 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Scenario-based Decision-making for Interactive Autonomous Driving Using Rational Criteria: A Survey
Jan 03, 2025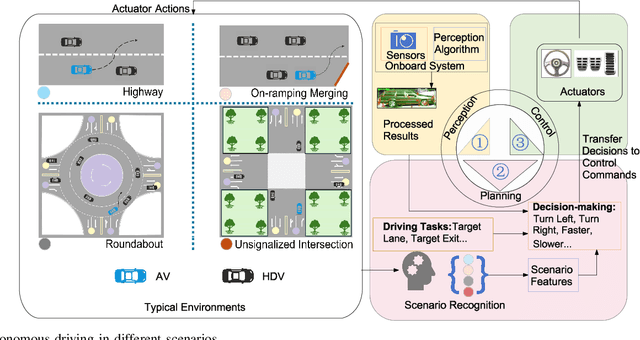
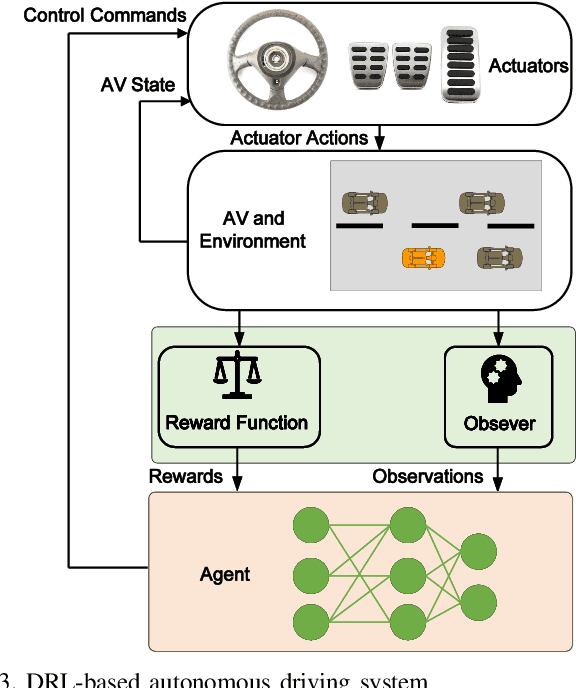
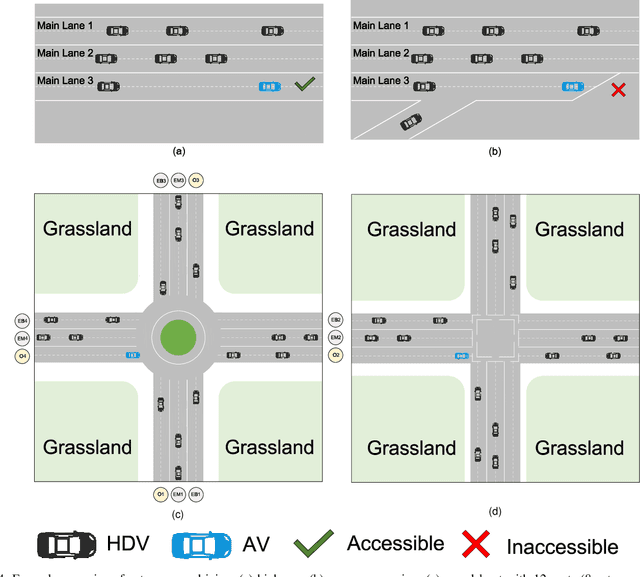
Autonomous vehicles (AVs) can significantly promote the advances in road transport mobility in terms of safety, reliability, and decarbonization. However, ensuring safety and efficiency in interactive during within dynamic and diverse environments is still a primary barrier to large-scale AV adoption. In recent years, deep reinforcement learning (DRL) has emerged as an advanced AI-based approach, enabling AVs to learn decision-making strategies adaptively from data and interactions. DRL strategies are better suited than traditional rule-based methods for handling complex, dynamic, and unpredictable driving environments due to their adaptivity. However, varying driving scenarios present distinct challenges, such as avoiding obstacles on highways and reaching specific exits at intersections, requiring different scenario-specific decision-making algorithms. Many DRL algorithms have been proposed in interactive decision-making. However, a rationale review of these DRL algorithms across various scenarios is lacking. Therefore, a comprehensive evaluation is essential to assess these algorithms from multiple perspectives, including those of vehicle users and vehicle manufacturers. This survey reviews the application of DRL algorithms in autonomous driving across typical scenarios, summarizing road features and recent advancements. The scenarios include highways, on-ramp merging, roundabouts, and unsignalized intersections. Furthermore, DRL-based algorithms are evaluated based on five rationale criteria: driving safety, driving efficiency, training efficiency, unselfishness, and interpretability (DDTUI). Each criterion of DDTUI is specifically analyzed in relation to the reviewed algorithms. Finally, the challenges for future DRL-based decision-making algorithms are summarized.
