 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
Jun 18, 2025Evaluating open-ended long-form generation is challenging because it is hard to define what clearly separates good from bad outputs. Existing methods often miss key aspects like coherence, style, or relevance, or are biased by pretraining data, making open-ended long-form evaluation an underexplored problem. To address this gap, we propose PrefBERT, a scoring model for evaluating open-ended long-form generation in GRPO and guiding its training with distinct rewards for good and bad outputs. Trained on two response evaluation datasets with diverse long-form styles and Likert-rated quality, PrefBERT effectively supports GRPO by offering better semantic reward feedback than traditional metrics ROUGE-L and BERTScore do. Through comprehensive evaluations, including LLM-as-a-judge, human ratings, and qualitative analysis, we show that PrefBERT, trained on multi-sentence and paragraph-length responses, remains reliable across varied long passages and aligns well with the verifiable rewards GRPO needs. Human evaluations confirm that using PrefBERT as the reward signal to train policy models yields responses better aligned with human preferences than those trained with traditional metrics. Our code is available at https://github.com/zli12321/long_form_rl.
VeriLA: A Human-Centered Evaluation Framework for Interpretable Verification of LLM Agent Failures
Mar 16, 2025AI practitioners increasingly use large language model (LLM) agents in compound AI systems to solve complex reasoning tasks, these agent executions often fail to meet human standards, leading to errors that compromise the system's overall performance. Addressing these failures through human intervention is challenging due to the agents' opaque reasoning processes, misalignment with human expectations, the complexity of agent dependencies, and the high cost of manual inspection. This paper thus introduces a human-centered evaluation framework for Verifying LLM Agent failures (VeriLA), which systematically assesses agent failures to reduce human effort and make these agent failures interpretable to humans. The framework first defines clear expectations of each agent by curating human-designed agent criteria. Then, it develops a human-aligned agent verifier module, trained with human gold standards, to assess each agent's execution output. This approach enables granular evaluation of each agent's performance by revealing failures from a human standard, offering clear guidelines for revision, and reducing human cognitive load. Our case study results show that VeriLA is both interpretable and efficient in helping practitioners interact more effectively with the system. By upholding accountability in human-agent collaboration, VeriLA paves the way for more trustworthy and human-aligned compound AI systems.
GRACE: A Granular Benchmark for Evaluating Model Calibration against Human Calibration
Feb 27, 2025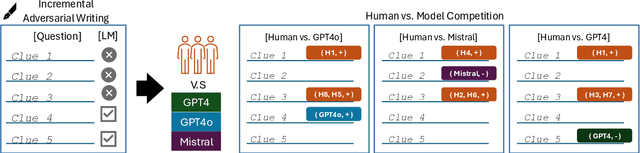
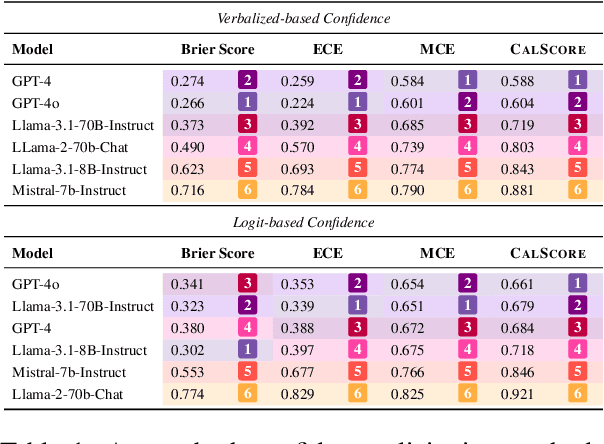
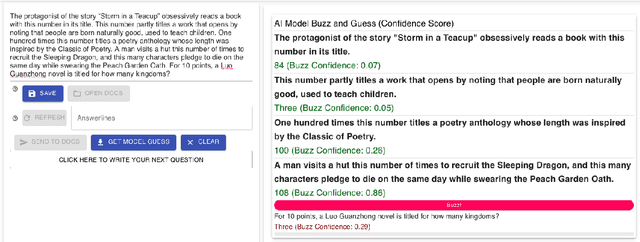
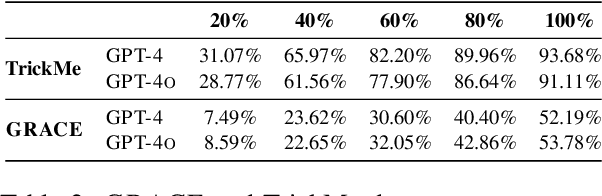
Language models are often miscalibrated, leading to confidently incorrect answers. We introduce GRACE, a benchmark for language model calibration that incorporates comparison with human calibration. GRACE consists of question-answer pairs, in which each question contains a series of clues that gradually become easier, all leading to the same answer; models must answer correctly as early as possible as the clues are revealed. This setting permits granular measurement of model calibration based on how early, accurately, and confidently a model answers. After collecting these questions, we host live human vs. model competitions to gather 1,749 data points on human and model teams' timing, accuracy, and confidence. We propose a metric, CalScore, that uses GRACE to analyze model calibration errors and identify types of model miscalibration that differ from human behavior. We find that although humans are less accurate than models, humans are generally better calibrated. Since state-of-the-art models struggle on GRACE, it effectively evaluates progress on improving model calibration.
