 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying and Bridging the Fidelity Gap: A Decisive-Feature Approach to Comparing Synthetic and Real Imagery
Dec 18, 2025Virtual testing using synthetic data has become a cornerstone of autonomous vehicle (AV) safety assurance. Despite progress in improving visual realism through advanced simulators and generative AI, recent studies reveal that pixel-level fidelity alone does not ensure reliable transfer from simulation to the real world. What truly matters is whether the system-under-test (SUT) bases its decisions on the same causal evidence in both real and simulated environments - not just whether images "look real" to humans. This paper addresses the lack of such a behavior-grounded fidelity measure by introducing Decisive Feature Fidelity (DFF), a new SUT-specific metric that extends the existing fidelity spectrum to capture mechanism parity - the agreement in causal evidence underlying the SUT's decisions across domains. DFF leverages explainable-AI (XAI) methods to identify and compare the decisive features driving the SUT's outputs for matched real-synthetic pairs. We further propose practical estimators based on counterfactual explanations, along with a DFF-guided calibration scheme to enhance simulator fidelity. Experiments on 2126 matched KITTI-VirtualKITTI2 pairs demonstrate that DFF reveals discrepancies overlooked by conventional output-value fidelity. Furthermore, results show that DFF-guided calibration improves decisive-feature and input-level fidelity without sacrificing output value fidelity across diverse SUTs.
Uncertainty-Aware Measurement of Scenario Suite Representativeness for Autonomous Systems
Nov 18, 2025Assuring the trustworthiness and safety of AI systems, e.g., autonomous vehicles (AV), depends critically on the data-related safety properties, e.g., representativeness, completeness, etc., of the datasets used for their training and testing. Among these properties, this paper focuses on representativeness-the extent to which the scenario-based data used for training and testing, reflect the operational conditions that the system is designed to operate safely in, i.e., Operational Design Domain (ODD) or expected to encounter, i.e., Target Operational Domain (TOD). We propose a probabilistic method that quantifies representativeness by comparing the statistical distribution of features encoded by the scenario suites with the corresponding distribution of features representing the TOD, acknowledging that the true TOD distribution is unknown, as it can only be inferred from limited data. We apply an imprecise Bayesian method to handle limited data and uncertain priors. The imprecise Bayesian formulation produces interval-valued, uncertainty-aware estimates of representativeness, rather than a single value. We present a numerical example comparing the distributions of the scenario suite and the inferred TOD across operational categories-weather, road type, time of day, etc., under dependencies and prior uncertainty. We estimate representativeness locally (between categories) and globally as an interval.
Optimising Communication Control Factors for Energy Consumption in Rural LOS V2X
Oct 14, 2025Connected braking can reduce fatal collisions in connected and autonomous vehicles (CAVs) by using reliable, low-latency 5G New Radio (NR) links, especially NR Sidelink Vehicle-to-Everything (V2X). In rural areas, road side units are sparse and power-constrained or off-grid, so energy efficiency must be considered alongside safety. This paper studies how three communication control factors including subcarrier spacing ($\mathrm{SCS}$), modulation and coding scheme ($\mathrm{MCS}$), and transmit power ($P_{\mathrm{t}}$) should be configured to balance safety and energy consumption in rural line-of-sight (LOS) scenarios in light and heavy traffic scenarios. Safety is quantified by the packet receive ratio ($\mathrm{PRR}$) against the minimum communication distance $D_{\mathrm{comm}}$, defined as the distance that the vehicle travels during the transmission of the safety message. Results show that, under heavy traffic, increasing $P_{\mathrm{t}}$ and selecting a low-rate $\mathrm{MCS}$ at $\mathrm{SCS} = 30$ kHz sustains high $\mathrm{PRR}$ at $D_{\mathrm{comm}}$, albeit with higher energy cost. In light traffic, maintaining lower $P_\mathrm{t}$ with low $\mathrm{MCS}$ levels achieves a favorable reliability-energy trade-off while preserving acceptable $\mathrm{PRR}$ at $D_{\mathrm{comm}}$. These findings demonstrate the necessity of adaptive, energy-aware strategy to guarantee both safety and energy efficiency in rural V2X systems.
