 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Partial Action Replacement in Offline MARL
Mar 30, 2026Offline multi-agent reinforcement learning (MARL) faces a critical challenge: the joint action space grows exponentially with the number of agents, making dataset coverage exponentially sparse and out-of-distribution (OOD) joint actions unavoidable. Partial Action Replacement (PAR) mitigates this by anchoring a subset of agents to dataset actions, but existing approach relies on enumerating multiple subset configurations at high computational cost and cannot adapt to varying states. We introduce PLCQL, a framework that formulates PAR subset selection as a contextual bandit problem and learns a state-dependent PAR policy using Proximal Policy Optimisation with an uncertainty-weighted reward. This adaptive policy dynamically determines how many agents to replace at each update step, balancing policy improvement against conservative value estimation. We prove a value-error bound showing that the estimation error scales linearly with the expected number of deviating agents. Compared with the previous PAR-based method SPaCQL, PLCQL reduces the number of per-iteration Q-function evaluations from n to 1, significantly improving computational efficiency. Empirically, PLCQL achieves the highest normalised scores on 66% of tasks across MPE, MaMuJoCo, and SMAC benchmarks, outperforming SPaCQL on 84% of tasks while substantially reducing computational cost.
Exact Federated Continual Unlearning for Ridge Heads on Frozen Foundation Models
Mar 16, 2026Foundation models are commonly deployed as frozen feature extractors with a small trainable head to adapt to private, user-generated data in federated settings. The ``right to be forgotten'' requires removing the influence of specific samples or users from the trained model on demand. Existing federated unlearning methods target general deep models and rely on approximate reconstruction or selective retraining, making exactness costly or elusive. We study this problem in a practically relevant but under-explored regime: a frozen foundation model with a ridge-regression head. The exact optimum depends on the data only through two additive sufficient statistics, which we turn into a communication protocol supporting an arbitrary stream of add and delete requests via fixed-size messages. The server maintains a head that is, in exact arithmetic, pointwise identical to centralized retraining after every request. We provide deterministic retrain-equivalence guarantees, order and partition invariance, two server-side variants, and a Bayesian certificate of zero KL divergence. Experiments on four benchmarks confirm the guarantees: both variants match centralized ridge retraining to within $10^{-9}$ relative Frobenius error and complete each request at orders-of-magnitude lower cost than federated retraining baselines.
Show Me When and Where: Towards Referring Video Object Segmentation in the Wild
Mar 15, 2026Referring video object segmentation (RVOS) has recently generated great popularity in computer vision due to its widespread applications. Existing RVOS setting contains elaborately trimmed videos, with text-referred objects always appearing in all frames, which however fail to fully reflect the realistic challenges of this task. This simplified setting requires RVOS methods to only predict where objects, with no need to show when the objects appear. In this work, we introduce a new setting towards in-the-wild RVOS. To this end, we collect a new benchmark dataset using Youtube Untrimmed videos for RVOS - YoURVOS, which contains 1,120 in-the-wild videos with 7 times more duration and scenes than existing datasets. Our new benchmark challenges RVOS methods to show not only where but also when objects appear in videos. To set a baseline, we propose Object-level Multimodal TransFormers (OMFormer) to tackle the challenges, which are characterized by encoding object-level multimodal interactions for efficient and global spatial-temporal localisation. We demonstrate that previous VOS methods struggle on our YoURVOS benchmark, especially with the increase of target-absent frames, while our OMFormer consistently performs well. Our YoURVOS dataset offers an imperative benchmark, which will push forward the advancement of RVOS methods for practical applications.
Action-Free Offline-to-Online RL via Discretised State Policies
Jan 31, 2026Most existing offline RL methods presume the availability of action labels within the dataset, but in many practical scenarios, actions may be missing due to privacy, storage, or sensor limitations. We formalise the setting of action-free offline-to-online RL, where agents must learn from datasets consisting solely of $(s,r,s')$ tuples and later leverage this knowledge during online interaction. To address this challenge, we propose learning state policies that recommend desirable next-state transitions rather than actions. Our contributions are twofold. First, we introduce a simple yet novel state discretisation transformation and propose Offline State-Only DecQN (\algo), a value-based algorithm designed to pre-train state policies from action-free data. \algo{} integrates the transformation to scale efficiently to high-dimensional problems while avoiding instability and overfitting associated with continuous state prediction. Second, we propose a novel mechanism for guided online learning that leverages these pre-trained state policies to accelerate the learning of online agents. Together, these components establish a scalable and practical framework for leveraging action-free datasets to accelerate online RL. Empirical results across diverse benchmarks demonstrate that our approach improves convergence speed and asymptotic performance, while analyses reveal that discretisation and regularisation are critical to its effectiveness.