ADVSCORE: A Metric for the Evaluation and Creation of Adversarial Benchmarks
Jun 24, 2024



Adversarial benchmarks validate model abilities by providing samples that fool models but not humans. However, despite the proliferation of datasets that claim to be adversarial, there does not exist an established metric to evaluate how adversarial these datasets are. To address this lacuna, we introduce ADVSCORE, a metric which quantifies how adversarial and discriminative an adversarial dataset is and exposes the features that make data adversarial. We then use ADVSCORE to underpin a dataset creation pipeline that incentivizes writing a high-quality adversarial dataset. As a proof of concept, we use ADVSCORE to collect an adversarial question answering (QA) dataset, ADVQA, from our pipeline. The high-quality questions in ADVQA surpasses three adversarial benchmarks across domains at fooling several models but not humans. We validate our result based on difficulty estimates from 9,347 human responses on four datasets and predictions from three models. Moreover, ADVSCORE uncovers which adversarial tactics used by human writers fool models (e.g., GPT-4) but not humans. Through ADVSCORE and its analyses, we offer guidance on revealing language model vulnerabilities and producing reliable adversarial examples.
How the Advent of Ubiquitous Large Language Models both Stymie and Turbocharge Dynamic Adversarial Question Generation
Jan 20, 2024Dynamic adversarial question generation, where humans write examples to stump a model, aims to create examples that are realistic and informative. However, the advent of large language models (LLMs) has been a double-edged sword for human authors: more people are interested in seeing and pushing the limits of these models, but because the models are so much stronger an opponent, they are harder to defeat. To understand how these models impact adversarial question writing process, we enrich the writing guidance with LLMs and retrieval models for the authors to reason why their questions are not adversarial. While authors could create interesting, challenging adversarial questions, they sometimes resort to tricks that result in poor questions that are ambiguous, subjective, or confusing not just to a computer but also to humans. To address these issues, we propose new metrics and incentives for eliciting good, challenging questions and present a new dataset of adversarially authored questions.
Not all Fake News is Written: A Dataset and Analysis of Misleading Video Headlines
Oct 20, 2023
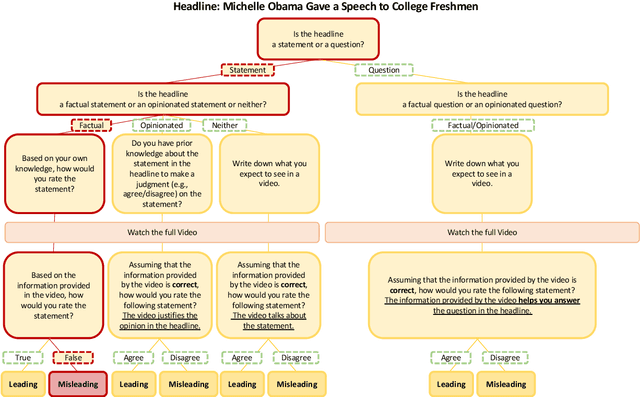


Polarization and the marketplace for impressions have conspired to make navigating information online difficult for users, and while there has been a significant effort to detect false or misleading text, multimodal datasets have received considerably less attention. To complement existing resources, we present multimodal Video Misleading Headline (VMH), a dataset that consists of videos and whether annotators believe the headline is representative of the video's contents. After collecting and annotating this dataset, we analyze multimodal baselines for detecting misleading headlines. Our annotation process also focuses on why annotators view a video as misleading, allowing us to better understand the interplay of annotators' background and the content of the videos.