Trustworthy Text-to-Image Diffusion Models: A Timely and Focused Survey
Sep 26, 2024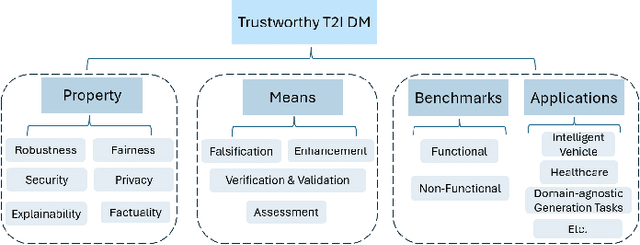
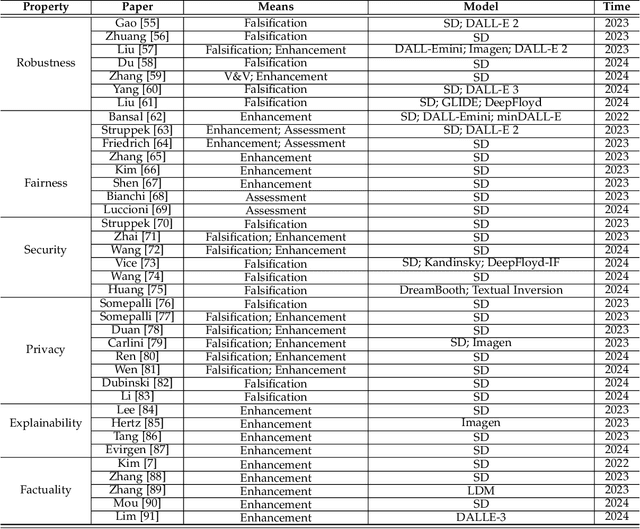
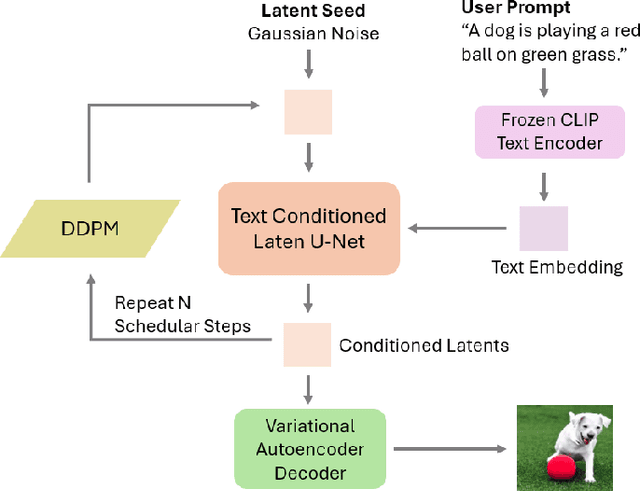
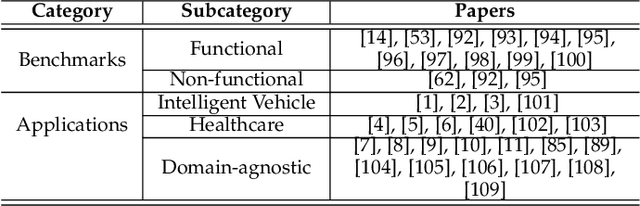
Text-to-Image (T2I) Diffusion Models (DMs) have garnered widespread attention for their impressive advancements in image generation. However, their growing popularity has raised ethical and social concerns related to key non-functional properties of trustworthiness, such as robustness, fairness, security, privacy, factuality, and explainability, similar to those in traditional deep learning (DL) tasks. Conventional approaches for studying trustworthiness in DL tasks often fall short due to the unique characteristics of T2I DMs, e.g., the multi-modal nature. Given the challenge, recent efforts have been made to develop new methods for investigating trustworthiness in T2I DMs via various means, including falsification, enhancement, verification \& validation and assessment. However, there is a notable lack of in-depth analysis concerning those non-functional properties and means. In this survey, we provide a timely and focused review of the literature on trustworthy T2I DMs, covering a concise-structured taxonomy from the perspectives of property, means, benchmarks and applications. Our review begins with an introduction to essential preliminaries of T2I DMs, and then we summarise key definitions/metrics specific to T2I tasks and analyses the means proposed in recent literature based on these definitions/metrics. Additionally, we review benchmarks and domain applications of T2I DMs. Finally, we highlight the gaps in current research, discuss the limitations of existing methods, and propose future research directions to advance the development of trustworthy T2I DMs. Furthermore, we keep up-to-date updates in this field to track the latest developments and maintain our GitHub repository at: https://github.com/wellzline/Trustworthy_T2I_DMs
ProTIP: Probabilistic Robustness Verification on Text-to-Image Diffusion Models against Stochastic Perturbation
Feb 23, 2024



Text-to-Image (T2I) Diffusion Models (DMs) have shown impressive abilities in generating high-quality images based on simple text descriptions. However, as is common with many Deep Learning (DL) models, DMs are subject to a lack of robustness. While there are attempts to evaluate the robustness of T2I DMs as a binary or worst-case problem, they cannot answer how robust in general the model is whenever an adversarial example (AE) can be found. In this study, we first introduce a probabilistic notion of T2I DMs' robustness; and then establish an efficient framework, ProTIP, to evaluate it with statistical guarantees. The main challenges stem from: i) the high computational cost of the generation process; and ii) determining if a perturbed input is an AE involves comparing two output distributions, which is fundamentally harder compared to other DL tasks like classification where an AE is identified upon misprediction of labels. To tackle the challenges, we employ sequential analysis with efficacy and futility early stopping rules in the statistical testing for identifying AEs, and adaptive concentration inequalities to dynamically determine the "just-right" number of stochastic perturbations whenever the verification target is met. Empirical experiments validate the effectiveness and efficiency of ProTIP over common T2I DMs. Finally, we demonstrate an application of ProTIP to rank commonly used defence methods.
Domain Knowledge Distillation from Large Language Model: An Empirical Study in the Autonomous Driving Domain
Jul 17, 2023



Engineering knowledge-based (or expert) systems require extensive manual effort and domain knowledge. As Large Language Models (LLMs) are trained using an enormous amount of cross-domain knowledge, it becomes possible to automate such engineering processes. This paper presents an empirical automation and semi-automation framework for domain knowledge distillation using prompt engineering and the LLM ChatGPT. We assess the framework empirically in the autonomous driving domain and present our key observations. In our implementation, we construct the domain knowledge ontology by "chatting" with ChatGPT. The key finding is that while fully automated domain ontology construction is possible, human supervision and early intervention typically improve efficiency and output quality as they lessen the effects of response randomness and the butterfly effect. We, therefore, also develop a web-based distillation assistant enabling supervision and flexible intervention at runtime. We hope our findings and tools could inspire future research toward revolutionizing the engineering of knowledge-based systems across application domains.