 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Broad Biomedical Knowledge be Contextualized into Scenario-Grounded Propositions?
May 26, 2026Biomedical discovery often requires connecting broad biomedical knowledge with specific experimental or clinical data. Background knowledge suggests relevant mechanisms but is usually too general to map directly onto dataset variables, while data-driven patterns can be dataset-specific and hard to interpret mechanistically. We study this missing link as knowledge contextualization: transforming broad biomedical knowledge into evidence-supported, scenario-grounded propositions that domain experts can inspect, replay, and validate. We propose SCENE, a bi-level multi-agent framework that treats knowledge contextualization as iterative search. The upper level converts broad knowledge into search directions and grounds them in the dataset schema. The lower level executes these directions through multi-objective optimization to identify concrete propositions that balance evidential strength and data support. Feedback between the two levels progressively refines the search. We evaluate SCENE in two settings: discovering patient subgroups with heterogeneous treatment benefits in clinical trial scenarios, and identifying context-specific biological responses in LINCS L1000 studies. In clinical trials, SCENE discovers specific, well-supported subgroups and outperforms existing baselines. In L1000 studies, SCENE identifies perturbational contexts with strong target-response matching and high positive rates. These results show that SCENE bridges broad knowledge and scenario-specific evidence, producing traceable, inspectable hypotheses for follow-up validation.
Don't Retrain, Just Reuse: Recovering Dual-Target Molecules from Single-Target Diffusion Models
May 25, 2026Designing a single molecule that modulates two targets is a promising strategy for polypharmacology, but it remains substantially harder than standard single-target generation because one candidate must satisfy two binding requirements while preserving drug-likeness and synthesizability. Existing dual-target generative methods typically introduce dual-target capability by either retraining the generator or intervening in the diffusion process during sampling. The former can be costly and difficult to stabilize when dual-target supervision is sparse, while the latter may be sensitive to denoising-time target balancing and competing update directions. These limitations motivate a generator-preserving alternative that keeps the pretrained prior intact: can dual-target candidates instead be recovered from the input space of a frozen single-target diffusion model, without modifying its parameters or denoising dynamics? We formulate this task as a constrained multi-objective optimization problem and propose REUSE, a hierarchical evolutionary input-space search framework that combines pair-conditioned exploration with structured multi-stage selection to enforce dual-target affinity, chemical quality, and diversity. Experiments show that, compared with methods that modify the diffusion process, REUSE consistently improves dual-target affinity and balance, achieving a 20.9-percentage-point gain in Dual High Affinity over the strongest prior baseline while maintaining competitive molecular quality.
Fading the Digital Ink: A Universal Black-Box Attack Framework for 3DGS Watermarking Systems
Aug 10, 2025With the rise of 3D Gaussian Splatting (3DGS), a variety of digital watermarking techniques, embedding either 1D bitstreams or 2D images, are used for copyright protection. However, the robustness of these watermarking techniques against potential attacks remains underexplored. This paper introduces the first universal black-box attack framework, the Group-based Multi-objective Evolutionary Attack (GMEA), designed to challenge these watermarking systems. We formulate the attack as a large-scale multi-objective optimization problem, balancing watermark removal with visual quality. In a black-box setting, we introduce an indirect objective function that blinds the watermark detector by minimizing the standard deviation of features extracted by a convolutional network, thus rendering the feature maps uninformative. To manage the vast search space of 3DGS models, we employ a group-based optimization strategy to partition the model into multiple, independent sub-optimization problems. Experiments demonstrate that our framework effectively removes both 1D and 2D watermarks from mainstream 3DGS watermarking methods while maintaining high visual fidelity. This work reveals critical vulnerabilities in existing 3DGS copyright protection schemes and calls for the development of more robust watermarking systems.
Cross-Modality Attack Boosted by Gradient-Evolutionary Multiform Optimization
Sep 26, 2024



In recent years, despite significant advancements in adversarial attack research, the security challenges in cross-modal scenarios, such as the transferability of adversarial attacks between infrared, thermal, and RGB images, have been overlooked. These heterogeneous image modalities collected by different hardware devices are widely prevalent in practical applications, and the substantial differences between modalities pose significant challenges to attack transferability. In this work, we explore a novel cross-modal adversarial attack strategy, termed multiform attack. We propose a dual-layer optimization framework based on gradient-evolution, facilitating efficient perturbation transfer between modalities. In the first layer of optimization, the framework utilizes image gradients to learn universal perturbations within each modality and employs evolutionary algorithms to search for shared perturbations with transferability across different modalities through secondary optimization. Through extensive testing on multiple heterogeneous datasets, we demonstrate the superiority and robustness of Multiform Attack compared to existing techniques. This work not only enhances the transferability of cross-modal adversarial attacks but also provides a new perspective for understanding security vulnerabilities in cross-modal systems.
