 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Contrastive Clustering Performance by Multiple Fusing-Augmenting ViT Blocks
Nov 12, 2025



In the field of image clustering, the widely used contrastive learning networks improve clustering performance by maximizing the similarity between positive pairs and the dissimilarity of negative pairs of the inputs. Extant contrastive learning networks, whose two encoders often implicitly interact with each other by parameter sharing or momentum updating, may not fully exploit the complementarity and similarity of the positive pairs to extract clustering features from input data. To explicitly fuse the learned features of positive pairs, we design a novel multiple fusing-augmenting ViT blocks (MFAVBs) based on the excellent feature learning ability of Vision Transformers (ViT). Firstly, two preprocessed augmentions as positive pairs are separately fed into two shared-weight ViTs, then their output features are fused to input into a larger ViT. Secondly, the learned features are split into a pair of new augmented positive samples and passed to the next FAVBs, enabling multiple fusion and augmention through MFAVBs operations. Finally, the learned features are projected into both instance-level and clustering-level spaces to calculate the cross-entropy loss, followed by parameter updates by backpropagation to finalize the training process. To further enhance ability of the model to distinguish between similar images, our input data for the network we propose is preprocessed augmentions with features extracted from the CLIP pretrained model. Our experiments on seven public datasets demonstrate that MFAVBs serving as the backbone for contrastive clustering outperforms the state-of-the-art techniques in terms of clustering performance.
Terahertz Spatial Wireless Channel Modeling with Radio Radiance Field
May 06, 2025



Terahertz (THz) communication is a key enabler for 6G systems, offering ultra-wide bandwidth and unprecedented data rates. However, THz signal propagation differs significantly from lower-frequency bands due to severe free space path loss, minimal diffraction and specular reflection, and prominent scattering, making conventional channel modeling and pilot-based estimation approaches inefficient. In this work, we investigate the feasibility of applying radio radiance field (RRF) framework to the THz band. This method reconstructs a continuous RRF using visual-based geometry and sparse THz RF measurements, enabling efficient spatial channel state information (Spatial-CSI) modeling without dense sampling. We first build a fine simulated THz scenario, then we reconstruct the RRF and evaluate the performance in terms of both reconstruction quality and effectiveness in THz communication, showing that the reconstructed RRF captures key propagation paths with sparse training samples. Our findings demonstrate that RRF modeling remains effective in the THz regime and provides a promising direction for scalable, low-cost spatial channel reconstruction in future 6G networks.
Emerging Advances in Learned Video Compression: Models, Systems and Beyond
Apr 30, 2025Video compression is a fundamental topic in the visual intelligence, bridging visual signal sensing/capturing and high-level visual analytics. The broad success of artificial intelligence (AI) technology has enriched the horizon of video compression into novel paradigms by leveraging end-to-end optimized neural models. In this survey, we first provide a comprehensive and systematic overview of recent literature on end-to-end optimized learned video coding, covering the spectrum of pioneering efforts in both uni-directional and bi-directional prediction based compression model designation. We further delve into the optimization techniques employed in learned video compression (LVC), emphasizing their technical innovations, advantages. Some standardization progress is also reported. Furthermore, we investigate the system design and hardware implementation challenges of the LVC inclusively. Finally, we present the extensive simulation results to demonstrate the superior compression performance of LVC models, addressing the question that why learned codecs and AI-based video technology would have with broad impact on future visual intelligence research.
DeepMIDE: A Multivariate Spatio-Temporal Method for Ultra-Scale Offshore Wind Energy Forecasting
Oct 26, 2024

