 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEGNet: A Physics-Embedded Graph Network for Long-Term Stable Multiphysics Simulation
Nov 11, 2025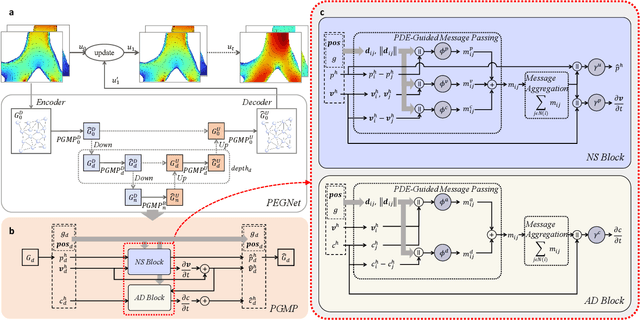
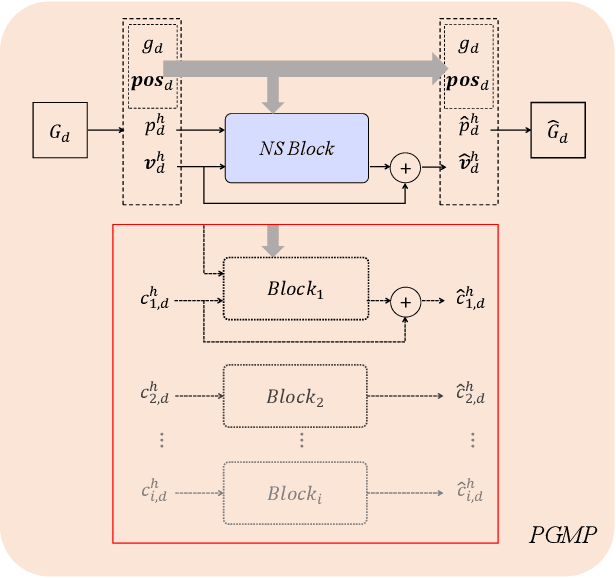
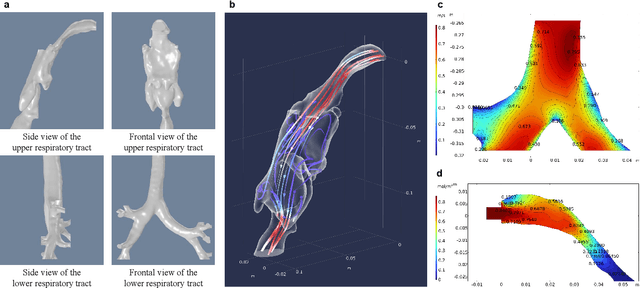
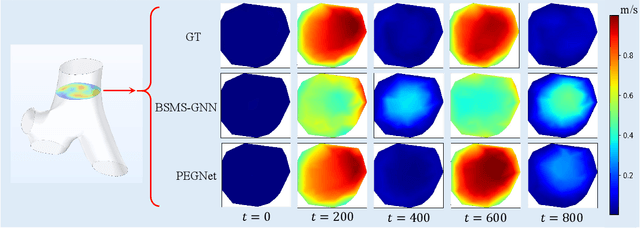
Accurate and efficient simulations of physical phenomena governed by partial differential equations (PDEs) are important for scientific and engineering progress. While traditional numerical solvers are powerful, they are often computationally expensive. Recently, data-driven methods have emerged as alternatives, but they frequently suffer from error accumulation and limited physical consistency, especially in multiphysics and complex geometries. To address these challenges, we propose PEGNet, a Physics-Embedded Graph Network that incorporates PDE-guided message passing to redesign the graph neural network architecture. By embedding key PDE dynamics like convection, viscosity, and diffusion into distinct message functions, the model naturally integrates physical constraints into its forward propagation, producing more stable and physically consistent solutions. Additionally, a hierarchical architecture is employed to capture multi-scale features, and physical regularization is integrated into the loss function to further enforce adherence to governing physics. We evaluated PEGNet on benchmarks, including custom datasets for respiratory airflow and drug delivery, showing significant improvements in long-term prediction accuracy and physical consistency over existing methods. Our code is available at https://github.com/Yanghuoshan/PEGNet.
