 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Frame Is the Place to Go for Video Content Customization
Nov 19, 2025What role does the first frame play in video generation models? Traditionally, it's viewed as the spatial-temporal starting point of a video, merely a seed for subsequent animation. In this work, we reveal a fundamentally different perspective: video models implicitly treat the first frame as a conceptual memory buffer that stores visual entities for later reuse during generation. Leveraging this insight, we show that it's possible to achieve robust and generalized video content customization in diverse scenarios, using only 20-50 training examples without architectural changes or large-scale finetuning. This unveils a powerful, overlooked capability of video generation models for reference-based video customization.
PIP-LLM: Integrating PDDL-Integer Programming with LLMs for Coordinating Multi-Robot Teams Using Natural Language
Oct 26, 2025Enabling robot teams to execute natural language commands requires translating high-level instructions into feasible, efficient multi-robot plans. While Large Language Models (LLMs) combined with Planning Domain Description Language (PDDL) offer promise for single-robot scenarios, existing approaches struggle with multi-robot coordination due to brittle task decomposition, poor scalability, and low coordination efficiency. We introduce PIP-LLM, a language-based coordination framework that consists of PDDL-based team-level planning and Integer Programming (IP) based robot-level planning. PIP-LLMs first decomposes the command by translating the command into a team-level PDDL problem and solves it to obtain a team-level plan, abstracting away robot assignment. Each team-level action represents a subtask to be finished by the team. Next, this plan is translated into a dependency graph representing the subtasks' dependency structure. Such a dependency graph is then used to guide the robot-level planning, in which each subtask node will be formulated as an IP-based task allocation problem, explicitly optimizing travel costs and workload while respecting robot capabilities and user-defined constraints. This separation of planning from assignment allows PIP-LLM to avoid the pitfalls of syntax-based decomposition and scale to larger teams. Experiments across diverse tasks show that PIP-LLM improves plan success rate, reduces maximum and average travel costs, and achieves better load balancing compared to state-of-the-art baselines.
Multi-Agent Trust Region Policy Optimisation: A Joint Constraint Approach
Aug 14, 2025Multi-agent reinforcement learning (MARL) requires coordinated and stable policy updates among interacting agents. Heterogeneous-Agent Trust Region Policy Optimization (HATRPO) enforces per-agent trust region constraints using Kullback-Leibler (KL) divergence to stabilize training. However, assigning each agent the same KL threshold can lead to slow and locally optimal updates, especially in heterogeneous settings. To address this limitation, we propose two approaches for allocating the KL divergence threshold across agents: HATRPO-W, a Karush-Kuhn-Tucker-based (KKT-based) method that optimizes threshold assignment under global KL constraints, and HATRPO-G, a greedy algorithm that prioritizes agents based on improvement-to-divergence ratio. By connecting sequential policy optimization with constrained threshold scheduling, our approach enables more flexible and effective learning in heterogeneous-agent settings. Experimental results demonstrate that our methods significantly boost the performance of HATRPO, achieving faster convergence and higher final rewards across diverse MARL benchmarks. Specifically, HATRPO-W and HATRPO-G achieve comparable improvements in final performance, each exceeding 22.5%. Notably, HATRPO-W also demonstrates more stable learning dynamics, as reflected by its lower variance.
VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
May 02, 2025Synthetic video generation with foundation models has gained attention for its realism and wide applications. While these models produce high-quality frames, they often fail to respect common sense and physical laws, resulting in abnormal content. Existing metrics like VideoScore emphasize general quality but ignore such violations and lack interpretability. A more insightful approach is using multi-modal large language models (MLLMs) as interpretable evaluators, as seen in FactScore. Yet, MLLMs' ability to detect abnormalities in synthetic videos remains underexplored. To address this, we introduce VideoHallu, a benchmark featuring synthetic videos from models like Veo2, Sora, and Kling, paired with expert-designed QA tasks solvable via human-level reasoning across various categories. We assess several SoTA MLLMs, including GPT-4o, Gemini-2.5-Pro, Qwen-2.5-VL, and newer models like Video-R1 and VideoChat-R1. Despite strong real-world performance on MVBench and MovieChat, these models still hallucinate on basic commonsense and physics tasks in synthetic settings, underscoring the challenge of hallucination. We further fine-tune SoTA MLLMs using Group Relative Policy Optimization (GRPO) on real and synthetic commonsense/physics data. Results show notable accuracy gains, especially with counterexample integration, advancing MLLMs' reasoning capabilities. Our data is available at https://github.com/zli12321/VideoHallu.
