 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents
Nov 10, 2025Deep Research (DR) is an emerging agent application that leverages large language models (LLMs) to address open-ended queries. It requires the integration of several capabilities, including multi-step reasoning, cross-document synthesis, and the generation of evidence-backed, long-form answers. Evaluating DR remains challenging because responses are lengthy and diverse, admit many valid solutions, and often depend on dynamic information sources. We introduce ResearchRubrics, a standardized benchmark for DR built with over 2,800+ hours of human labor that pairs realistic, domain-diverse prompts with 2,500+ expert-written, fine-grained rubrics to assess factual grounding, reasoning soundness, and clarity. We also propose a new complexity framework for categorizing DR tasks along three axes: conceptual breadth, logical nesting, and exploration. In addition, we develop human and model-based evaluation protocols that measure rubric adherence for DR agents. We evaluate several state-of-the-art DR systems and find that even leading agents like Gemini's DR and OpenAI's DR achieve under 68% average compliance with our rubrics, primarily due to missed implicit context and inadequate reasoning about retrieved information. Our results highlight the need for robust, scalable assessment of deep research capabilities, to which end we release ResearchRubrics(including all prompts, rubrics, and evaluation code) to facilitate progress toward well-justified research assistants.
SMARTER: A Data-efficient Framework to Improve Toxicity Detection with Explanation via Self-augmenting Large Language Models
Sep 18, 2025WARNING: This paper contains examples of offensive materials. Toxic content has become pervasive on social media platforms. We introduce SMARTER, a data-efficient two-stage framework for explainable content moderation using Large Language Models (LLMs). In Stage 1, we leverage LLMs' own outputs to generate synthetic explanations for both correct and incorrect labels, enabling alignment via preference optimization with minimal human supervision. In Stage 2, we refine explanation quality through cross-model training, allowing weaker models to align stylistically and semantically with stronger ones. Experiments on three benchmark tasks -- HateXplain, Latent Hate, and Implicit Hate -- demonstrate that SMARTER enables LLMs to achieve up to a 13.5% macro-F1 improvement over standard few-shot baselines while using only a fraction of the full training data. Our framework offers a scalable strategy for low-resource settings by harnessing LLMs' self-improving capabilities for both classification and explanation.
VietMix: A Naturally Occurring Vietnamese-English Code-Mixed Corpus with Iterative Augmentation for Machine Translation
May 30, 2025Machine translation systems fail when processing code-mixed inputs for low-resource languages. We address this challenge by curating VietMix, a parallel corpus of naturally occurring code-mixed Vietnamese text paired with expert English translations. Augmenting this resource, we developed a complementary synthetic data generation pipeline. This pipeline incorporates filtering mechanisms to ensure syntactic plausibility and pragmatic appropriateness in code-mixing patterns. Experimental validation shows our naturalistic and complementary synthetic data boost models' performance, measured by translation quality estimation scores, of up to 71.84 on COMETkiwi and 81.77 on XCOMET. Triangulating positive results with LLM-based assessments, augmented models are favored over seed fine-tuned counterparts in approximately 49% of judgments (54-56% excluding ties). VietMix and our augmentation methodology advance ecological validity in neural MT evaluations and establish a framework for addressing code-mixed translation challenges across other low-resource pairs.
Benchmark Evaluations, Applications, and Challenges of Large Vision Language Models: A Survey
Jan 04, 2025



Multimodal Vision Language Models (VLMs) have emerged as a transformative technology at the intersection of computer vision and natural language processing, enabling machines to perceive and reason about the world through both visual and textual modalities. For example, models such as CLIP, Claude, and GPT-4V demonstrate strong reasoning and understanding abilities on visual and textual data and beat classical single modality vision models on zero-shot classification. Despite their rapid advancements in research and growing popularity in applications, a comprehensive survey of existing studies on VLMs is notably lacking, particularly for researchers aiming to leverage VLMs in their specific domains. To this end, we provide a systematic overview of VLMs in the following aspects: model information of the major VLMs developed over the past five years (2019-2024); the main architectures and training methods of these VLMs; summary and categorization of the popular benchmarks and evaluation metrics of VLMs; the applications of VLMs including embodied agents, robotics, and video generation; the challenges and issues faced by current VLMs such as hallucination, fairness, and safety. Detailed collections including papers and model repository links are listed in https://github.com/zli12321/Awesome-VLM-Papers-And-Models.git.