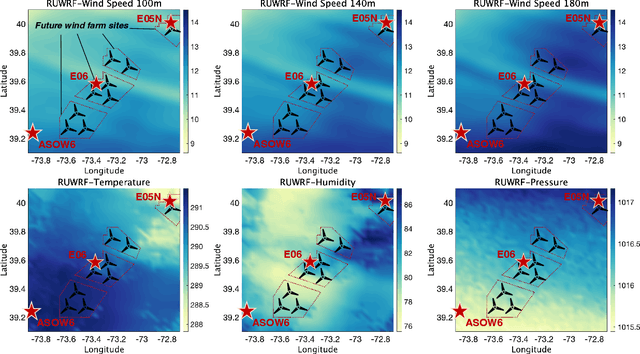

To unlock access to stronger winds, the offshore wind industry is advancing with significantly larger and taller wind turbines. This massive upscaling motivates a departure from univariate wind forecasting methods that traditionally focused on a single representative height. To fill this gap, we propose DeepMIDE--a statistical deep learning method which jointly models the offshore wind speeds across space, time, and height. DeepMIDE is formulated as a multi-output integro-difference equation model with a multivariate, nonstationary, and state-dependent kernel characterized by a set of advection vectors that encode the physics of wind field formation and propagation. Embedded within DeepMIDE, an advanced deep learning architecture learns these advection vectors from high dimensional streams of exogenous weather information, which, along with other parameters, are plugged back into the statistical model for probabilistic multi-height space-time forecasting. Tested on real-world data from future offshore wind energy sites in the Northeastern United States, the wind speed and power forecasts from DeepMIDE are shown to outperform those from prevalent time series, spatio-temporal, and deep learning methods.
MPAI-EEV: Standardization Efforts of Artificial Intelligence based End-to-End Video Coding
Sep 14, 2023



The rapid advancement of artificial intelligence (AI) technology has led to the prioritization of standardizing the processing, coding, and transmission of video using neural networks. To address this priority area, the Moving Picture, Audio, and Data Coding by Artificial Intelligence (MPAI) group is developing a suite of standards called MPAI-EEV for "end-to-end optimized neural video coding." The aim of this AI-based video standard project is to compress the number of bits required to represent high-fidelity video data by utilizing data-trained neural coding technologies. This approach is not constrained by how data coding has traditionally been applied in the context of a hybrid framework. This paper presents an overview of recent and ongoing standardization efforts in this area and highlights the key technologies and design philosophy of EEV. It also provides a comparison and report on some primary efforts such as the coding efficiency of the reference model. Additionally, it discusses emerging activities such as learned Unmanned-Aerial-Vehicles (UAVs) video coding which are currently planned, under development, or in the exploration phase. With a focus on UAV video signals, this paper addresses the current status of these preliminary efforts. It also indicates development timelines, summarizes the main technical details, and provides pointers to further points of reference. The exploration experiment shows that the EEV model performs better than the state-of-the-art video coding standard H.266/VVC in terms of perceptual evaluation metric.
Pseudo-Bag Mixup Augmentation for Multiple Instance Learning-Based Whole Slide Image Classification
Jul 03, 2023



Given the special situation of modeling gigapixel images, multiple instance learning (MIL) has become one of the most important frameworks for Whole Slide Image (WSI) classification. In current practice, most MIL networks often face two unavoidable problems in training: i) insufficient WSI data, and ii) the sample memorization inclination inherent in neural networks. These problems may hinder MIL models from adequate and efficient training, suppressing the continuous performance promotion of classification models on WSIs. Inspired by the basic idea of Mixup, this paper proposes a new Pseudo-bag Mixup (PseMix) data augmentation scheme to improve the training of MIL models. This scheme generalizes the Mixup strategy for general images to special WSIs via pseudo-bags so as to be applied in MIL-based WSI classification. Cooperated by pseudo-bags, our PseMix fulfills the critical size alignment and semantic alignment in Mixup strategy. Moreover, it is designed as an efficient and decoupled method, neither involving time-consuming operations nor relying on MIL model predictions. Comparative experiments and ablation studies are specially designed to evaluate the effectiveness and advantages of our PseMix. Experimental results show that PseMix could often assist state-of-the-art MIL networks to refresh the classification performance on WSIs. Besides, it could also boost the generalization ability of MIL models, and promote their robustness to patch occlusion and noisy labels. Our source code is available at https://github.com/liupei101/PseMix.
Learning to Compress Unmanned Aerial Vehicle (UAV) Captured Video: Benchmark and Analysis
Jan 15, 2023



