 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Constrained Offline Reinforcement Learning
Paper and Code
May 23, 2024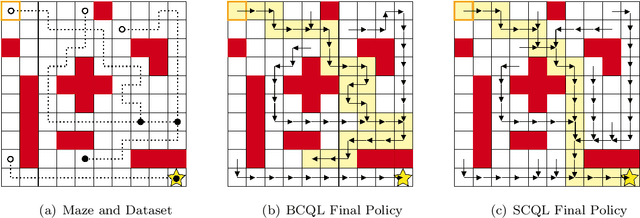

Traditional offline reinforcement learning methods predominantly operate in a batch-constrained setting. This confines the algorithms to a specific state-action distribution present in the dataset, reducing the effects of distributional shift but restricting the algorithm greatly. In this paper, we alleviate this limitation by introducing a novel framework named \emph{state-constrained} offline reinforcement learning. By exclusively focusing on the dataset's state distribution, our framework significantly enhances learning potential and reduces previous limitations. The proposed setting not only broadens the learning horizon but also improves the ability to combine different trajectories from the dataset effectively, a desirable property inherent in offline reinforcement learning. Our research is underpinned by solid theoretical findings that pave the way for subsequent advancements in this domain. Additionally, we introduce StaCQ, a deep learning algorithm that is both performance-driven on the D4RL benchmark datasets and closely aligned with our theoretical propositions. StaCQ establishes a strong baseline for forthcoming explorations in state-constrained offline reinforcement learning.