Multi-scale Feature Fusion with Point Pyramid for 3D Object Detection
Sep 06, 2024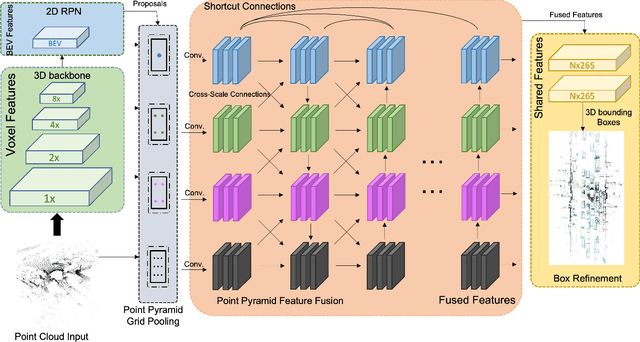
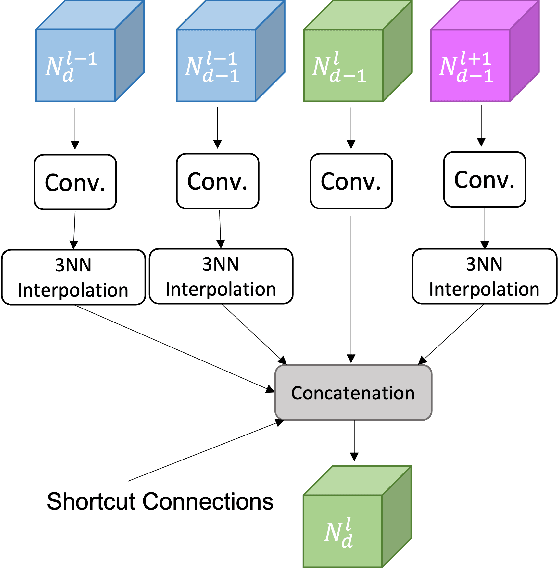
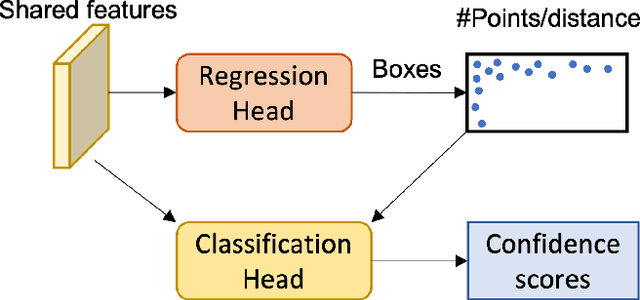

Effective point cloud processing is crucial to LiDARbased autonomous driving systems. The capability to understand features at multiple scales is required for object detection of intelligent vehicles, where road users may appear in different sizes. Recent methods focus on the design of the feature aggregation operators, which collect features at different scales from the encoder backbone and assign them to the points of interest. While efforts are made into the aggregation modules, the importance of how to fuse these multi-scale features has been overlooked. This leads to insufficient feature communication across scales. To address this issue, this paper proposes the Point Pyramid RCNN (POP-RCNN), a feature pyramid-based framework for 3D object detection on point clouds. POP-RCNN consists of a Point Pyramid Feature Enhancement (PPFE) module to establish connections across spatial scales and semantic depths for information exchange. The PPFE module effectively fuses multi-scale features for rich information without the increased complexity in feature aggregation. To remedy the impact of inconsistent point densities, a point density confidence module is deployed. This design integration enables the use of a lightweight feature aggregator, and the emphasis on both shallow and deep semantics, realising a detection framework for 3D object detection. With great adaptability, the proposed method can be applied to a variety of existing frameworks to increase feature richness, especially for long-distance detection. By adopting the PPFE in the voxel-based and point-voxel-based baselines, experimental results on KITTI and Waymo Open Dataset show that the proposed method achieves remarkable performance even with limited computational headroom.
