 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch-to-Skill: Bootstrapping Robot Learning with Human Drawn Trajectory Sketches
Mar 14, 2025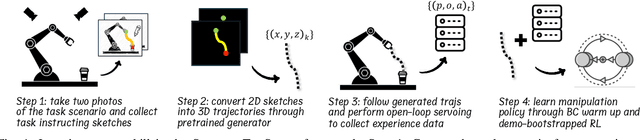
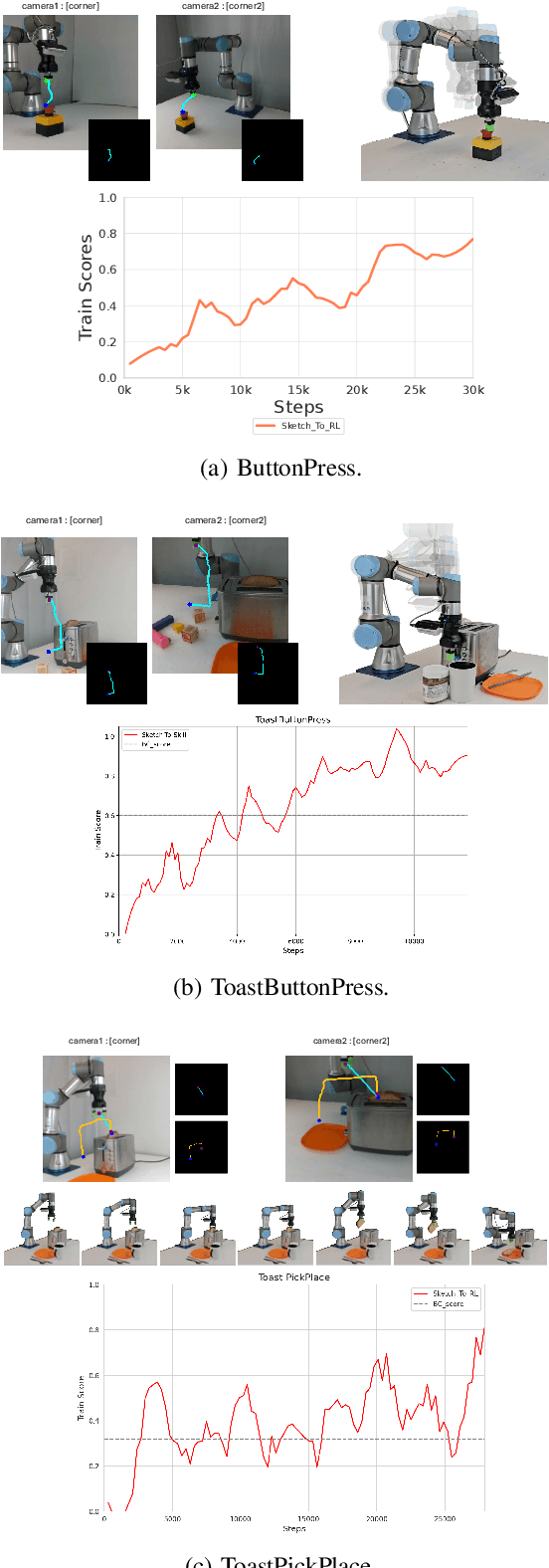
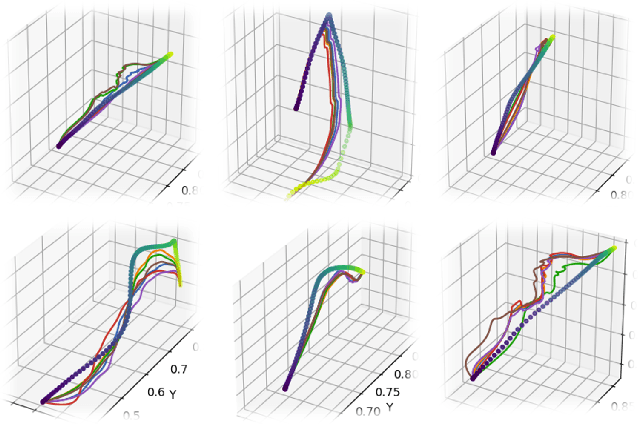
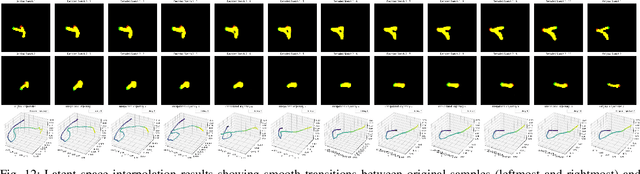
Training robotic manipulation policies traditionally requires numerous demonstrations and/or environmental rollouts. While recent Imitation Learning (IL) and Reinforcement Learning (RL) methods have reduced the number of required demonstrations, they still rely on expert knowledge to collect high-quality data, limiting scalability and accessibility. We propose Sketch-to-Skill, a novel framework that leverages human-drawn 2D sketch trajectories to bootstrap and guide RL for robotic manipulation. Our approach extends beyond previous sketch-based methods, which were primarily focused on imitation learning or policy conditioning, limited to specific trained tasks. Sketch-to-Skill employs a Sketch-to-3D Trajectory Generator that translates 2D sketches into 3D trajectories, which are then used to autonomously collect initial demonstrations. We utilize these sketch-generated demonstrations in two ways: to pre-train an initial policy through behavior cloning and to refine this policy through RL with guided exploration. Experimental results demonstrate that Sketch-to-Skill achieves ~96% of the performance of the baseline model that leverages teleoperated demonstration data, while exceeding the performance of a pure reinforcement learning policy by ~170%, only from sketch inputs. This makes robotic manipulation learning more accessible and potentially broadens its applications across various domains.