Partial Action Replacement: Tackling Distribution Shift in Offline MARL
Nov 10, 2025Offline multi-agent reinforcement learning (MARL) is severely hampered by the challenge of evaluating out-of-distribution (OOD) joint actions. Our core finding is that when the behavior policy is factorized - a common scenario where agents act fully or partially independently during data collection - a strategy of partial action replacement (PAR) can significantly mitigate this challenge. PAR updates a single or part of agents' actions while the others remain fixed to the behavioral data, reducing distribution shift compared to full joint-action updates. Based on this insight, we develop Soft-Partial Conservative Q-Learning (SPaCQL), using PAR to mitigate OOD issue and dynamically weighting different PAR strategies based on the uncertainty of value estimation. We provide a rigorous theoretical foundation for this approach, proving that under factorized behavior policies, the induced distribution shift scales linearly with the number of deviating agents rather than exponentially with the joint-action space. This yields a provably tighter value error bound for this important class of offline MARL problems. Our theoretical results also indicate that SPaCQL adaptively addresses distribution shift using uncertainty-informed weights. Our empirical results demonstrate SPaCQL enables more effective policy learning, and manifest its remarkable superiority over baseline algorithms when the offline dataset exhibits the independence structure.
Uncertainty-Based Smooth Policy Regularisation for Reinforcement Learning with Few Demonstrations
Sep 19, 2025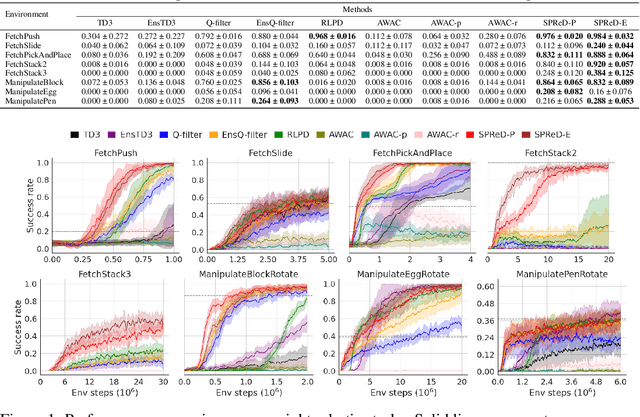
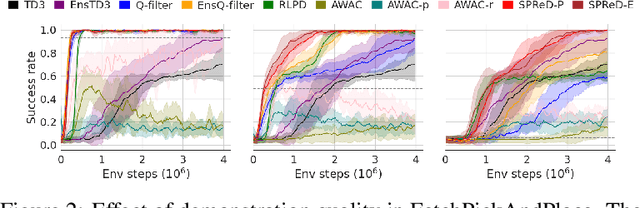


In reinforcement learning with sparse rewards, demonstrations can accelerate learning, but determining when to imitate them remains challenging. We propose Smooth Policy Regularisation from Demonstrations (SPReD), a framework that addresses the fundamental question: when should an agent imitate a demonstration versus follow its own policy? SPReD uses ensemble methods to explicitly model Q-value distributions for both demonstration and policy actions, quantifying uncertainty for comparisons. We develop two complementary uncertainty-aware methods: a probabilistic approach estimating the likelihood of demonstration superiority, and an advantage-based approach scaling imitation by statistical significance. Unlike prevailing methods (e.g. Q-filter) that make binary imitation decisions, SPReD applies continuous, uncertainty-proportional regularisation weights, reducing gradient variance during training. Despite its computational simplicity, SPReD achieves remarkable gains in experiments across eight robotics tasks, outperforming existing approaches by up to a factor of 14 in complex tasks while maintaining robustness to demonstration quality and quantity. Our code is available at https://github.com/YujieZhu7/SPReD.
