 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Kernel Logistic Regression with Nyström Approximation: Theoretical Analysis and Application to Discrete Choice Modelling
Feb 09, 2024The application of kernel-based Machine Learning (ML) techniques to discrete choice modelling using large datasets often faces challenges due to memory requirements and the considerable number of parameters involved in these models. This complexity hampers the efficient training of large-scale models. This paper addresses these problems of scalability by introducing the Nystr\"om approximation for Kernel Logistic Regression (KLR) on large datasets. The study begins by presenting a theoretical analysis in which: i) the set of KLR solutions is characterised, ii) an upper bound to the solution of KLR with Nystr\"om approximation is provided, and finally iii) a specialisation of the optimisation algorithms to Nystr\"om KLR is described. After this, the Nystr\"om KLR is computationally validated. Four landmark selection methods are tested, including basic uniform sampling, a k-means sampling strategy, and two non-uniform methods grounded in leverage scores. The performance of these strategies is evaluated using large-scale transport mode choice datasets and is compared with traditional methods such as Multinomial Logit (MNL) and contemporary ML techniques. The study also assesses the efficiency of various optimisation techniques for the proposed Nystr\"om KLR model. The performance of gradient descent, Momentum, Adam, and L-BFGS-B optimisation methods is examined on these datasets. Among these strategies, the k-means Nystr\"om KLR approach emerges as a successful solution for applying KLR to large datasets, particularly when combined with the L-BFGS-B and Adam optimisation methods. The results highlight the ability of this strategy to handle datasets exceeding 200,000 observations while maintaining robust performance.
A prediction and behavioural analysis of machine learning methods for modelling travel mode choice
Jan 11, 2023
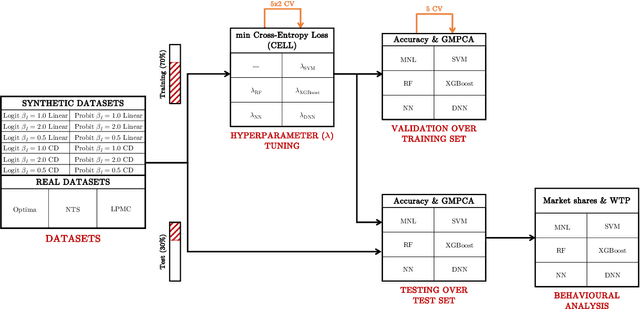

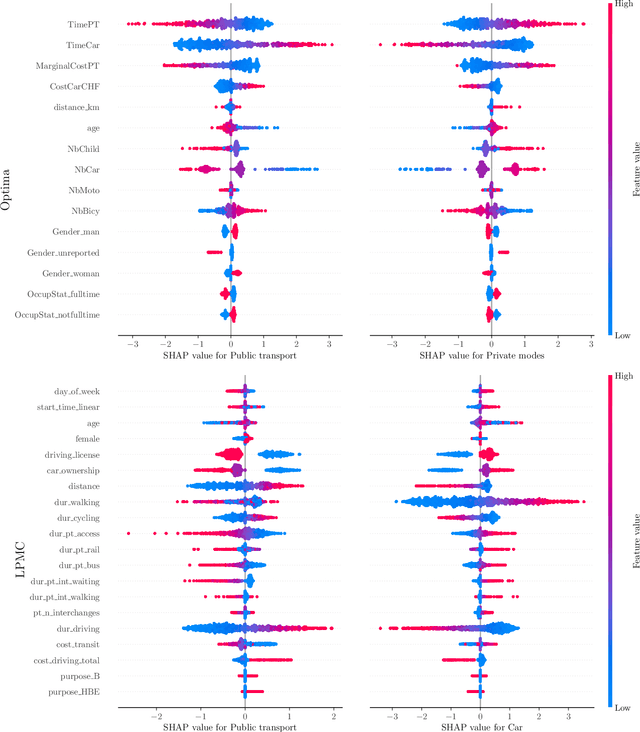
The emergence of a variety of Machine Learning (ML) approaches for travel mode choice prediction poses an interesting question to transport modellers: which models should be used for which applications? The answer to this question goes beyond simple predictive performance, and is instead a balance of many factors, including behavioural interpretability and explainability, computational complexity, and data efficiency. There is a growing body of research which attempts to compare the predictive performance of different ML classifiers with classical random utility models. However, existing studies typically analyse only the disaggregate predictive performance, ignoring other aspects affecting model choice. Furthermore, many studies are affected by technical limitations, such as the use of inappropriate validation schemes, incorrect sampling for hierarchical data, lack of external validation, and the exclusive use of discrete metrics. We address these limitations by conducting a systematic comparison of different modelling approaches, across multiple modelling problems, in terms of the key factors likely to affect model choice (out-of-sample predictive performance, accuracy of predicted market shares, extraction of behavioural indicators, and computational efficiency). We combine several real world datasets with synthetic datasets, where the data generation function is known. The results indicate that the models with the highest disaggregate predictive performance (namely extreme gradient boosting and random forests) provide poorer estimates of behavioural indicators and aggregate mode shares, and are more expensive to estimate, than other models, including deep neural networks and Multinomial Logit (MNL). It is further observed that the MNL model performs robustly in a variety of situations, though ML techniques can improve the estimates of behavioural indices such as Willingness to Pay.