IMRL: Integrating Visual, Physical, Temporal, and Geometric Representations for Enhanced Food Acquisition
Sep 18, 2024Robotic assistive feeding holds significant promise for improving the quality of life for individuals with eating disabilities. However, acquiring diverse food items under varying conditions and generalizing to unseen food presents unique challenges. Existing methods that rely on surface-level geometric information (e.g., bounding box and pose) derived from visual cues (e.g., color, shape, and texture) often lacks adaptability and robustness, especially when foods share similar physical properties but differ in visual appearance. We employ imitation learning (IL) to learn a policy for food acquisition. Existing methods employ IL or Reinforcement Learning (RL) to learn a policy based on off-the-shelf image encoders such as ResNet-50. However, such representations are not robust and struggle to generalize across diverse acquisition scenarios. To address these limitations, we propose a novel approach, IMRL (Integrated Multi-Dimensional Representation Learning), which integrates visual, physical, temporal, and geometric representations to enhance the robustness and generalizability of IL for food acquisition. Our approach captures food types and physical properties (e.g., solid, semi-solid, granular, liquid, and mixture), models temporal dynamics of acquisition actions, and introduces geometric information to determine optimal scooping points and assess bowl fullness. IMRL enables IL to adaptively adjust scooping strategies based on context, improving the robot's capability to handle diverse food acquisition scenarios. Experiments on a real robot demonstrate our approach's robustness and adaptability across various foods and bowl configurations, including zero-shot generalization to unseen settings. Our approach achieves improvement up to $35\%$ in success rate compared with the best-performing baseline.
NAVINACT: Combining Navigation and Imitation Learning for Bootstrapping Reinforcement Learning
Aug 07, 2024Reinforcement Learning (RL) has shown remarkable progress in simulation environments, yet its application to real-world robotic tasks remains limited due to challenges in exploration and generalisation. To address these issues, we introduce NAVINACT, a framework that chooses when the robot should use classical motion planning-based navigation and when it should learn a policy. To further improve the efficiency in exploration, we use imitation data to bootstrap the exploration. NAVINACT dynamically switches between two modes of operation: navigating to a waypoint using classical techniques when away from the objects and reinforcement learning for fine-grained manipulation control when about to interact with objects. NAVINACT consists of a multi-head architecture composed of ModeNet for mode classification, NavNet for waypoint prediction, and InteractNet for precise manipulation. By combining the strengths of RL and Imitation Learning (IL), NAVINACT improves sample efficiency and mitigates distribution shift, ensuring robust task execution. We evaluate our approach across multiple challenging simulation environments and real-world tasks, demonstrating superior performance in terms of adaptability, efficiency, and generalization compared to existing methods. In both simulated and real-world settings, NAVINACT demonstrates robust performance. In simulations, NAVINACT surpasses baseline methods by 10-15\% in training success rates at 30k samples and by 30-40\% during evaluation phases. In real-world scenarios, it demonstrates a 30-40\% higher success rate on simpler tasks compared to baselines and uniquely succeeds in complex, two-stage manipulation tasks. Datasets and supplementary materials can be found on our website: {https://raaslab.org/projects/NAVINACT/}.