Benchmark Evaluations, Applications, and Challenges of Large Vision Language Models: A Survey
Jan 04, 2025



Multimodal Vision Language Models (VLMs) have emerged as a transformative technology at the intersection of computer vision and natural language processing, enabling machines to perceive and reason about the world through both visual and textual modalities. For example, models such as CLIP, Claude, and GPT-4V demonstrate strong reasoning and understanding abilities on visual and textual data and beat classical single modality vision models on zero-shot classification. Despite their rapid advancements in research and growing popularity in applications, a comprehensive survey of existing studies on VLMs is notably lacking, particularly for researchers aiming to leverage VLMs in their specific domains. To this end, we provide a systematic overview of VLMs in the following aspects: model information of the major VLMs developed over the past five years (2019-2024); the main architectures and training methods of these VLMs; summary and categorization of the popular benchmarks and evaluation metrics of VLMs; the applications of VLMs including embodied agents, robotics, and video generation; the challenges and issues faced by current VLMs such as hallucination, fairness, and safety. Detailed collections including papers and model repository links are listed in https://github.com/zli12321/Awesome-VLM-Papers-And-Models.git.
Inverse Risk-sensitive Multi-Robot Task Allocation
Jun 14, 2024


We consider a new variant of the multi-robot task allocation problem - Inverse Risk-sensitive Multi-Robot Task Allocation (IR-MRTA). "Forward" MRTA - the process of deciding which robot should perform a task given the reward (cost)-related parameters, is widely studied in the multi-robot literature. In this setting, the reward (cost)-related parameters are assumed to be already known: parameters are first fixed offline by domain experts, followed by coordinating robots online. What if we need these parameters to be adjusted by non-expert human supervisors who oversee the robots during tasks to adapt to new situations? We are interested in the case where the human supervisor's perception of the allocation risk may change and suggest different allocations for robots compared to that from the MRTA algorithm. In such cases, the robots need to change the parameters of the allocation problem based on evolving human preferences. We study such problems through the lens of inverse task allocation, i.e., the process of finding parameters given solutions to the problem. Specifically, we propose a new formulation IR-MRTA, in which we aim to find a new set of parameters of the human behavioral risk model that minimally deviates from the current MRTA parameters and can make a greedy task allocation algorithm allocate robot resources in line with those suggested by humans. We show that even in the simple case such a problem is a non-convex optimization problem. We propose a Branch $\&$ Bound algorithm (BB-IR-MRTA) to solve such problems. In numerical simulations of a case study on multi-robot target capture, we demonstrate how to use BB-IR-MRTA and we show that the proposed algorithm achieves significant advantages in running time and peak memory usage compared to a brute-force baseline.
