 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeightedKV: Attention Scores Weighted Key-Value Cache Merging for Large Language Models
Paper and Code
Mar 03, 2025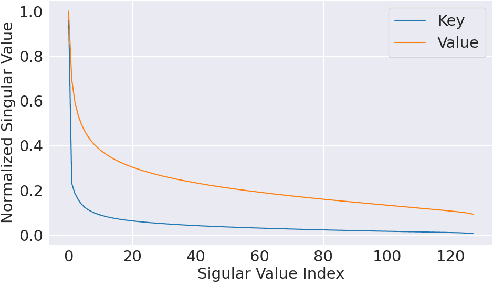
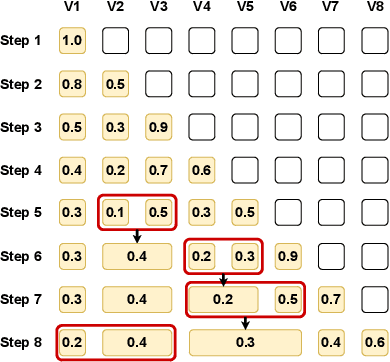
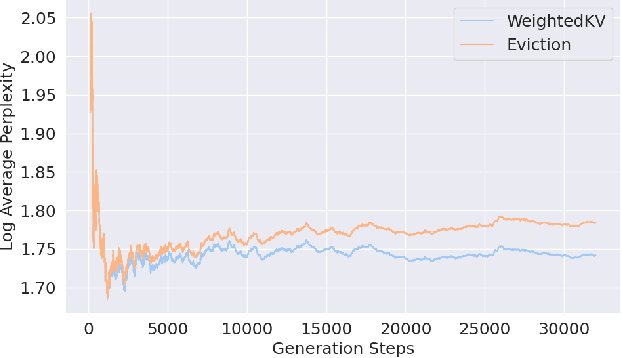
Large Language Models (LLMs) use key-value (KV) cache to reduce redundant computation in autoregressive generation. However, the KV cache size increases linearly during generation, leading to excessive memory usage, especially for long texts. Most KV cache compression methods evict the unimportant KV pairs to maintain a fixed cache size, which leads to the permanent loss of tokens during generation. However, singular value decomposition shows that \textit{values} do not exhibit a strong low-rank property as \textit{keys} do, suggesting that information is distributed more evenly across \textit{values}, in contrast to its more redundant distribution within \textit{keys}. Therefore, methods that evict both \textit{keys} and \textit{values} risk losing crucial information and compromise context integrity, ultimately degrading the output quality. To address this problem, we propose WeightedKV, a novel, training-free approach that discards the \textit{keys} of less important tokens, while merging their \textit{values} into neighboring tokens via a convex combination weighted by their average attention scores. In this way, the retained \textit{keys} serve as anchors that guide the generation process, while the merged \textit{values} provide a rich contextual backdrop. We assess our method on four widely used language modeling datasets, demonstrating superior performance compared to all baseline methods, particularly with a lower budget ratio.