 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Stop Asian Hate!" : Refining Detection of Anti-Asian Hate Speech During the COVID-19 Pandemic
Paper and Code
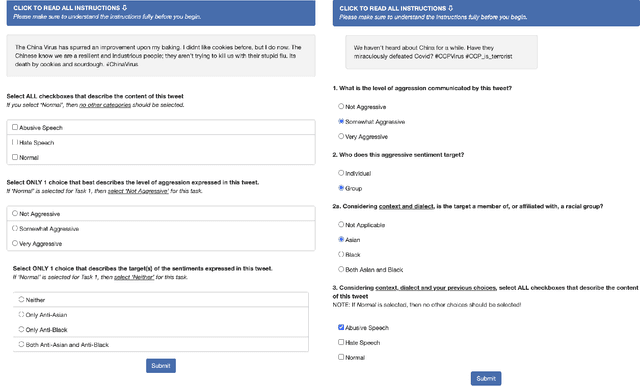
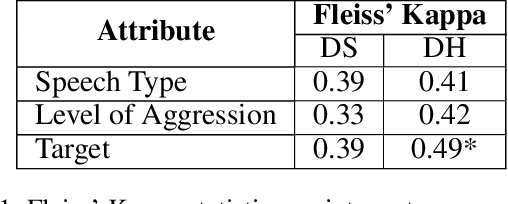
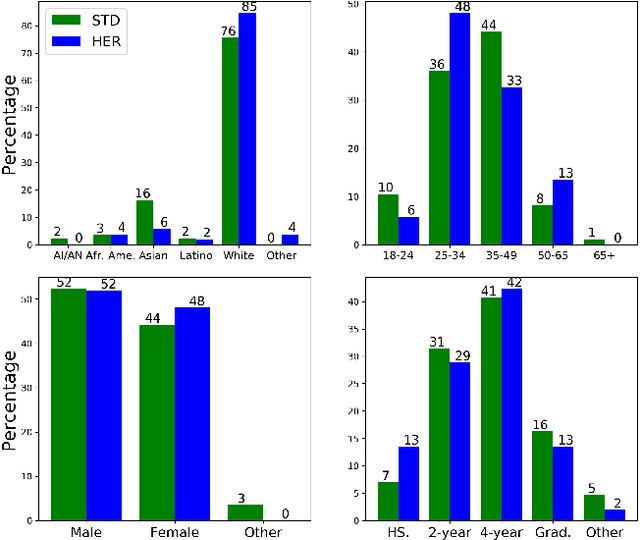
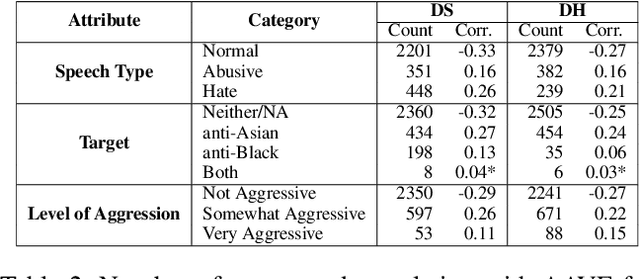
*Content warning: This work displays examples of explicit and strongly offensive language. The COVID-19 pandemic has fueled a surge in anti-Asian xenophobia and prejudice. Many have taken to social media to express these negative sentiments, necessitating the development of reliable systems to detect hate speech against this often under-represented demographic. In this paper, we create and annotate a corpus of Twitter tweets using 2 experimental approaches to explore anti-Asian abusive and hate speech at finer granularity. Using the dataset with less biased annotation, we deploy multiple models and also examine the applicability of other relevant corpora to accomplish these multi-task classifications. In addition to demonstrating promising results, our experiments offer insights into the nuances of cultural and logistical factors in annotating hate speech for different demographics. Our analyses together aim to contribute to the understanding of the area of hate speech detection, particularly towards low-resource groups.