"You Gotta be a Doctor, Lin": An Investigation of Name-Based Bias of Large Language Models in Employment Recommendations
Jun 18, 2024Social science research has shown that candidates with names indicative of certain races or genders often face discrimination in employment practices. Similarly, Large Language Models (LLMs) have demonstrated racial and gender biases in various applications. In this study, we utilize GPT-3.5-Turbo and Llama 3-70B-Instruct to simulate hiring decisions and salary recommendations for candidates with 320 first names that strongly signal their race and gender, across over 750,000 prompts. Our empirical results indicate a preference among these models for hiring candidates with White female-sounding names over other demographic groups across 40 occupations. Additionally, even among candidates with identical qualifications, salary recommendations vary by as much as 5% between different subgroups. A comparison with real-world labor data reveals inconsistent alignment with U.S. labor market characteristics, underscoring the necessity of risk investigation of LLM-powered systems.
HateCOT: An Explanation-Enhanced Dataset for Generalizable Offensive Speech Detection via Large Language Models
Mar 18, 2024The ubiquitousness of social media has led to the need for reliable and efficient detection of offensive content to limit harmful effects. This has led to a proliferation of datasets and models related to detecting offensive content. While sophisticated models have attained strong performance on individual datasets, these models often do not generalize due to differences between how "offensive content" is conceptualized, and the resulting differences in how these datasets are labeled. In this paper, we introduce HateCOT, a dataset of 52,000 samples drawn from diverse existing sources with explanations generated by GPT-3.5-Turbo and human-curated. We show that pre-training models for the detection of offensive content on HateCOT significantly boots open-sourced Language Models on three benchmark datasets in both zero and few-shot settings, despite differences in domain and task.} We further find that HateCOT enables effective K-shot fine-tuning in the low-resource settings.
PANDA (Pedantic ANswer-correctness Determination and Adjudication):Improving Automatic Evaluation for Question Answering and Text Generation
Feb 17, 2024



Question answering (QA) can only make progress if we know if an answer is correct, but for many of the most challenging and interesting QA examples, current answer correctness (AC) metrics do not align with human judgments, particularly verbose, free form answers from large language models (LLM). There are two challenges: a lack of data and that models are too big. LLM based scorers correlate better with humans, but this expensive task has only been tested on limited QA datasets. We rectify these issues by providing clear guidelines for evaluating machine QA adopted from human QA contests. We also introduce Precise ANswer correctness Determination and Adjudication (PANDA), a small, efficient, deterministic AC classifier (812 KB) that more accurately evaluates answer correctness.
"Define Your Terms" : Enhancing Efficient Offensive Speech Classification with Definition
Feb 05, 2024The propagation of offensive content through social media channels has garnered attention of the research community. Multiple works have proposed various semantically related yet subtle distinct categories of offensive speech. In this work, we explore meta-earning approaches to leverage the diversity of offensive speech corpora to enhance their reliable and efficient detection. We propose a joint embedding architecture that incorporates the input's label and definition for classification via Prototypical Network. Our model achieves at least 75% of the maximal F1-score while using less than 10% of the available training data across 4 datasets. Our experimental findings also provide a case study of training strategies valuable to combat resource scarcity.
CFMatch: Aligning Automated Answer Equivalence Evaluation with Expert Judgments For Open-Domain Question Answering
Jan 24, 2024

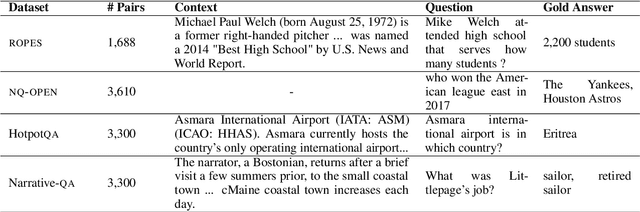

Question answering (QA) can only make progress if we know if an answer is correct, but for many of the most challenging and interesting QA examples, current evaluation metrics to determine answer equivalence (AE) often do not align with human judgments, particularly more verbose, free-form answers from large language models (LLM). There are two challenges: a lack of data and that models are too big: LLM-based scorers can correlate better with human judges, but this task has only been tested on limited QA datasets, and even when available, update of the model is limited because LLMs are large and often expensive. We rectify both of these issues by providing clear and consistent guidelines for evaluating AE in machine QA adopted from professional human QA contests. We also introduce a combination of standard evaluation and a more efficient, robust, and lightweight discriminate AE classifier-based matching method (CFMatch, smaller than 1 MB), trained and validated to more accurately evaluate answer correctness in accordance with adopted expert AE rules that are more aligned with human judgments.
