 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Attention as Compact Kernel Regression
Jan 30, 2026Recent work has revealed a link between self-attention mechanisms in transformers and test-time kernel regression via the Nadaraya-Watson estimator, with standard softmax attention corresponding to a Gaussian kernel. However, a kernel-theoretic understanding of sparse attention mechanisms is currently missing. In this paper, we establish a formal correspondence between sparse attention and compact (bounded support) kernels. We show that normalized ReLU and sparsemax attention arise from Epanechnikov kernel regression under fixed and adaptive normalizations, respectively. More generally, we demonstrate that widely used kernels in nonparametric density estimation -- including Epanechnikov, biweight, and triweight -- correspond to $α$-entmax attention with $α= 1 + \frac{1}{n}$ for $n \in \mathbb{N}$, while the softmax/Gaussian relationship emerges in the limit $n \to \infty$. This unified perspective explains how sparsity naturally emerges from kernel design and provides principled alternatives to heuristic top-$k$ attention and other associative memory mechanisms. Experiments with a kernel-regression-based variant of transformers -- Memory Mosaics -- show that kernel-based sparse attention achieves competitive performance on language modeling, in-context learning, and length generalization tasks, offering a principled framework for designing attention mechanisms.
Geometric implicit neural representations for signed distance functions
Nov 10, 2025\textit{Implicit neural representations} (INRs) have emerged as a promising framework for representing signals in low-dimensional spaces. This survey reviews the existing literature on the specialized INR problem of approximating \textit{signed distance functions} (SDFs) for surface scenes, using either oriented point clouds or a set of posed images. We refer to neural SDFs that incorporate differential geometry tools, such as normals and curvatures, in their loss functions as \textit{geometric} INRs. The key idea behind this 3D reconstruction approach is to include additional \textit{regularization} terms in the loss function, ensuring that the INR satisfies certain global properties that the function should hold -- such as having unit gradient in the case of SDFs. We explore key methodological components, including the definition of INR, the construction of geometric loss functions, and sampling schemes from a differential geometry perspective. Our review highlights the significant advancements enabled by geometric INRs in surface reconstruction from oriented point clouds and posed images.
FLOWING: Implicit Neural Flows for Structure-Preserving Morphing
Oct 10, 2025



Morphing is a long-standing problem in vision and computer graphics, requiring a time-dependent warping for feature alignment and a blending for smooth interpolation. Recently, multilayer perceptrons (MLPs) have been explored as implicit neural representations (INRs) for modeling such deformations, due to their meshlessness and differentiability; however, extracting coherent and accurate morphings from standard MLPs typically relies on costly regularizations, which often lead to unstable training and prevent effective feature alignment. To overcome these limitations, we propose FLOWING (FLOW morphING), a framework that recasts warping as the construction of a differential vector flow, naturally ensuring continuity, invertibility, and temporal coherence by encoding structural flow properties directly into the network architectures. This flow-centric approach yields principled and stable transformations, enabling accurate and structure-preserving morphing of both 2D images and 3D shapes. Extensive experiments across a range of applications - including face and image morphing, as well as Gaussian Splatting morphing - show that FLOWING achieves state-of-the-art morphing quality with faster convergence. Code and pretrained models are available at http://schardong.github.io/flowing.
VOIDFace: A Privacy-Preserving Multi-Network Face Recognition With Enhanced Security
Aug 11, 2025
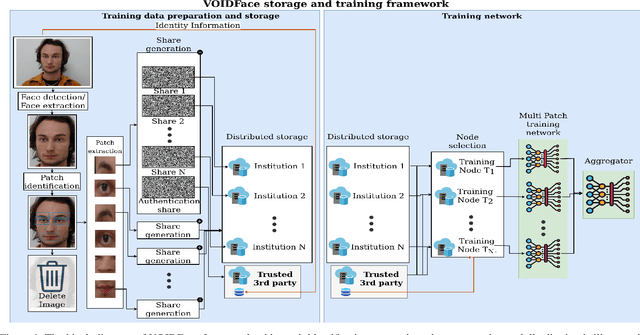