Efficient Verified Machine Unlearning For Distillation
Mar 28, 2025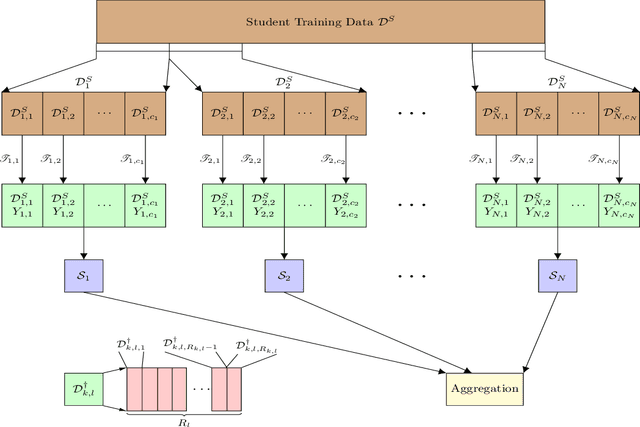
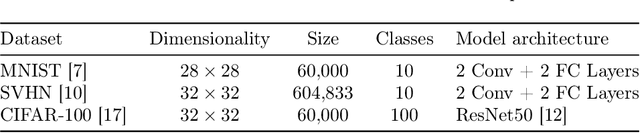
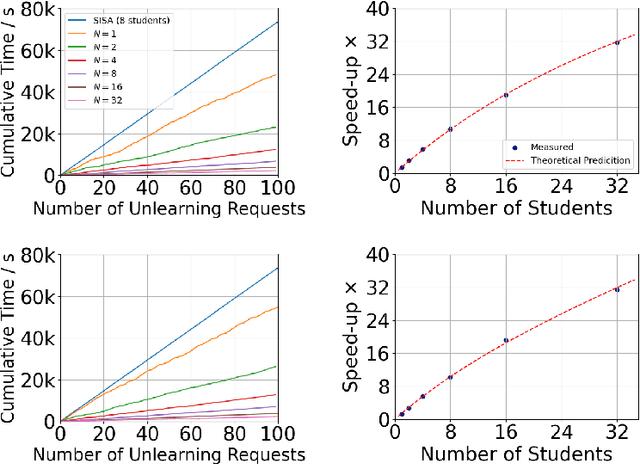
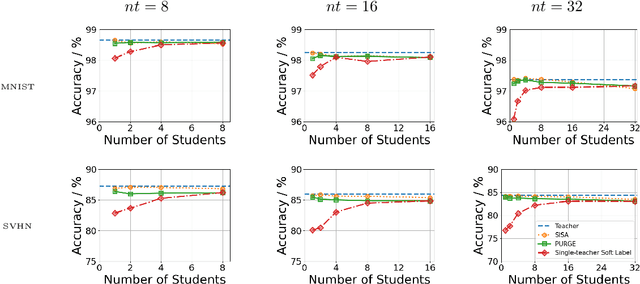
Growing data privacy demands, driven by regulations like GDPR and CCPA, require machine unlearning methods capable of swiftly removing the influence of specific training points. Although verified approaches like SISA, using data slicing and checkpointing, achieve efficient unlearning for single models by reverting to intermediate states, these methods struggle in teacher-student knowledge distillation settings. Unlearning in the teacher typically forces costly, complete student retraining due to pervasive information propagation during distillation. Our primary contribution is PURGE (Partitioned Unlearning with Retraining Guarantee for Ensembles), a novel framework integrating verified unlearning with distillation. We introduce constituent mapping and an incremental multi-teacher strategy that partitions the distillation process, confines each teacher constituent's impact to distinct student data subsets, and crucially maintains data isolation. The PURGE framework substantially reduces retraining overhead, requiring only partial student updates when teacher-side unlearning occurs. We provide both theoretical analysis, quantifying significant speed-ups in the unlearning process, and empirical validation on multiple datasets, demonstrating that PURGE achieves these efficiency gains while maintaining student accuracy comparable to standard baselines.
Evaluation-Time Policy Switching for Offline Reinforcement Learning
Mar 15, 2025Offline reinforcement learning (RL) looks at learning how to optimally solve tasks using a fixed dataset of interactions from the environment. Many off-policy algorithms developed for online learning struggle in the offline setting as they tend to over-estimate the behaviour of out of distributions actions. Existing offline RL algorithms adapt off-policy algorithms, employing techniques such as constraining the policy or modifying the value function to achieve good performance on individual datasets but struggle to adapt to different tasks or datasets of different qualities without tuning hyper-parameters. We introduce a policy switching technique that dynamically combines the behaviour of a pure off-policy RL agent, for improving behaviour, and a behavioural cloning (BC) agent, for staying close to the data. We achieve this by using a combination of epistemic uncertainty, quantified by our RL model, and a metric for aleatoric uncertainty extracted from the dataset. We show empirically that our policy switching technique can outperform not only the individual algorithms used in the switching process but also compete with state-of-the-art methods on numerous benchmarks. Our use of epistemic uncertainty for policy switching also allows us to naturally extend our method to the domain of offline to online fine-tuning allowing our model to adapt quickly and safely from online data, either matching or exceeding the performance of current methods that typically require additional modification or hyper-parameter fine-tuning.
