 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of Offline Reinforcement Learning in Factorisable Action Spaces
Nov 17, 2024Expanding reinforcement learning (RL) to offline domains generates promising prospects, particularly in sectors where data collection poses substantial challenges or risks. Pivotal to the success of transferring RL offline is mitigating overestimation bias in value estimates for state-action pairs absent from data. Whilst numerous approaches have been proposed in recent years, these tend to focus primarily on continuous or small-scale discrete action spaces. Factorised discrete action spaces, on the other hand, have received relatively little attention, despite many real-world problems naturally having factorisable actions. In this work, we undertake a formative investigation into offline reinforcement learning in factorisable action spaces. Using value-decomposition as formulated in DecQN as a foundation, we present the case for a factorised approach and conduct an extensive empirical evaluation of several offline techniques adapted to the factorised setting. In the absence of established benchmarks, we introduce a suite of our own comprising datasets of varying quality and task complexity. Advocating for reproducible research and innovation, we make all datasets available for public use alongside our code base.
REValueD: Regularised Ensemble Value-Decomposition for Factorisable Markov Decision Processes
Jan 16, 2024Discrete-action reinforcement learning algorithms often falter in tasks with high-dimensional discrete action spaces due to the vast number of possible actions. A recent advancement leverages value-decomposition, a concept from multi-agent reinforcement learning, to tackle this challenge. This study delves deep into the effects of this value-decomposition, revealing that whilst it curtails the over-estimation bias inherent to Q-learning algorithms, it amplifies target variance. To counteract this, we present an ensemble of critics to mitigate target variance. Moreover, we introduce a regularisation loss that helps to mitigate the effects that exploratory actions in one dimension can have on the value of optimal actions in other dimensions. Our novel algorithm, REValueD, tested on discretised versions of the DeepMind Control Suite tasks, showcases superior performance, especially in the challenging humanoid and dog tasks. We further dissect the factors influencing REValueD's performance, evaluating the significance of the regularisation loss and the scalability of REValueD with increasing sub-actions per dimension.
LeNSE: Learning To Navigate Subgraph Embeddings for Large-Scale Combinatorial Optimisation
May 20, 2022
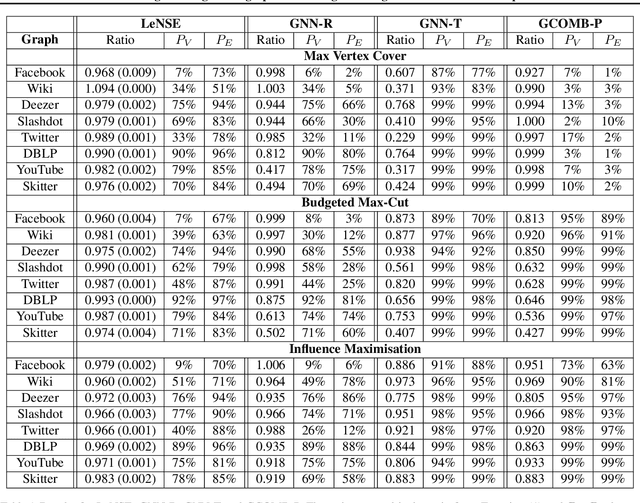


Combinatorial Optimisation problems arise in several application domains and are often formulated in terms of graphs. Many of these problems are NP-hard, but exact solutions are not always needed. Several heuristics have been developed to provide near-optimal solutions; however, they do not typically scale well with the size of the graph. We propose a low-complexity approach for identifying a (possibly much smaller) subgraph of the original graph where the heuristics can be run in reasonable time and with a high likelihood of finding a global near-optimal solution. The core component of our approach is LeNSE, a reinforcement learning algorithm that learns how to navigate the space of possible subgraphs using an Euclidean subgraph embedding as its map. To solve CO problems, LeNSE is provided with a discriminative embedding trained using any existing heuristics using only on a small portion of the original graph. When tested on three problems (vertex cover, max-cut and influence maximisation) using real graphs with up to $10$ million edges, LeNSE identifies small subgraphs yielding solutions comparable to those found by running the heuristics on the entire graph, but at a fraction of the total run time.