Cross-Modality Attack Boosted by Gradient-Evolutionary Multiform Optimization
Sep 26, 2024



In recent years, despite significant advancements in adversarial attack research, the security challenges in cross-modal scenarios, such as the transferability of adversarial attacks between infrared, thermal, and RGB images, have been overlooked. These heterogeneous image modalities collected by different hardware devices are widely prevalent in practical applications, and the substantial differences between modalities pose significant challenges to attack transferability. In this work, we explore a novel cross-modal adversarial attack strategy, termed multiform attack. We propose a dual-layer optimization framework based on gradient-evolution, facilitating efficient perturbation transfer between modalities. In the first layer of optimization, the framework utilizes image gradients to learn universal perturbations within each modality and employs evolutionary algorithms to search for shared perturbations with transferability across different modalities through secondary optimization. Through extensive testing on multiple heterogeneous datasets, we demonstrate the superiority and robustness of Multiform Attack compared to existing techniques. This work not only enhances the transferability of cross-modal adversarial attacks but also provides a new perspective for understanding security vulnerabilities in cross-modal systems.
Adversarial Learning for Neural PDE Solvers with Sparse Data
Sep 04, 2024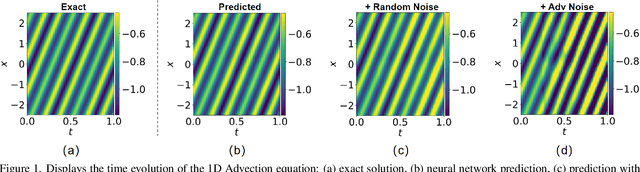
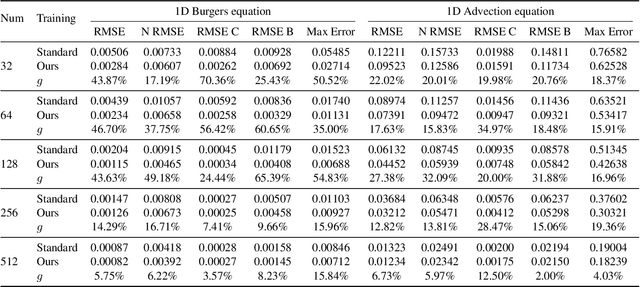
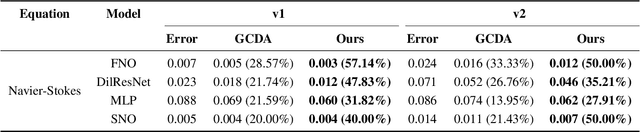
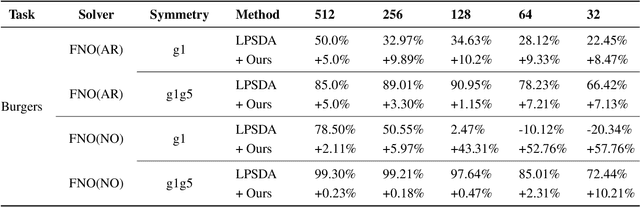
Neural network solvers for partial differential equations (PDEs) have made significant progress, yet they continue to face challenges related to data scarcity and model robustness. Traditional data augmentation methods, which leverage symmetry or invariance, impose strong assumptions on physical systems that often do not hold in dynamic and complex real-world applications. To address this research gap, this study introduces a universal learning strategy for neural network PDEs, named Systematic Model Augmentation for Robust Training (SMART). By focusing on challenging and improving the model's weaknesses, SMART reduces generalization error during training under data-scarce conditions, leading to significant improvements in prediction accuracy across various PDE scenarios. The effectiveness of the proposed method is demonstrated through both theoretical analysis and extensive experimentation. The code will be available.
Beyond Augmentation: Empowering Model Robustness under Extreme Capture Environments
Jul 18, 2024



Person Re-identification (re-ID) in computer vision aims to recognize and track individuals across different cameras. While previous research has mainly focused on challenges like pose variations and lighting changes, the impact of extreme capture conditions is often not adequately addressed. These extreme conditions, including varied lighting, camera styles, angles, and image distortions, can significantly affect data distribution and re-ID accuracy. Current research typically improves model generalization under normal shooting conditions through data augmentation techniques such as adjusting brightness and contrast. However, these methods pay less attention to the robustness of models under extreme shooting conditions. To tackle this, we propose a multi-mode synchronization learning (MMSL) strategy . This approach involves dividing images into grids, randomly selecting grid blocks, and applying data augmentation methods like contrast and brightness adjustments. This process introduces diverse transformations without altering the original image structure, helping the model adapt to extreme variations. This method improves the model's generalization under extreme conditions and enables learning diverse features, thus better addressing the challenges in re-ID. Extensive experiments on a simulated test set under extreme conditions have demonstrated the effectiveness of our method. This approach is crucial for enhancing model robustness and adaptability in real-world scenarios, supporting the future development of person re-identification technology.