"Stop Asian Hate!" : Refining Detection of Anti-Asian Hate Speech During the COVID-19 Pandemic
Dec 04, 2021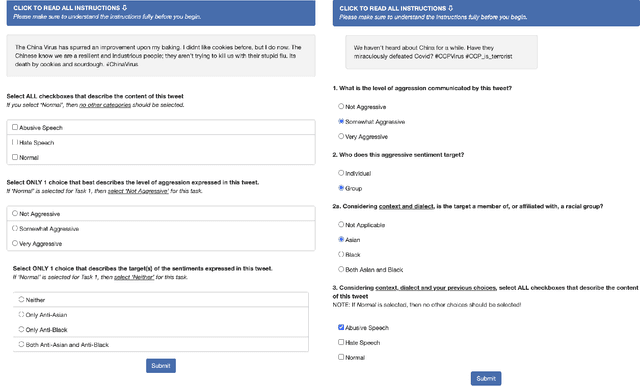
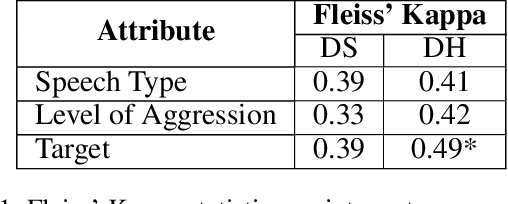
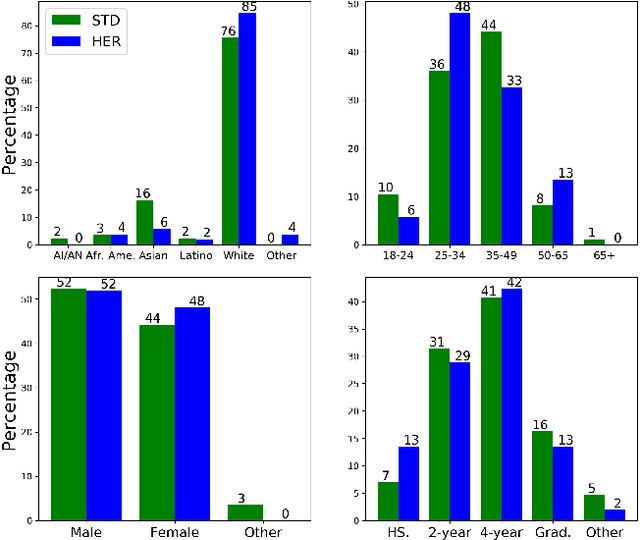
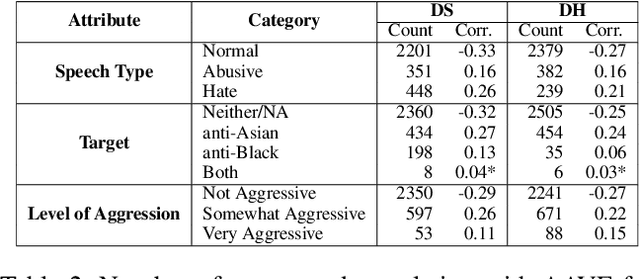
*Content warning: This work displays examples of explicit and strongly offensive language. The COVID-19 pandemic has fueled a surge in anti-Asian xenophobia and prejudice. Many have taken to social media to express these negative sentiments, necessitating the development of reliable systems to detect hate speech against this often under-represented demographic. In this paper, we create and annotate a corpus of Twitter tweets using 2 experimental approaches to explore anti-Asian abusive and hate speech at finer granularity. Using the dataset with less biased annotation, we deploy multiple models and also examine the applicability of other relevant corpora to accomplish these multi-task classifications. In addition to demonstrating promising results, our experiments offer insights into the nuances of cultural and logistical factors in annotating hate speech for different demographics. Our analyses together aim to contribute to the understanding of the area of hate speech detection, particularly towards low-resource groups.