Dynamic Pricing in High-Speed Railways Using Multi-Agent Reinforcement Learning
Jan 14, 2025This paper addresses a critical challenge in the high-speed passenger railway industry: designing effective dynamic pricing strategies in the context of competing and cooperating operators. To address this, a multi-agent reinforcement learning (MARL) framework based on a non-zero-sum Markov game is proposed, incorporating random utility models to capture passenger decision making. Unlike prior studies in areas such as energy, airlines, and mobile networks, dynamic pricing for railway systems using deep reinforcement learning has received limited attention. A key contribution of this paper is a parametrisable and versatile reinforcement learning simulator designed to model a variety of railway network configurations and demand patterns while enabling realistic, microscopic modelling of user behaviour, called RailPricing-RL. This environment supports the proposed MARL framework, which models heterogeneous agents competing to maximise individual profits while fostering cooperative behaviour to synchronise connecting services. Experimental results validate the framework, demonstrating how user preferences affect MARL performance and how pricing policies influence passenger choices, utility, and overall system dynamics. This study provides a foundation for advancing dynamic pricing strategies in railway systems, aligning profitability with system-wide efficiency, and supporting future research on optimising pricing policies.
Investigating Relational State Abstraction in Collaborative MARL
Dec 19, 2024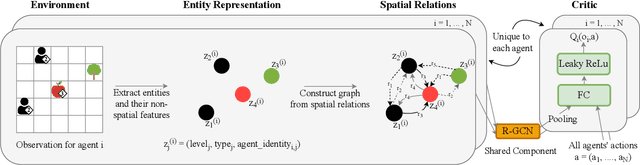
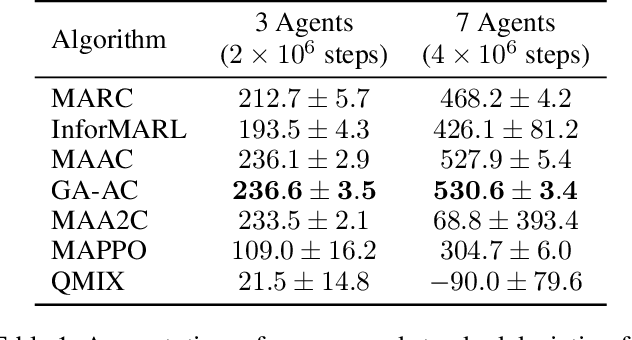
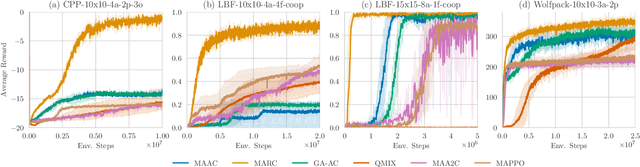
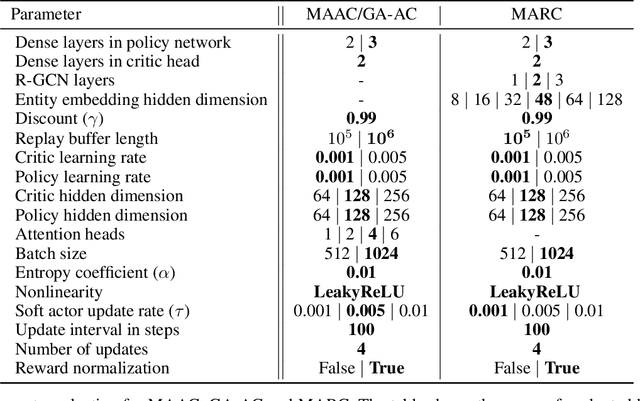
This paper explores the impact of relational state abstraction on sample efficiency and performance in collaborative Multi-Agent Reinforcement Learning. The proposed abstraction is based on spatial relationships in environments where direct communication between agents is not allowed, leveraging the ubiquity of spatial reasoning in real-world multi-agent scenarios. We introduce MARC (Multi-Agent Relational Critic), a simple yet effective critic architecture incorporating spatial relational inductive biases by transforming the state into a spatial graph and processing it through a relational graph neural network. The performance of MARC is evaluated across six collaborative tasks, including a novel environment with heterogeneous agents. We conduct a comprehensive empirical analysis, comparing MARC against state-of-the-art MARL baselines, demonstrating improvements in both sample efficiency and asymptotic performance, as well as its potential for generalization. Our findings suggest that a minimal integration of spatial relational inductive biases as abstraction can yield substantial benefits without requiring complex designs or task-specific engineering. This work provides insights into the potential of relational state abstraction to address sample efficiency, a key challenge in MARL, offering a promising direction for developing more efficient algorithms in spatially complex environments.