 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Memorization in LLMs using Activation Steering
Paper and Code
Mar 08, 2025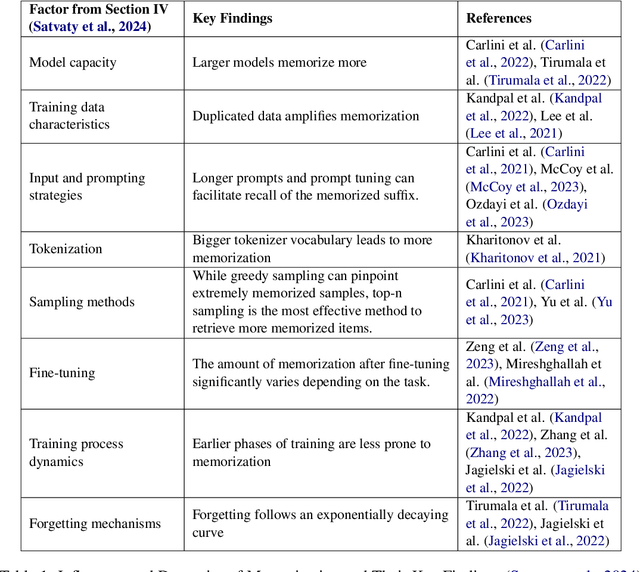
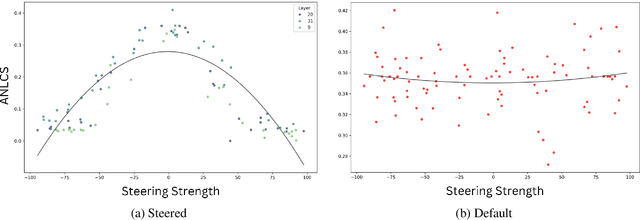
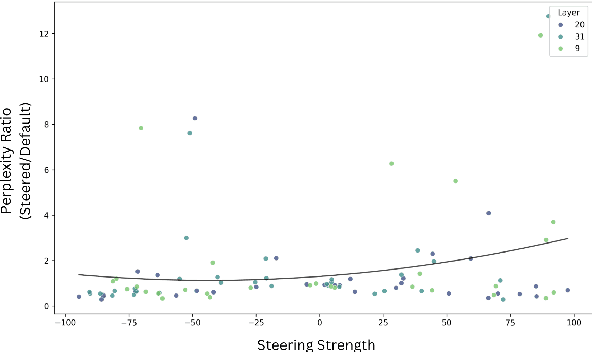
The memorization of training data by Large Language Models (LLMs) poses significant risks, including privacy leaks and the regurgitation of copyrighted content. Activation steering, a technique that directly intervenes in model activations, has emerged as a promising approach for manipulating LLMs. In this work, we explore the effectiveness of activation steering in reducing memorization while preserving generalization capabilities. We conduct empirical evaluations using a controlled memorization benchmark of literary material and demonstrate that our method successfully suppresses memorized content with minimal degradation in model performance in Gemma. Additionally, we analyze the trade-offs between suppression effectiveness and linguistic fluency, highlighting the advantages and limitations of activation-based interventions. Our findings contribute to ongoing efforts in developing safer and more privacy-preserving LLMs by providing a practical and efficient mechanism to mitigate unintended memorization.