Beyond Dropout: Robust Convolutional Neural Networks Based on Local Feature Masking
Jul 18, 2024In the contemporary of deep learning, where models often grapple with the challenge of simultaneously achieving robustness against adversarial attacks and strong generalization capabilities, this study introduces an innovative Local Feature Masking (LFM) strategy aimed at fortifying the performance of Convolutional Neural Networks (CNNs) on both fronts. During the training phase, we strategically incorporate random feature masking in the shallow layers of CNNs, effectively alleviating overfitting issues, thereby enhancing the model's generalization ability and bolstering its resilience to adversarial attacks. LFM compels the network to adapt by leveraging remaining features to compensate for the absence of certain semantic features, nurturing a more elastic feature learning mechanism. The efficacy of LFM is substantiated through a series of quantitative and qualitative assessments, collectively showcasing a consistent and significant improvement in CNN's generalization ability and resistance against adversarial attacks--a phenomenon not observed in current and prior methodologies. The seamless integration of LFM into established CNN frameworks underscores its potential to advance both generalization and adversarial robustness within the deep learning paradigm. Through comprehensive experiments, including robust person re-identification baseline generalization experiments and adversarial attack experiments, we demonstrate the substantial enhancements offered by LFM in addressing the aforementioned challenges. This contribution represents a noteworthy stride in advancing robust neural network architectures.
Cross-Task Attack: A Self-Supervision Generative Framework Based on Attention Shift
Jul 18, 2024



Studying adversarial attacks on artificial intelligence (AI) systems helps discover model shortcomings, enabling the construction of a more robust system. Most existing adversarial attack methods only concentrate on single-task single-model or single-task cross-model scenarios, overlooking the multi-task characteristic of artificial intelligence systems. As a result, most of the existing attacks do not pose a practical threat to a comprehensive and collaborative AI system. However, implementing cross-task attacks is highly demanding and challenging due to the difficulty in obtaining the real labels of different tasks for the same picture and harmonizing the loss functions across different tasks. To address this issue, we propose a self-supervised Cross-Task Attack framework (CTA), which utilizes co-attention and anti-attention maps to generate cross-task adversarial perturbation. Specifically, the co-attention map reflects the area to which different visual task models pay attention, while the anti-attention map reflects the area that different visual task models neglect. CTA generates cross-task perturbations by shifting the attention area of samples away from the co-attention map and closer to the anti-attention map. We conduct extensive experiments on multiple vision tasks and the experimental results confirm the effectiveness of the proposed design for adversarial attacks.
Exploring Color Invariance through Image-Level Ensemble Learning
Jan 19, 2024



In the field of computer vision, the persistent presence of color bias, resulting from fluctuations in real-world lighting and camera conditions, presents a substantial challenge to the robustness of models. This issue is particularly pronounced in complex wide-area surveillance scenarios, such as person re-identification and industrial dust segmentation, where models often experience a decline in performance due to overfitting on color information during training, given the presence of environmental variations. Consequently, there is a need to effectively adapt models to cope with the complexities of camera conditions. To address this challenge, this study introduces a learning strategy named Random Color Erasing, which draws inspiration from ensemble learning. This strategy selectively erases partial or complete color information in the training data without disrupting the original image structure, thereby achieving a balanced weighting of color features and other features within the neural network. This approach mitigates the risk of overfitting and enhances the model's ability to handle color variation, thereby improving its overall robustness. The approach we propose serves as an ensemble learning strategy, characterized by robust interpretability. A comprehensive analysis of this methodology is presented in this paper. Across various tasks such as person re-identification and semantic segmentation, our approach consistently improves strong baseline methods. Notably, in comparison to existing methods that prioritize color robustness, our strategy significantly enhances performance in cross-domain scenarios. The code available at \url{https://github.com/layumi/Person\_reID\_baseline\_pytorch/blob/master/random\_erasing.py} or \url{https://github.com/finger-monkey/Data-Augmentation}.
