 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Verified Machine Unlearning For Distillation
Mar 28, 2025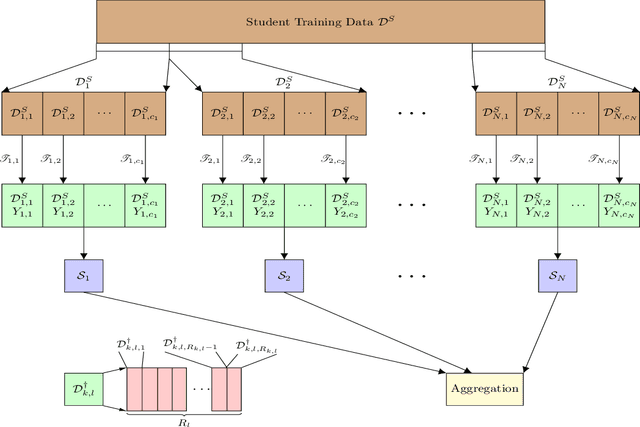
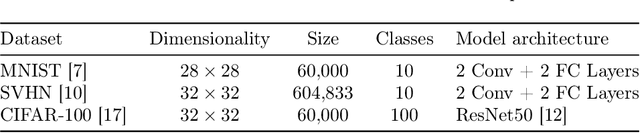
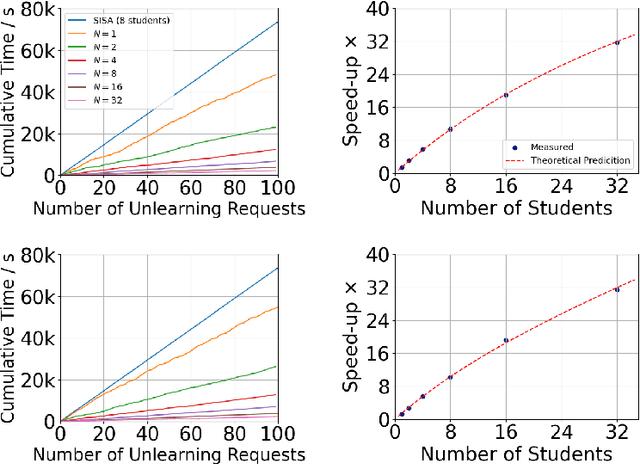
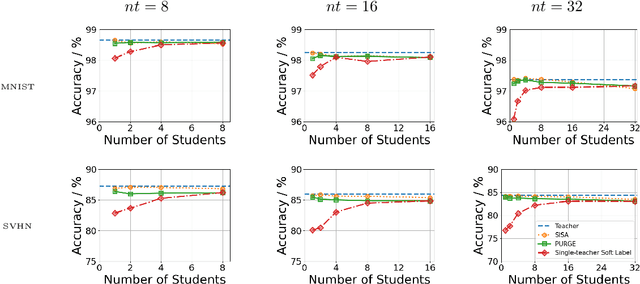
Growing data privacy demands, driven by regulations like GDPR and CCPA, require machine unlearning methods capable of swiftly removing the influence of specific training points. Although verified approaches like SISA, using data slicing and checkpointing, achieve efficient unlearning for single models by reverting to intermediate states, these methods struggle in teacher-student knowledge distillation settings. Unlearning in the teacher typically forces costly, complete student retraining due to pervasive information propagation during distillation. Our primary contribution is PURGE (Partitioned Unlearning with Retraining Guarantee for Ensembles), a novel framework integrating verified unlearning with distillation. We introduce constituent mapping and an incremental multi-teacher strategy that partitions the distillation process, confines each teacher constituent's impact to distinct student data subsets, and crucially maintains data isolation. The PURGE framework substantially reduces retraining overhead, requiring only partial student updates when teacher-side unlearning occurs. We provide both theoretical analysis, quantifying significant speed-ups in the unlearning process, and empirical validation on multiple datasets, demonstrating that PURGE achieves these efficiency gains while maintaining student accuracy comparable to standard baselines.