 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Based Smooth Policy Regularisation for Reinforcement Learning with Few Demonstrations
Sep 19, 2025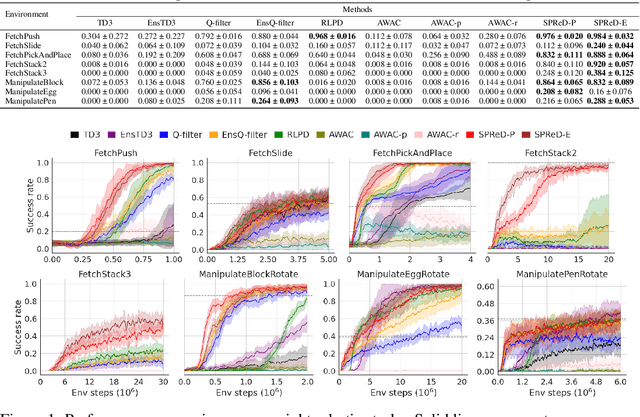
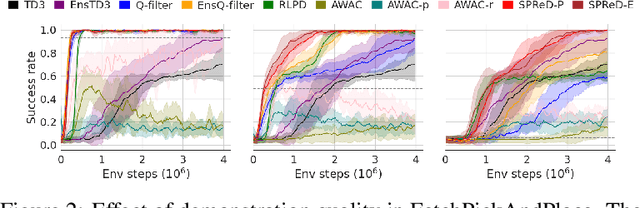


In reinforcement learning with sparse rewards, demonstrations can accelerate learning, but determining when to imitate them remains challenging. We propose Smooth Policy Regularisation from Demonstrations (SPReD), a framework that addresses the fundamental question: when should an agent imitate a demonstration versus follow its own policy? SPReD uses ensemble methods to explicitly model Q-value distributions for both demonstration and policy actions, quantifying uncertainty for comparisons. We develop two complementary uncertainty-aware methods: a probabilistic approach estimating the likelihood of demonstration superiority, and an advantage-based approach scaling imitation by statistical significance. Unlike prevailing methods (e.g. Q-filter) that make binary imitation decisions, SPReD applies continuous, uncertainty-proportional regularisation weights, reducing gradient variance during training. Despite its computational simplicity, SPReD achieves remarkable gains in experiments across eight robotics tasks, outperforming existing approaches by up to a factor of 14 in complex tasks while maintaining robustness to demonstration quality and quantity. Our code is available at https://github.com/YujieZhu7/SPReD.
State-Constrained Offline Reinforcement Learning
May 23, 2024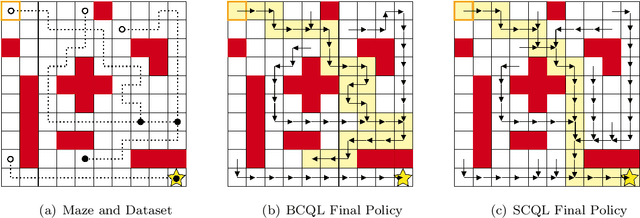

Traditional offline reinforcement learning methods predominantly operate in a batch-constrained setting. This confines the algorithms to a specific state-action distribution present in the dataset, reducing the effects of distributional shift but restricting the algorithm greatly. In this paper, we alleviate this limitation by introducing a novel framework named \emph{state-constrained} offline reinforcement learning. By exclusively focusing on the dataset's state distribution, our framework significantly enhances learning potential and reduces previous limitations. The proposed setting not only broadens the learning horizon but also improves the ability to combine different trajectories from the dataset effectively, a desirable property inherent in offline reinforcement learning. Our research is underpinned by solid theoretical findings that pave the way for subsequent advancements in this domain. Additionally, we introduce StaCQ, a deep learning algorithm that is both performance-driven on the D4RL benchmark datasets and closely aligned with our theoretical propositions. StaCQ establishes a strong baseline for forthcoming explorations in state-constrained offline reinforcement learning.
Model-based trajectory stitching for improved behavioural cloning and its applications
Dec 08, 2022Behavioural cloning (BC) is a commonly used imitation learning method to infer a sequential decision-making policy from expert demonstrations. However, when the quality of the data is not optimal, the resulting behavioural policy also performs sub-optimally once deployed. Recently, there has been a surge in offline reinforcement learning methods that hold the promise to extract high-quality policies from sub-optimal historical data. A common approach is to perform regularisation during training, encouraging updates during policy evaluation and/or policy improvement to stay close to the underlying data. In this work, we investigate whether an offline approach to improving the quality of the existing data can lead to improved behavioural policies without any changes in the BC algorithm. The proposed data improvement approach - Trajectory Stitching (TS) - generates new trajectories (sequences of states and actions) by `stitching' pairs of states that were disconnected in the original data and generating their connecting new action. By construction, these new transitions are guaranteed to be highly plausible according to probabilistic models of the environment, and to improve a state-value function. We demonstrate that the iterative process of replacing old trajectories with new ones incrementally improves the underlying behavioural policy. Extensive experimental results show that significant performance gains can be achieved using TS over BC policies extracted from the original data. Furthermore, using the D4RL benchmarking suite, we demonstrate that state-of-the-art results are obtained by combining TS with two existing offline learning methodologies reliant on BC, model-based offline planning (MBOP) and policy constraint (TD3+BC).
Model-based Trajectory Stitching for Improved Offline Reinforcement Learning
Nov 21, 2022In many real-world applications, collecting large and high-quality datasets may be too costly or impractical. Offline reinforcement learning (RL) aims to infer an optimal decision-making policy from a fixed set of data. Getting the most information from historical data is then vital for good performance once the policy is deployed. We propose a model-based data augmentation strategy, Trajectory Stitching (TS), to improve the quality of sub-optimal historical trajectories. TS introduces unseen actions joining previously disconnected states: using a probabilistic notion of state reachability, it effectively `stitches' together parts of the historical demonstrations to generate new, higher quality ones. A stitching event consists of a transition between a pair of observed states through a synthetic and highly probable action. New actions are introduced only when they are expected to be beneficial, according to an estimated state-value function. We show that using this data augmentation strategy jointly with behavioural cloning (BC) leads to improvements over the behaviour-cloned policy from the original dataset. Improving over the BC policy could then be used as a launchpad for online RL through planning and demonstration-guided RL.