Single-shot fast 3D imaging through scattering media using structured illumination
Oct 23, 2021
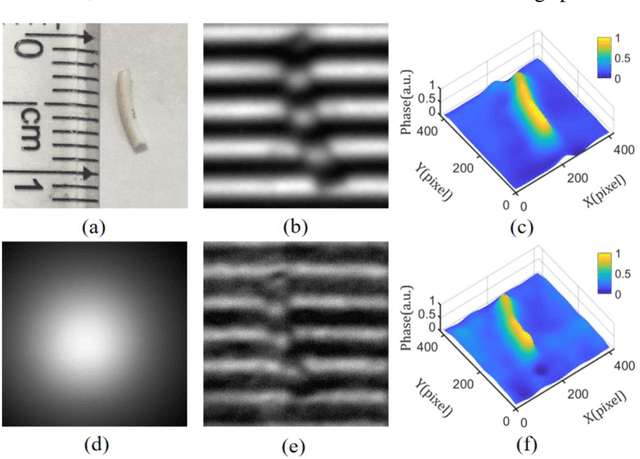


Conventional approaches for 3D imaging in or through scattering media are usually limited to 2D reconstruction of objects at some discontinuous locations, although the time-consuming iteration, guide-star, or complex system are implemented. How to quickly visualize dynamic 3D objects behind scattering media is still an open issue. Here, by using structured light illumination, we propose a single-shot technique that can quickly acquire continuous 3D surfaces of objects hidden behind the diffuser. The proposed method can realize the 3D imaging of single, multiple, and dynamic targets from the speckled structured light patterns under broad or narrow band light illumination, in which only once calibration of the imaging setup is needed before conducting the imaging. Our approach paves the way to quickly visualize dynamic objects behind scattering media in 3D and multispectral.
Utilizing Import Vector Machines to Identify Dangerous Pro-active Traffic Conditions
Jan 19, 2021



Traffic accidents have been a severe issue in metropolises with the development of traffic flow. This paper explores the theory and application of a recently developed machine learning technique, namely Import Vector Machines (IVMs), in real-time crash risk analysis, which is a hot topic to reduce traffic accidents. Historical crash data and corresponding traffic data from Shanghai Urban Expressway System were employed and matched. Traffic conditions are labelled as dangerous (i.e. probably leading to a crash) and safe (i.e. a normal traffic condition) based on 5-minute measurements of average speed, volume and occupancy. The IVM algorithm is trained to build the classifier and its performance is compared to the popular and successfully applied technique of Support Vector Machines (SVMs). The main findings indicate that IVMs could successfully be employed in real-time identification of dangerous pro-active traffic conditions. Furthermore, similar to the "support points" of the SVM, the IVM model uses only a fraction of the training data to index kernel basis functions, typically a much smaller fraction than the SVM, and its classification rates are similar to those of SVMs. This gives the IVM a computational advantage over the SVM, especially when the size of the training data set is large.
* 6 pages, 3 figures, 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC)