 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA prediction and behavioural analysis of machine learning methods for modelling travel mode choice
Paper and Code

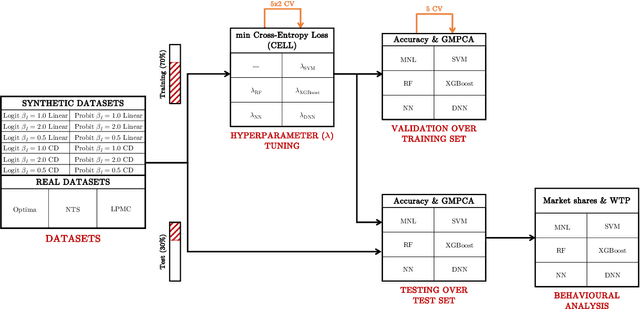

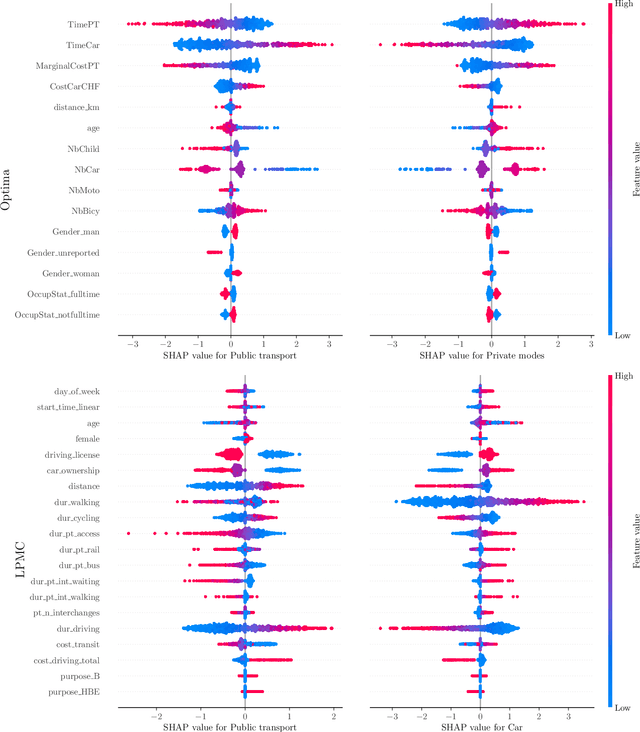
The emergence of a variety of Machine Learning (ML) approaches for travel mode choice prediction poses an interesting question to transport modellers: which models should be used for which applications? The answer to this question goes beyond simple predictive performance, and is instead a balance of many factors, including behavioural interpretability and explainability, computational complexity, and data efficiency. There is a growing body of research which attempts to compare the predictive performance of different ML classifiers with classical random utility models. However, existing studies typically analyse only the disaggregate predictive performance, ignoring other aspects affecting model choice. Furthermore, many studies are affected by technical limitations, such as the use of inappropriate validation schemes, incorrect sampling for hierarchical data, lack of external validation, and the exclusive use of discrete metrics. We address these limitations by conducting a systematic comparison of different modelling approaches, across multiple modelling problems, in terms of the key factors likely to affect model choice (out-of-sample predictive performance, accuracy of predicted market shares, extraction of behavioural indicators, and computational efficiency). We combine several real world datasets with synthetic datasets, where the data generation function is known. The results indicate that the models with the highest disaggregate predictive performance (namely extreme gradient boosting and random forests) provide poorer estimates of behavioural indicators and aggregate mode shares, and are more expensive to estimate, than other models, including deep neural networks and Multinomial Logit (MNL). It is further observed that the MNL model performs robustly in a variety of situations, though ML techniques can improve the estimates of behavioural indices such as Willingness to Pay.