Cross-Modality Perturbation Synergy Attack for Person Re-identification
Jan 19, 2024

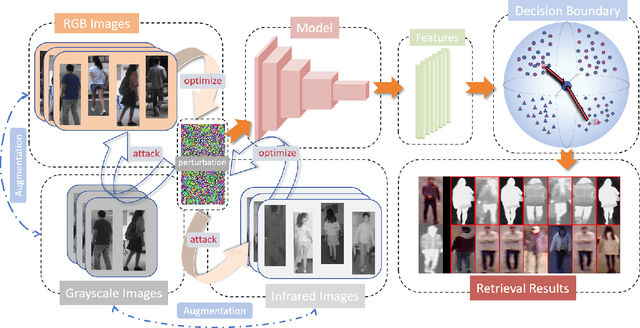

In recent years, there has been significant research focusing on addressing security concerns in single-modal person re-identification (ReID) systems that are based on RGB images. However, the safety of cross-modality scenarios, which are more commonly encountered in practical applications involving images captured by infrared cameras, has not received adequate attention. The main challenge in cross-modality ReID lies in effectively dealing with visual differences between different modalities. For instance, infrared images are typically grayscale, unlike visible images that contain color information. Existing attack methods have primarily focused on the characteristics of the visible image modality, overlooking the features of other modalities and the variations in data distribution among different modalities. This oversight can potentially undermine the effectiveness of these methods in image retrieval across diverse modalities. This study represents the first exploration into the security of cross-modality ReID models and proposes a universal perturbation attack specifically designed for cross-modality ReID. This attack optimizes perturbations by leveraging gradients from diverse modality data, thereby disrupting the discriminator and reinforcing the differences between modalities. We conducted experiments on two widely used cross-modality datasets, namely RegDB and SYSU, which not only demonstrated the effectiveness of our method but also provided insights for future enhancements in the robustness of cross-modality ReID systems.
Robust Person Re-identification with Multi-Modal Joint Defence
Dec 06, 2021
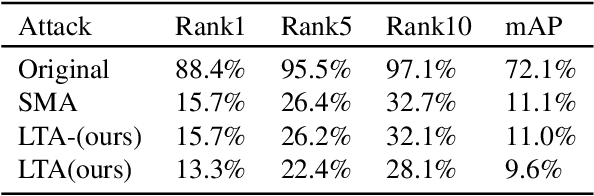
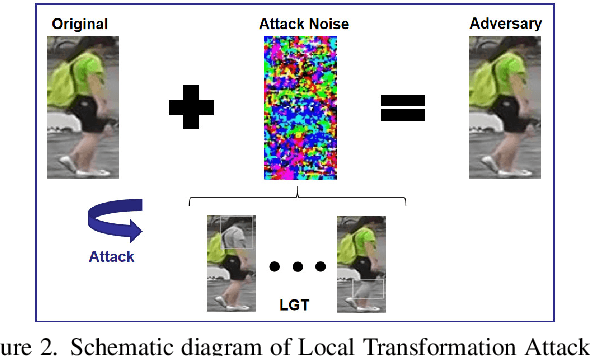
The Person Re-identification (ReID) system based on metric learning has been proved to inherit the vulnerability of deep neural networks (DNNs), which are easy to be fooled by adversarail metric attacks. Existing work mainly relies on adversarial training for metric defense, and more methods have not been fully studied. By exploring the impact of attacks on the underlying features, we propose targeted methods for metric attacks and defence methods. In terms of metric attack, we use the local color deviation to construct the intra-class variation of the input to attack color features. In terms of metric defenses, we propose a joint defense method which includes two parts of proactive defense and passive defense. Proactive defense helps to enhance the robustness of the model to color variations and the learning of structure relations across multiple modalities by constructing different inputs from multimodal images, and passive defense exploits the invariance of structural features in a changing pixel space by circuitous scaling to preserve structural features while eliminating some of the adversarial noise. Extensive experiments demonstrate that the proposed joint defense compared with the existing adversarial metric defense methods which not only against multiple attacks at the same time but also has not significantly reduced the generalization capacity of the model. The code is available at https://github.com/finger-monkey/multi-modal_joint_defence.