Fast k-connectivity Restoration in Multi-Robot Systems for Robust Communication Maintenance
Apr 04, 2024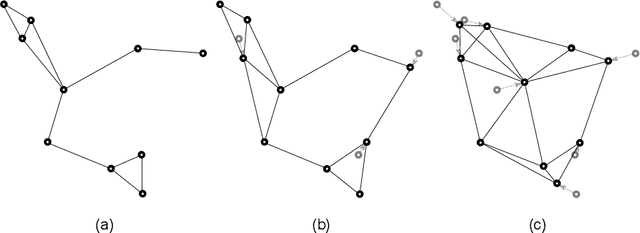
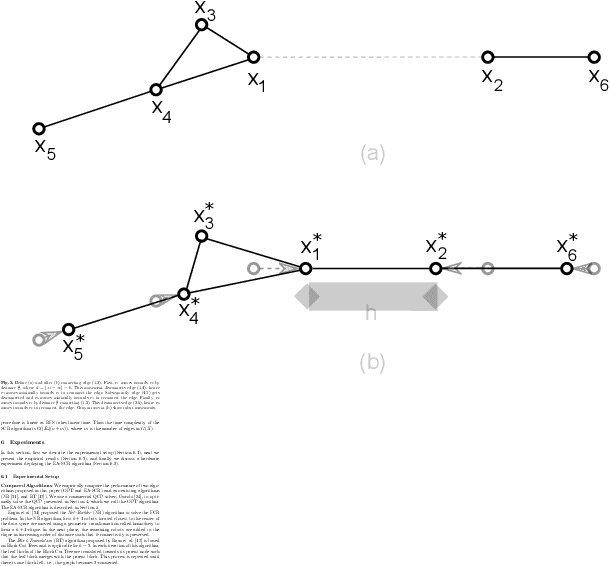
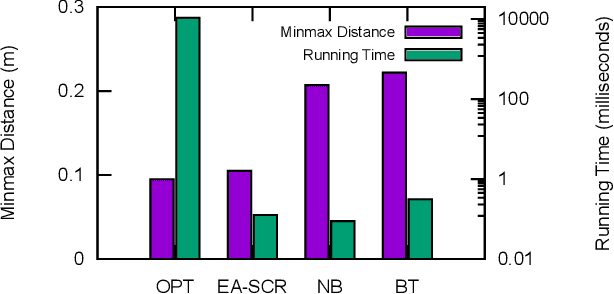
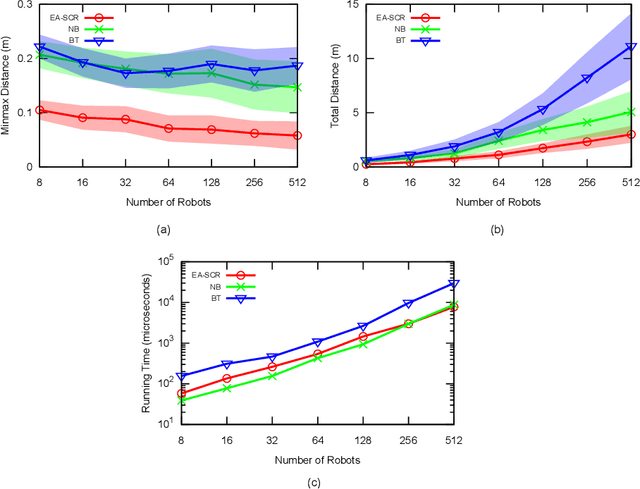
Maintaining a robust communication network plays an important role in the success of a multi-robot team jointly performing an optimization task. A key characteristic of a robust cooperative multi-robot system is the ability to repair the communication topology in the case of robot failure. In this paper, we focus on the Fast k-connectivity Restoration (FCR) problem, which aims to repair a network to make it k-connected with minimum robot movement. We develop a Quadratically Constrained Program (QCP) formulation of the FCR problem, which provides a way to optimally solve the problem, but cannot handle large instances due to high computational overhead. We therefore present a scalable algorithm, called EA-SCR, for the FCR problem using graph theoretic concepts. By conducting empirical studies, we demonstrate that the EA-SCR algorithm performs within 10 percent of the optimal while being orders of magnitude faster. We also show that EA-SCR outperforms existing solutions by 30 percent in terms of the FCR distance metric.