During the past decade, the Unmanned-Aerial-Vehicles (UAVs) have attracted increasing attention due to their flexible, extensive, and dynamic space-sensing capabilities. The volume of video captured by UAVs is exponentially growing along with the increased bitrate generated by the advancement of the sensors mounted on UAVs, bringing new challenges for on-device UAV storage and air-ground data transmission. Most existing video compression schemes were designed for natural scenes without consideration of specific texture and view characteristics of UAV videos. In this work, we first contribute a detailed analysis of the current state of the field of UAV video coding. Then we propose to establish a novel task for learned UAV video coding and construct a comprehensive and systematic benchmark for such a task, present a thorough review of high quality UAV video datasets and benchmarks, and contribute extensive rate-distortion efficiency comparison of learned and conventional codecs after. Finally, we discuss the challenges of encoding UAV videos. It is expected that the benchmark will accelerate the research and development in video coding on drone platforms.
AdvMIL: Adversarial Multiple Instance Learning for the Survival Analysis on Whole-Slide Images
Dec 13, 2022



The survival analysis on histological whole-slide images (WSIs) is one of the most important means to estimate patient prognosis. Although many weakly-supervised deep learning models have been developed for gigapixel WSIs, their potential is generally restricted by classical survival analysis rules and fully-supervision requirements. As a result, these models provide patients only with a completely-certain point estimation of time-to-event, and they could only learn from the well-annotated WSI data currently at a small scale. To tackle these problems, we propose a novel adversarial multiple instance learning (AdvMIL) framework. This framework is based on adversarial time-to-event modeling, and it integrates the multiple instance learning (MIL) that is much necessary for WSI representation learning. It is a plug-and-play one, so that most existing WSI-based models with embedding-level MIL networks can be easily upgraded by applying this framework, gaining the improved ability of survival distribution estimation and semi-supervised learning. Our extensive experiments show that AdvMIL could not only bring performance improvement to mainstream WSI models at a relatively low computational cost, but also enable these models to learn from unlabeled data with semi-supervised learning. Our AdvMIL framework could promote the research of time-to-event modeling in computational pathology with its novel paradigm of adversarial MIL.
Dual-Stream Transformer with Cross-Attention on Whole-Slide Image Pyramids for Cancer Prognosis
Jun 22, 2022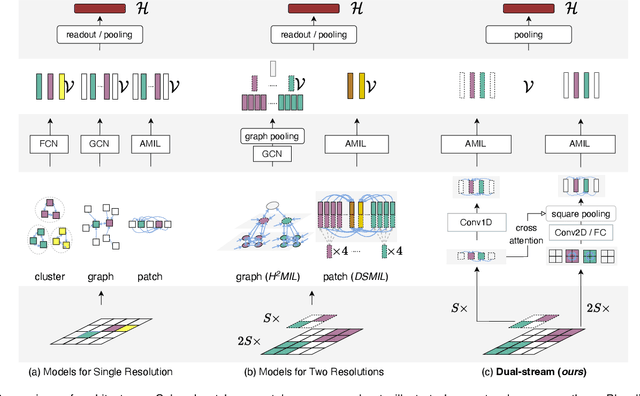
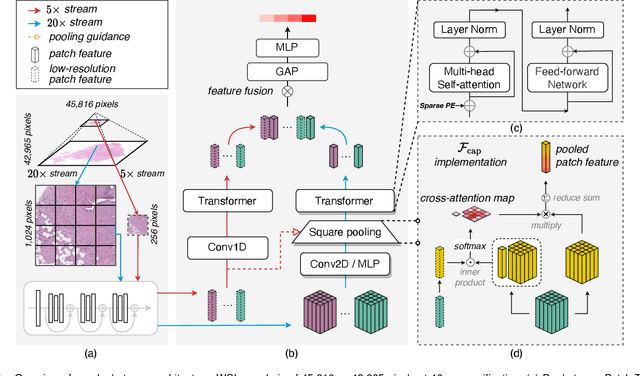
