 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling Activity Scheduling Behaviour with Deep Generative Machine Learning
Jan 17, 2025

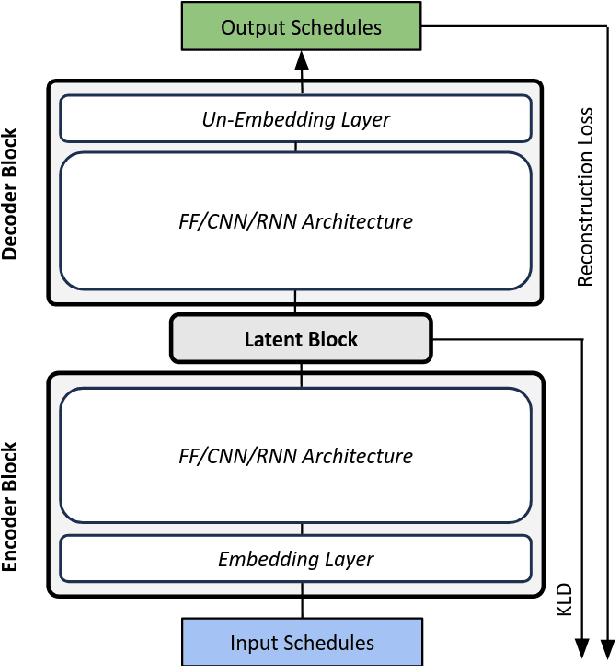

We model human activity scheduling behaviour using a deep generative machine learning approach. Activity schedules, which represent the activities and associated travel behaviours of individuals, are a core component of many applied models in the transport, energy and epidemiology domains. Our data driven approach learns human preferences and scheduling logic without the need for complex interacting combinations of sub-models and custom-rules, this makes our approach significantly faster and simpler to operate that existing approaches. We find activity schedule data combines aspects of both continuous image data and also discrete text data, requiring novel approaches. We additionally contribute a novel schedule representation and comprehensive evaluation framework for generated schedules. Evaluation shows our approach is able to rapidly generate large, diverse and realistic synthetic samples of activity schedules.
RUMBoost: Gradient Boosted Random Utility Models
Jan 22, 2024This paper introduces the RUMBoost model, a novel discrete choice modelling approach that combines the interpretability and behavioural robustness of Random Utility Models (RUMs) with the generalisation and predictive ability of deep learning methods. We obtain the full functional form of non-linear utility specifications by replacing each linear parameter in the utility functions of a RUM with an ensemble of gradient boosted regression trees. This enables piece-wise constant utility values to be imputed for all alternatives directly from the data for any possible combination of input variables. We introduce additional constraints on the ensembles to ensure three crucial features of the utility specifications: (i) dependency of the utilities of each alternative on only the attributes of that alternative, (ii) monotonicity of marginal utilities, and (iii) an intrinsically interpretable functional form, where the exact response of the model is known throughout the entire input space. Furthermore, we introduce an optimisation-based smoothing technique that replaces the piece-wise constant utility values of alternative attributes with monotonic piece-wise cubic splines to identify non-linear parameters with defined gradient. We demonstrate the potential of the RUMBoost model compared to various ML and Random Utility benchmark models for revealed preference mode choice data from London. The results highlight the great predictive performance and the direct interpretability of our proposed approach. Furthermore, the smoothed attribute utility functions allow for the calculation of various behavioural indicators and marginal utilities. Finally, we demonstrate the flexibility of our methodology by showing how the RUMBoost model can be extended to complex model specifications, including attribute interactions, correlation within alternative error terms and heterogeneity within the population.
A prediction and behavioural analysis of machine learning methods for modelling travel mode choice
Jan 11, 2023