LAVA: Long-horizon Visual Action based Food Acquisition
Mar 19, 2024



Robotic Assisted Feeding (RAF) addresses the fundamental need for individuals with mobility impairments to regain autonomy in feeding themselves. The goal of RAF is to use a robot arm to acquire and transfer food to individuals from the table. Existing RAF methods primarily focus on solid foods, leaving a gap in manipulation strategies for semi-solid and deformable foods. This study introduces Long-horizon Visual Action (LAVA) based food acquisition of liquid, semisolid, and deformable foods. Long-horizon refers to the goal of "clearing the bowl" by sequentially acquiring the food from the bowl. LAVA employs a hierarchical policy for long-horizon food acquisition tasks. The framework uses high-level policy to determine primitives by leveraging ScoopNet. At the mid-level, LAVA finds parameters for primitives using vision. To carry out sequential plans in the real world, LAVA delegates action execution which is driven by Low-level policy that uses parameters received from mid-level policy and behavior cloning ensuring precise trajectory execution. We validate our approach on complex real-world acquisition trials involving granular, liquid, semisolid, and deformable food types along with fruit chunks and soup acquisition. Across 46 bowls, LAVA acquires much more efficiently than baselines with a success rate of 89 +/- 4% and generalizes across realistic plate variations such as different positions, varieties, and amount of food in the bowl. Code, datasets, videos, and supplementary materials can be found on our website.
From Words to Routes: Applying Large Language Models to Vehicle Routing
Mar 16, 2024



LLMs have shown impressive progress in robotics (e.g., manipulation and navigation) with natural language task descriptions. The success of LLMs in these tasks leads us to wonder: What is the ability of LLMs to solve vehicle routing problems (VRPs) with natural language task descriptions? In this work, we study this question in three steps. First, we construct a dataset with 21 types of single- or multi-vehicle routing problems. Second, we evaluate the performance of LLMs across four basic prompt paradigms of text-to-code generation, each involving different types of text input. We find that the basic prompt paradigm, which generates code directly from natural language task descriptions, performs the best for GPT-4, achieving 56% feasibility, 40% optimality, and 53% efficiency. Third, based on the observation that LLMs may not be able to provide correct solutions at the initial attempt, we propose a framework that enables LLMs to refine solutions through self-reflection, including self-debugging and self-verification. With GPT-4, our proposed framework achieves a 16% increase in feasibility, a 7% increase in optimality, and a 15% increase in efficiency. Moreover, we examine the sensitivity of GPT-4 to task descriptions, specifically focusing on how its performance changes when certain details are omitted from the task descriptions, yet the core meaning is preserved. Our findings reveal that such omissions lead to a notable decrease in performance: 4% in feasibility, 4% in optimality, and 5% in efficiency. Website: https://sites.google.com/view/words-to-routes/
Inverse Submodular Maximization with Application to Human-in-the-Loop Multi-Robot Multi-Objective Coverage Control
Mar 16, 2024



We consider a new type of inverse combinatorial optimization, Inverse Submodular Maximization (ISM), for human-in-the-loop multi-robot coordination. Forward combinatorial optimization, defined as the process of solving a combinatorial problem given the reward (cost)-related parameters, is widely used in multi-robot coordination. In the standard pipeline, the reward (cost)-related parameters are designed offline by domain experts first and then these parameters are utilized for coordinating robots online. What if we need to change these parameters by non-expert human supervisors who watch over the robots during tasks to adapt to some new requirements? We are interested in the case where human supervisors can suggest what actions to take, and the robots need to change the internal parameters based on such suggestions. We study such problems from the perspective of inverse combinatorial optimization, i.e., the process of finding parameters given solutions to the problem. Specifically, we propose a new formulation for ISM, in which we aim to find a new set of parameters that minimally deviate from the current parameters and can make the greedy algorithm output actions the same as those suggested by humans. We show that such problems can be formulated as a Mixed Integer Quadratic Program (MIQP). However, MIQP involves exponentially many binary variables, making it intractable for the existing solver when the problem size is large. We propose a new algorithm under the Branch $\&$ Bound paradigm to solve such problems. In numerical simulations, we demonstrate how to use ISM in multi-robot multi-objective coverage control, and we show that the proposed algorithm achieves significant advantages in running time and peak memory usage compared to directly using an existing solver.