Ask, Attend, Attack: A Effective Decision-Based Black-Box Targeted Attack for Image-to-Text Models
Aug 16, 2024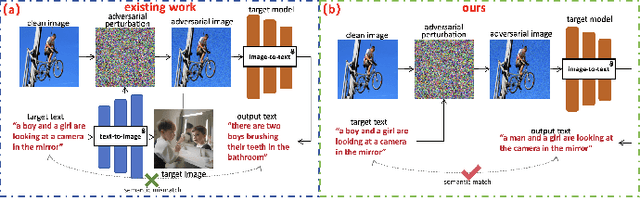
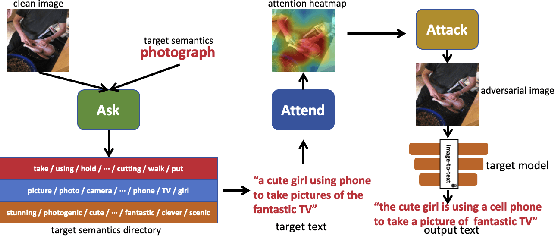


While image-to-text models have demonstrated significant advancements in various vision-language tasks, they remain susceptible to adversarial attacks. Existing white-box attacks on image-to-text models require access to the architecture, gradients, and parameters of the target model, resulting in low practicality. Although the recently proposed gray-box attacks have improved practicality, they suffer from semantic loss during the training process, which limits their targeted attack performance. To advance adversarial attacks of image-to-text models, this paper focuses on a challenging scenario: decision-based black-box targeted attacks where the attackers only have access to the final output text and aim to perform targeted attacks. Specifically, we formulate the decision-based black-box targeted attack as a large-scale optimization problem. To efficiently solve the optimization problem, a three-stage process \textit{Ask, Attend, Attack}, called \textit{AAA}, is proposed to coordinate with the solver. \textit{Ask} guides attackers to create target texts that satisfy the specific semantics. \textit{Attend} identifies the crucial regions of the image for attacking, thus reducing the search space for the subsequent \textit{Attack}. \textit{Attack} uses an evolutionary algorithm to attack the crucial regions, where the attacks are semantically related to the target texts of \textit{Ask}, thus achieving targeted attacks without semantic loss. Experimental results on transformer-based and CNN+RNN-based image-to-text models confirmed the effectiveness of our proposed \textit{AAA}.
Cross-Task Attack: A Self-Supervision Generative Framework Based on Attention Shift
Jul 18, 2024



Studying adversarial attacks on artificial intelligence (AI) systems helps discover model shortcomings, enabling the construction of a more robust system. Most existing adversarial attack methods only concentrate on single-task single-model or single-task cross-model scenarios, overlooking the multi-task characteristic of artificial intelligence systems. As a result, most of the existing attacks do not pose a practical threat to a comprehensive and collaborative AI system. However, implementing cross-task attacks is highly demanding and challenging due to the difficulty in obtaining the real labels of different tasks for the same picture and harmonizing the loss functions across different tasks. To address this issue, we propose a self-supervised Cross-Task Attack framework (CTA), which utilizes co-attention and anti-attention maps to generate cross-task adversarial perturbation. Specifically, the co-attention map reflects the area to which different visual task models pay attention, while the anti-attention map reflects the area that different visual task models neglect. CTA generates cross-task perturbations by shifting the attention area of samples away from the co-attention map and closer to the anti-attention map. We conduct extensive experiments on multiple vision tasks and the experimental results confirm the effectiveness of the proposed design for adversarial attacks.