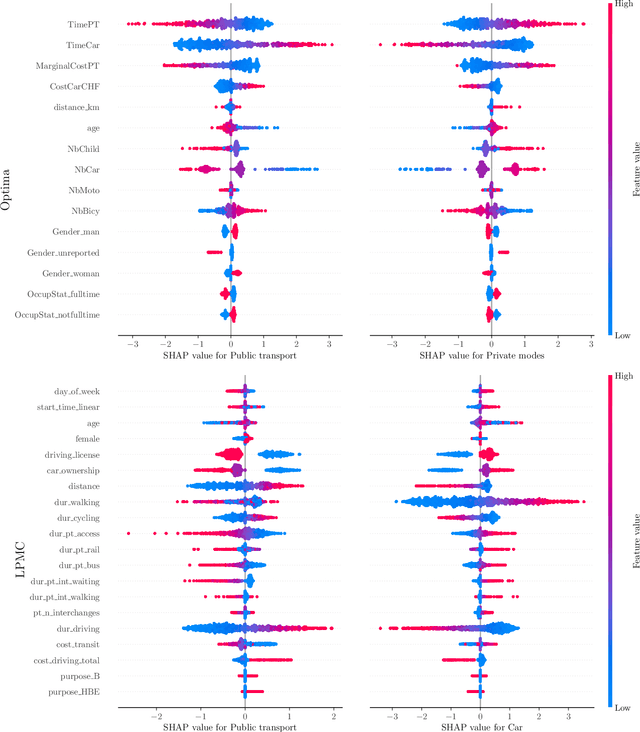
The emergence of a variety of Machine Learning (ML) approaches for travel mode choice prediction poses an interesting question to transport modellers: which models should be used for which applications? The answer to this question goes beyond simple predictive performance, and is instead a balance of many factors, including behavioural interpretability and explainability, computational complexity, and data efficiency. There is a growing body of research which attempts to compare the predictive performance of different ML classifiers with classical random utility models. However, existing studies typically analyse only the disaggregate predictive performance, ignoring other aspects affecting model choice. Furthermore, many studies are affected by technical limitations, such as the use of inappropriate validation schemes, incorrect sampling for hierarchical data, lack of external validation, and the exclusive use of discrete metrics. We address these limitations by conducting a systematic comparison of different modelling approaches, across multiple modelling problems, in terms of the key factors likely to affect model choice (out-of-sample predictive performance, accuracy of predicted market shares, extraction of behavioural indicators, and computational efficiency). We combine several real world datasets with synthetic datasets, where the data generation function is known. The results indicate that the models with the highest disaggregate predictive performance (namely extreme gradient boosting and random forests) provide poorer estimates of behavioural indicators and aggregate mode shares, and are more expensive to estimate, than other models, including deep neural networks and Multinomial Logit (MNL). It is further observed that the MNL model performs robustly in a variety of situations, though ML techniques can improve the estimates of behavioural indices such as Willingness to Pay.
ciDATGAN: Conditional Inputs for Tabular GANs
Oct 05, 2022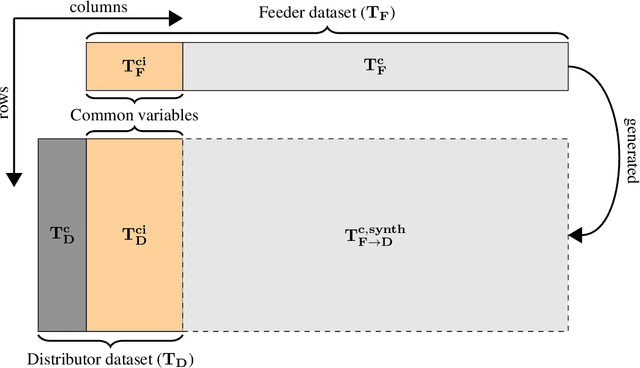

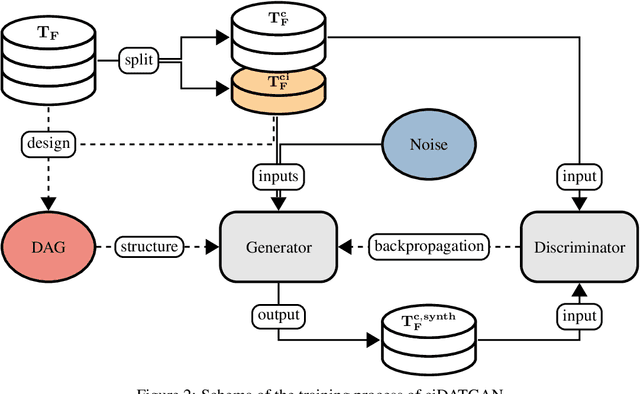

Conditionality has become a core component for Generative Adversarial Networks (GANs) for generating synthetic images. GANs are usually using latent conditionality to control the generation process. However, tabular data only contains manifest variables. Thus, latent conditionality either restricts the generated data or does not produce sufficiently good results. Therefore, we propose a new methodology to include conditionality in tabular GANs inspired by image completion methods. This article presents ciDATGAN, an evolution of the Directed Acyclic Tabular GAN (DATGAN) that has already been shown to outperform state-of-the-art tabular GAN models. First, we show that the addition of conditional inputs does hinder the model's performance compared to its predecessor. Then, we demonstrate that ciDATGAN can be used to unbias datasets with the help of well-chosen conditional inputs. Finally, it shows that ciDATGAN can learn the logic behind the data and, thus, be used to complete large synthetic datasets using data from a smaller feeder dataset.
DATGAN: Integrating expert knowledge into deep learning for synthetic tabular data
Mar 07, 2022



Synthetic data can be used in various applications, such as correcting bias datasets or replacing scarce original data for simulation purposes. Generative Adversarial Networks (GANs) are considered state-of-the-art for developing generative models. However, these deep learning models are data-driven, and it is, thus, difficult to control the generation process. It can, therefore, lead to the following issues: lack of representativity in the generated data, the introduction of bias, and the possibility of overfitting the sample's noise. This article presents the Directed Acyclic Tabular GAN (DATGAN) to address these limitations by integrating expert knowledge in deep learning models for synthetic tabular data generation. This approach allows the interactions between variables to be specified explicitly using a Directed Acyclic Graph (DAG). The DAG is then converted to a network of modified Long Short-Term Memory (LSTM) cells to accept multiple inputs. Multiple DATGAN versions are systematically tested on multiple assessment metrics. We show that the best versions of the DATGAN outperform state-of-the-art generative models on multiple case studies. Finally, we show how the DAG can create hypothetical synthetic datasets.