/VLM-based robotic systems.
LANCAR: Leveraging Language for Context-Aware Robot Locomotion in Unstructured Environments
Sep 30, 2023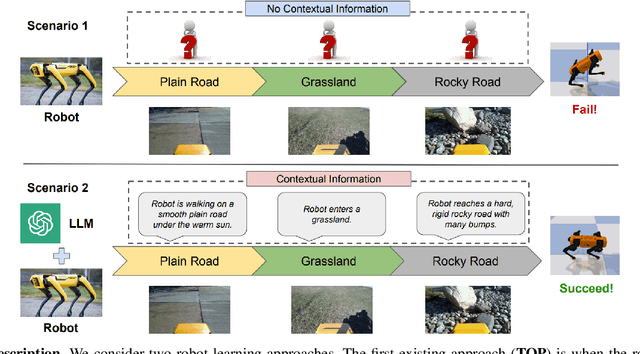
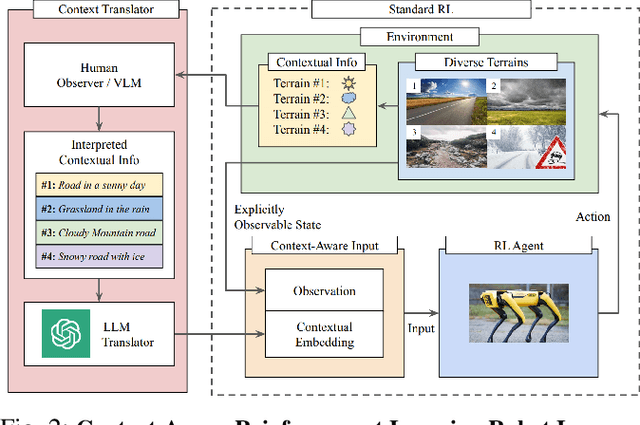
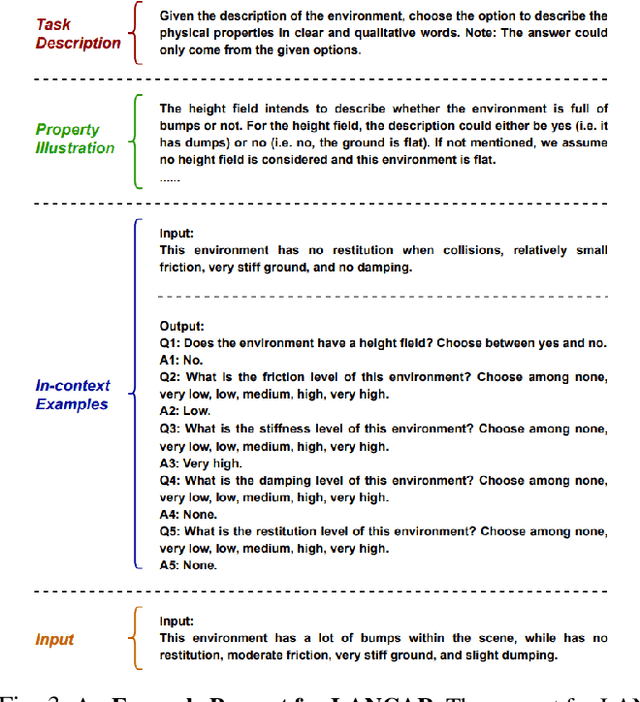

Robotic locomotion is a challenging task, especially in unstructured terrains. In practice, the optimal locomotion policy can be context-dependent by using the contextual information of encountered terrains in decision-making. Humans can interpret the environmental context for robots, but the ambiguity of human language makes it challenging to use in robot locomotion directly. In this paper, we propose a novel approach, LANCAR, that introduces a context translator that works with reinforcement learning (RL) agents for context-aware locomotion. Our formulation allows a robot to interpret the contextual information from environments generated by human observers or Vision-Language Models (VLM) with Large Language Models (LLM) and use this information to generate contextual embeddings. We incorporate the contextual embeddings with the robot's internal environmental observations as the input to the RL agent's decision neural network. We evaluate LANCAR with contextual information in varying ambiguity levels and compare its performance using several alternative approaches. Our experimental results demonstrate that our approach exhibits good generalizability and adaptability across diverse terrains, by achieving at least 10% of performance improvement in episodic reward over baselines. The experiment video can be found at the following link: https://raaslab.org/projects/LLM_Context_Estimation/.
iPLAN: Intent-Aware Planning in Heterogeneous Traffic via Distributed Multi-Agent Reinforcement Learning
Jun 09, 2023



Navigating safely and efficiently in dense and heterogeneous traffic scenarios is challenging for autonomous vehicles (AVs) due to their inability to infer the behaviors or intentions of nearby drivers. In this work, we propose a distributed multi-agent reinforcement learning (MARL) algorithm with trajectory and intent prediction in dense and heterogeneous traffic scenarios. Our approach for intent-aware planning, iPLAN, allows agents to infer nearby drivers' intents solely from their local observations. We model two distinct incentives for agents' strategies: Behavioral incentives for agents' long-term planning based on their driving behavior or personality; Instant incentives for agents' short-term planning for collision avoidance based on the current traffic state. We design a two-stream inference module that allows agents to infer their opponents' incentives and incorporate their inferred information into decision-making. We perform experiments on two simulation environments, Non-Cooperative Navigation and Heterogeneous Highway. In Heterogeneous Highway, results show that, compared with centralized MARL baselines such as QMIX and MAPPO, our method yields a 4.0% and 35.7% higher episodic reward in mild and chaotic traffic, with 48.1% higher success rate and 80.6% longer survival time in chaotic traffic. We also compare with a decentralized baseline IPPO and demonstrate a higher episodic reward of 9.2% and 10.3% in mild traffic and chaotic traffic, 25.3% higher success rate, and 13.7% longer survival time.