Multi-View Subgraph Neural Networks: Self-Supervised Learning with Scarce Labeled Data
Apr 19, 2024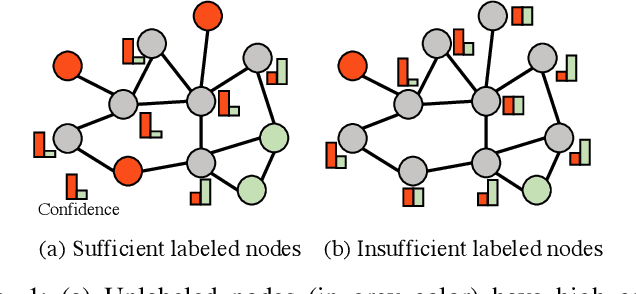
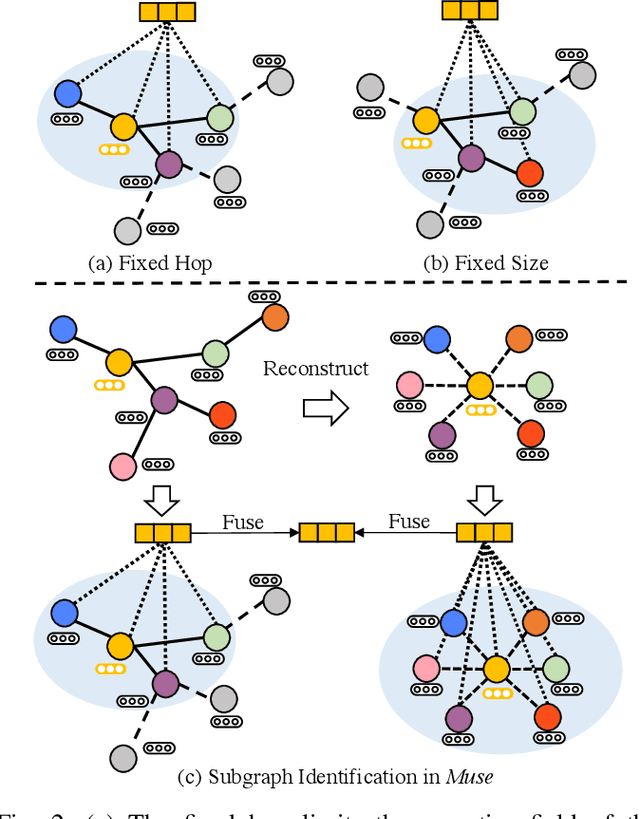
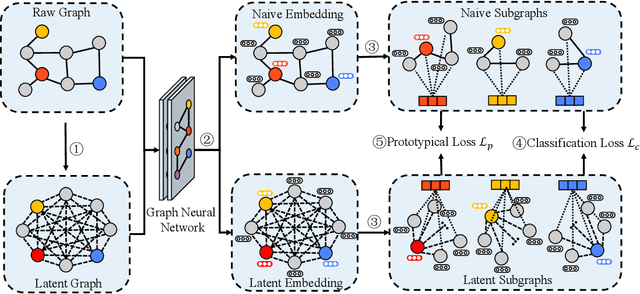
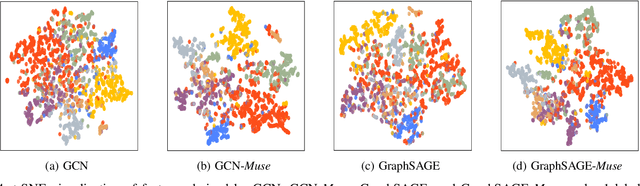
While graph neural networks (GNNs) have become the de-facto standard for graph-based node classification, they impose a strong assumption on the availability of sufficient labeled samples. This assumption restricts the classification performance of prevailing GNNs on many real-world applications suffering from low-data regimes. Specifically, features extracted from scarce labeled nodes could not provide sufficient supervision for the unlabeled samples, leading to severe over-fitting. In this work, we point out that leveraging subgraphs to capture long-range dependencies can augment the representation of a node with homophily properties, thus alleviating the low-data regime. However, prior works leveraging subgraphs fail to capture the long-range dependencies among nodes. To this end, we present a novel self-supervised learning framework, called multi-view subgraph neural networks (Muse), for handling long-range dependencies. In particular, we propose an information theory-based identification mechanism to identify two types of subgraphs from the views of input space and latent space, respectively. The former is to capture the local structure of the graph, while the latter captures the long-range dependencies among nodes. By fusing these two views of subgraphs, the learned representations can preserve the topological properties of the graph at large, including the local structure and long-range dependencies, thus maximizing their expressiveness for downstream node classification tasks. Experimental results show that Muse outperforms the alternative methods on node classification tasks with limited labeled data.