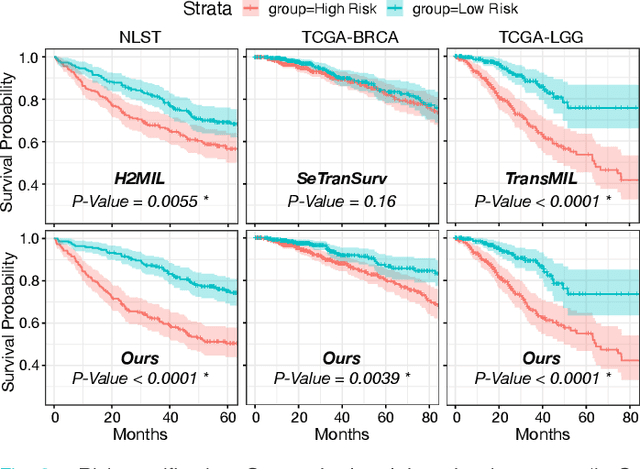
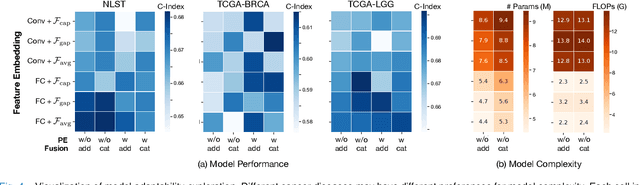
The cancer prognosis on gigapixel Whole-Slide Images (WSIs) has always been a challenging task. Most existing approaches focus solely on single-resolution images. The multi-resolution schemes, utilizing image pyramids to enhance WSI visual representations, have not yet been paid enough attention to. In order to explore a multi-resolution solution for improving cancer prognosis accuracy, this paper proposes a dual-stream architecture to model WSIs by an image pyramid strategy. This architecture consists of two sub-streams: one for low-resolution WSIs, and the other especially for high-resolution ones. Compared to other approaches, our scheme has three highlights: (i) there exists a one-to-one relation between stream and resolution; (ii) a square pooling layer is added to align the patches from two resolution streams, largely reducing computation cost and enabling a natural stream feature fusion; (iii) a cross-attention-based method is proposed to pool high-resolution patches spatially under the guidance of low-resolution ones. We validate our scheme on three publicly-available datasets with a total number of 3,101 WSIs from 1,911 patients. Experimental results verify that (i) hierarchical dual-stream representation is more effective than single-stream ones for cancer prognosis, gaining an average C-Index rise of 5.0% and 1.8% on a single low-resolution and high-resolution stream, respectively; (ii) our dual-stream scheme could outperform current state-of-the-art ones, by an average C-Index improvement of 5.1%; (iii) the cancer diseases with observable survival differences could have different preferences for model complexity. Our scheme could serve as an alternative tool for further facilitating WSI prognosis research.
MHTTS: Fast multi-head text-to-speech for spontaneous speech with imperfect transcription
Feb 04, 2022Neural network based end-to-end Text-to-Speech (TTS) has greatly improved the quality of synthesized speech. While how to use massive spontaneous speech without transcription efficiently still remains an open problem. In this paper, we propose MHTTS, a fast multi-speaker TTS system that is robust to transcription errors and speaking style speech data. Specifically, we introduce a multi-head model and transfer text information from high-quality corpus with manual transcription to spontaneous speech with imperfectly recognized transcription by jointly training them. MHTTS has three advantages: 1) Our system synthesizes better quality multi-speaker voice with faster inference speed. 2) Our system is capable of transferring correct text information to data with imperfect transcription, simulated using corruption, or provided by an Automatic Speech Recogniser (ASR). 3) Our system can utilize massive real spontaneous speech with imperfect transcription and synthesize expressive voice.