 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn approach based on metaheuristic algorithms to the timetabling problem in deregulated railway markets
Apr 24, 2025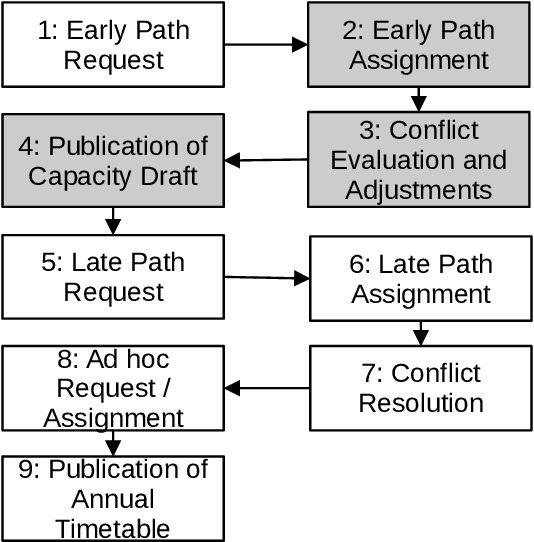
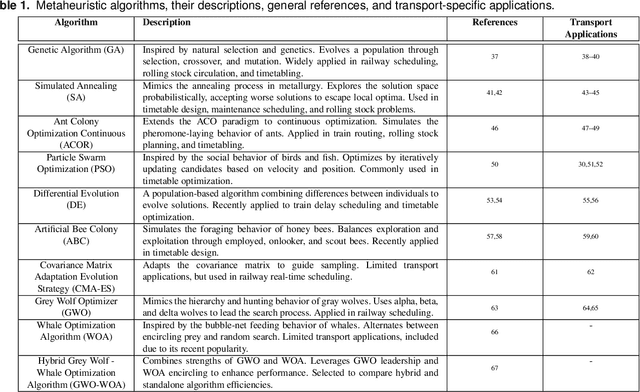

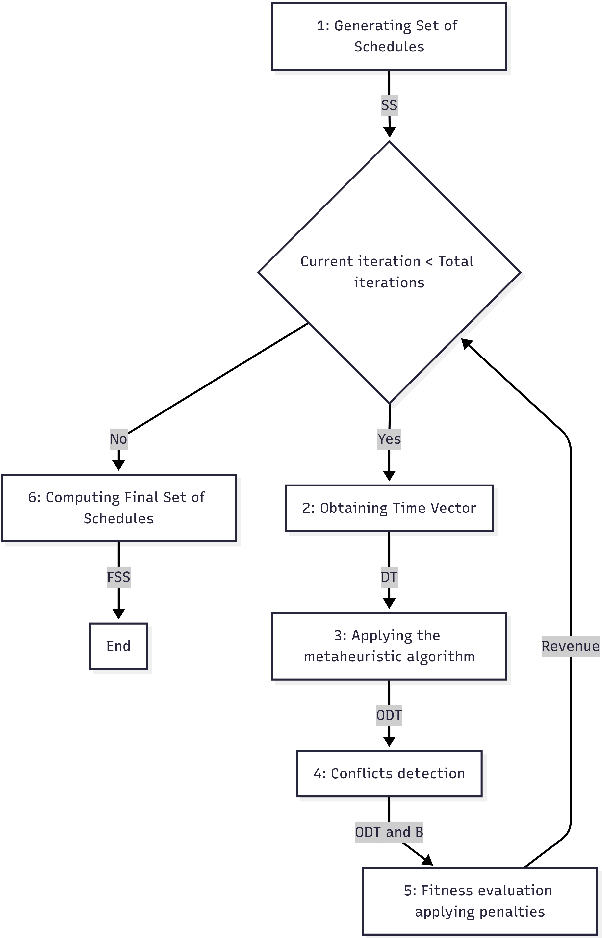
The train timetabling problem in liberalized railway markets represents a challenge to the coordination between infrastructure managers and railway undertakings. Efficient scheduling is critical in maximizing infrastructure capacity and utilization while adhering as closely as possible to the requests of railway undertakings. These objectives ultimately contribute to maximizing the infrastructure manager's revenues. This paper sets out a modular simulation framework to reproduce the dynamics of deregulated railway systems. Ten metaheuristic algorithms using the MEALPY Python library are then evaluated in order to optimize train schedules in the liberalized Spanish railway market. The results show that the Genetic Algorithm outperforms others in revenue optimization, convergence speed, and schedule adherence. Alternatives, such as Particle Swarm Optimization and Ant Colony Optimization Continuous, show slower convergence and higher variability. The results emphasize the trade-off between scheduling more trains and adhering to requested times, providing insights into solving complex scheduling problems in deregulated railway systems.
Dynamic Pricing in High-Speed Railways Using Multi-Agent Reinforcement Learning
Jan 14, 2025This paper addresses a critical challenge in the high-speed passenger railway industry: designing effective dynamic pricing strategies in the context of competing and cooperating operators. To address this, a multi-agent reinforcement learning (MARL) framework based on a non-zero-sum Markov game is proposed, incorporating random utility models to capture passenger decision making. Unlike prior studies in areas such as energy, airlines, and mobile networks, dynamic pricing for railway systems using deep reinforcement learning has received limited attention. A key contribution of this paper is a parametrisable and versatile reinforcement learning simulator designed to model a variety of railway network configurations and demand patterns while enabling realistic, microscopic modelling of user behaviour, called RailPricing-RL. This environment supports the proposed MARL framework, which models heterogeneous agents competing to maximise individual profits while fostering cooperative behaviour to synchronise connecting services. Experimental results validate the framework, demonstrating how user preferences affect MARL performance and how pricing policies influence passenger choices, utility, and overall system dynamics. This study provides a foundation for advancing dynamic pricing strategies in railway systems, aligning profitability with system-wide efficiency, and supporting future research on optimising pricing policies.