Advancement of machine learning techniques, combined with the availability of large-scale datasets, has significantly improved the accuracy and efficiency of facial recognition. Modern facial recognition systems are trained using large face datasets collected from diverse individuals or public repositories. However, for training, these datasets are often replicated and stored in multiple workstations, resulting in data replication, which complicates database management and oversight. Currently, once a user submits their face for dataset preparation, they lose control over how their data is used, raising significant privacy and ethical concerns. This paper introduces VOIDFace, a novel framework for facial recognition systems that addresses two major issues. First, it eliminates the need of data replication and improves data control to securely store training face data by using visual secret sharing. Second, it proposes a patch-based multi-training network that uses this novel training data storage mechanism to develop a robust, privacy-preserving facial recognition system. By integrating these advancements, VOIDFace aims to improve the privacy, security, and efficiency of facial recognition training, while ensuring greater control over sensitive personal face data. VOIDFace also enables users to exercise their Right-To-Be-Forgotten property to control their personal data. Experimental evaluations on the VGGFace2 dataset show that VOIDFace provides Right-To-Be-Forgotten, improved data control, security, and privacy while maintaining competitive facial recognition performance. Code is available at: https://github.com/ajnasmuhammed89/VOIDFace
Second Competition on Presentation Attack Detection on ID Card
Jul 27, 2025This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.
AdaSplash: Adaptive Sparse Flash Attention
Feb 17, 2025The computational cost of softmax-based attention in transformers limits their applicability to long-context tasks. Adaptive sparsity, of which $\alpha$-entmax attention is an example, offers a flexible data-dependent alternative, but existing implementations are inefficient and do not leverage the sparsity to obtain runtime and memory gains. In this work, we propose AdaSplash, which combines the efficiency of GPU-optimized algorithms with the sparsity benefits of $\alpha$-entmax. We first introduce a hybrid Halley-bisection algorithm, resulting in a 7-fold reduction in the number of iterations needed to compute the $\alpha$-entmax transformation. Then, we implement custom Triton kernels to efficiently handle adaptive sparsity. Experiments with RoBERTa and ModernBERT for text classification and single-vector retrieval, along with GPT-2 for language modeling, show that our method achieves substantial improvements in runtime and memory efficiency compared to existing $\alpha$-entmax implementations. It approaches -- and in some cases surpasses -- the efficiency of highly optimized softmax implementations like FlashAttention-2, enabling long-context training while maintaining strong task performance.
Quadruplet Loss For Improving the Robustness to Face Morphing Attacks
Feb 22, 2024Recent advancements in deep learning have revolutionized technology and security measures, necessitating robust identification methods. Biometric approaches, leveraging personalized characteristics, offer a promising solution. However, Face Recognition Systems are vulnerable to sophisticated attacks, notably face morphing techniques, enabling the creation of fraudulent documents. In this study, we introduce a novel quadruplet loss function for increasing the robustness of face recognition systems against morphing attacks. Our approach involves specific sampling of face image quadruplets, combined with face morphs, for network training. Experimental results demonstrate the efficiency of our strategy in improving the robustness of face recognition networks against morphing attacks.
Impact of Image Context for Single Deep Learning Face Morphing Attack Detection
Sep 01, 2023



The increase in security concerns due to technological advancements has led to the popularity of biometric approaches that utilize physiological or behavioral characteristics for enhanced recognition. Face recognition systems (FRSs) have become prevalent, but they are still vulnerable to image manipulation techniques such as face morphing attacks. This study investigates the impact of the alignment settings of input images on deep learning face morphing detection performance. We analyze the interconnections between the face contour and image context and suggest optimal alignment conditions for face morphing detection.
Fused Classification For Differential Face Morphing Detection
Sep 01, 2023Face morphing, a sophisticated presentation attack technique, poses significant security risks to face recognition systems. Traditional methods struggle to detect morphing attacks, which involve blending multiple face images to create a synthetic image that can match different individuals. In this paper, we focus on the differential detection of face morphing and propose an extended approach based on fused classification method for no-reference scenario. We introduce a public face morphing detection benchmark for the differential scenario and utilize a specific data mining technique to enhance the performance of our approach. Experimental results demonstrate the effectiveness of our method in detecting morphing attacks.
Neural Implicit Morphing of Face Images
Aug 26, 2023Face morphing is one of the seminal problems in computer graphics, with numerous artistic and forensic applications. It is notoriously challenging due to pose, lighting, gender, and ethnicity variations. Generally, this task consists of a warping for feature alignment and a blending for a seamless transition between the warped images. We propose to leverage coordinate-based neural networks to represent such warpings and blendings of face images. During training, we exploit the smoothness and flexibility of such networks, by combining energy functionals employed in classical approaches without discretizations. Additionally, our method is time-dependent, allowing a continuous warping, and blending of the target images. During warping inference, we need both direct and inverse transformations of the time-dependent warping. The first is responsible for morphing the target image into the source image, while the inverse is used for morphing in the opposite direction. Our neural warping stores those maps in a single network due to its inversible property, dismissing the hard task of inverting them. The results of our experiments indicate that our method is competitive with both classical and data-based neural techniques under the lens of face-morphing detection approaches. Aesthetically, the resulting images present a seamless blending of diverse faces not yet usual in the literature.