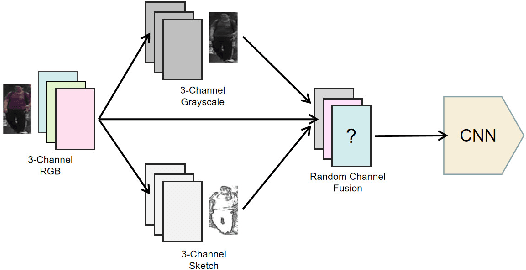
A Person Re-identification Data Augmentation Method with Adversarial Defense Effect
Feb 10, 2021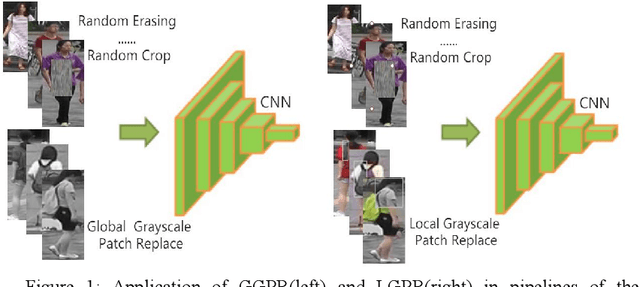
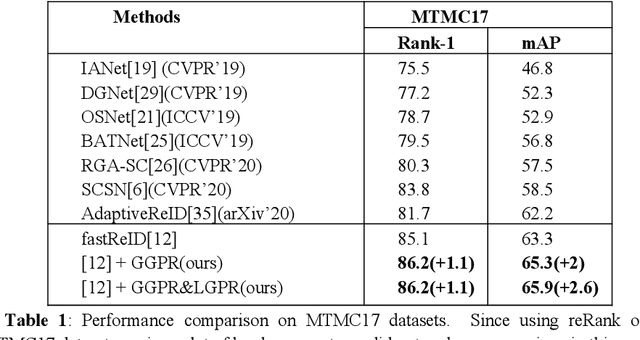

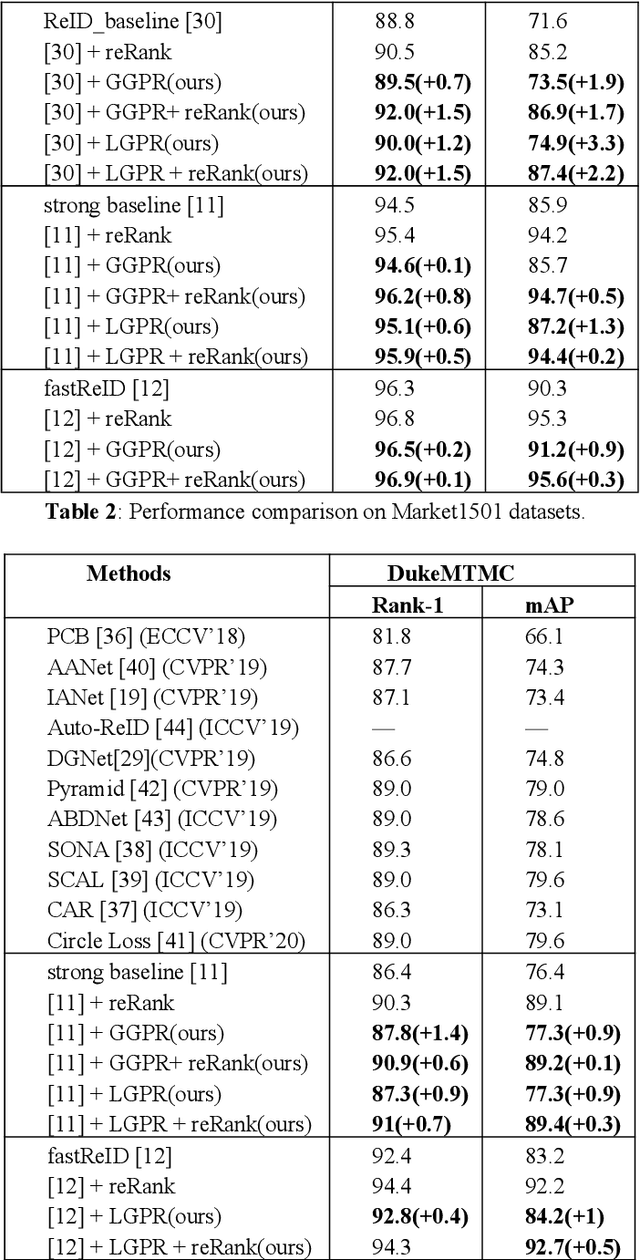
The security of the Person Re-identification(ReID) model plays a decisive role in the application of ReID. However, deep neural networks have been shown to be vulnerable, and adding undetectable adversarial perturbations to clean images can trick deep neural networks that perform well in clean images. We propose a ReID multi-modal data augmentation method with adversarial defense effect: 1) Grayscale Patch Replacement, it consists of Local Grayscale Patch Replacement(LGPR) and Global Grayscale Patch Replacement(GGPR). This method can not only improve the accuracy of the model, but also help the model defend against adversarial examples; 2) Multi-Modal Defense, it integrates three homogeneous modal images of visible, grayscale and sketch, and further strengthens the defense ability of the model. These methods fuse different modalities of homogeneous images to enrich the input sample variety, the variaty of samples will reduce the over-fitting of the ReID model to color variations and make the adversarial space of the dataset that the attack method can find difficult to align, thus the accuracy of model is improved, and the attack effect is greatly reduced. The more modal homogeneous images are fused, the stronger the defense capabilities is . The proposed method performs well on multiple datasets, and successfully defends the attack of MS-SSIM proposed by CVPR2020 against ReID [10], and increases the accuracy by 467 times(0.2% to 93.3%).The code is available at https://github.com/finger-monkey/ReID_Adversarial_Defense.