Scalable Kernel Logistic Regression with Nyström Approximation: Theoretical Analysis and Application to Discrete Choice Modelling
Feb 09, 2024The application of kernel-based Machine Learning (ML) techniques to discrete choice modelling using large datasets often faces challenges due to memory requirements and the considerable number of parameters involved in these models. This complexity hampers the efficient training of large-scale models. This paper addresses these problems of scalability by introducing the Nystr\"om approximation for Kernel Logistic Regression (KLR) on large datasets. The study begins by presenting a theoretical analysis in which: i) the set of KLR solutions is characterised, ii) an upper bound to the solution of KLR with Nystr\"om approximation is provided, and finally iii) a specialisation of the optimisation algorithms to Nystr\"om KLR is described. After this, the Nystr\"om KLR is computationally validated. Four landmark selection methods are tested, including basic uniform sampling, a k-means sampling strategy, and two non-uniform methods grounded in leverage scores. The performance of these strategies is evaluated using large-scale transport mode choice datasets and is compared with traditional methods such as Multinomial Logit (MNL) and contemporary ML techniques. The study also assesses the efficiency of various optimisation techniques for the proposed Nystr\"om KLR model. The performance of gradient descent, Momentum, Adam, and L-BFGS-B optimisation methods is examined on these datasets. Among these strategies, the k-means Nystr\"om KLR approach emerges as a successful solution for applying KLR to large datasets, particularly when combined with the L-BFGS-B and Adam optimisation methods. The results highlight the ability of this strategy to handle datasets exceeding 200,000 observations while maintaining robust performance.
A prediction and behavioural analysis of machine learning methods for modelling travel mode choice
Jan 11, 2023
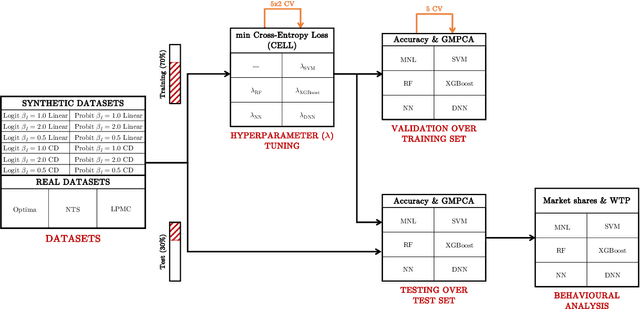

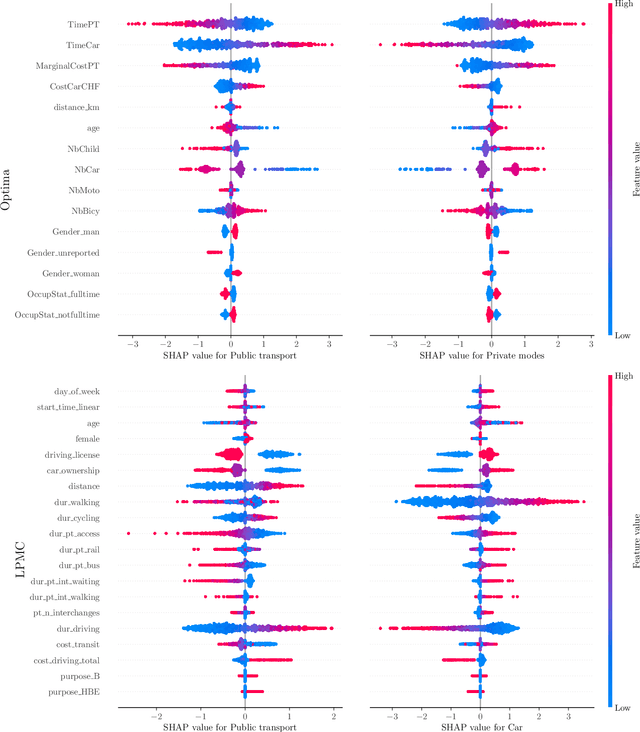
The emergence of a variety of Machine Learning (ML) approaches for travel mode choice prediction poses an interesting question to transport modellers: which models should be used for which applications? The answer to this question goes beyond simple predictive performance, and is instead a balance of many factors, including behavioural interpretability and explainability, computational complexity, and data efficiency. There is a growing body of research which attempts to compare the predictive performance of different ML classifiers with classical random utility models. However, existing studies typically analyse only the disaggregate predictive performance, ignoring other aspects affecting model choice. Furthermore, many studies are affected by technical limitations, such as the use of inappropriate validation schemes, incorrect sampling for hierarchical data, lack of external validation, and the exclusive use of discrete metrics. We address these limitations by conducting a systematic comparison of different modelling approaches, across multiple modelling problems, in terms of the key factors likely to affect model choice (out-of-sample predictive performance, accuracy of predicted market shares, extraction of behavioural indicators, and computational efficiency). We combine several real world datasets with synthetic datasets, where the data generation function is known. The results indicate that the models with the highest disaggregate predictive performance (namely extreme gradient boosting and random forests) provide poorer estimates of behavioural indicators and aggregate mode shares, and are more expensive to estimate, than other models, including deep neural networks and Multinomial Logit (MNL). It is further observed that the MNL model performs robustly in a variety of situations, though ML techniques can improve the estimates of behavioural indices such as Willingness to Pay.