 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Involvement in Robotic Wheelchair Development: A Decade of Limited Progress
Mar 27, 2026Robotic wheelchairs (RWs) offer significant potential to enhance autonomy and participation for people with mobility impairments, yet many systems have failed to achieve sustained real-world adoption. This narrative literature review examined the extent and quality of end-user involvement in RW design, development, and evaluation over the past decade (2015--2025), assessed against core principles shared by major user-involvement approaches (e.g., user-/human-centered design, participatory/co-design, and inclusive design). The findings indicate that user involvement remains limited and is predominantly concentrated in late-stage evaluation rather than in early requirements definition or iterative co-design. Of the 399 records screened, only 23 studies (about 6%) met the inclusion criteria of verifiable end-user involvement, and many relied on small samples, often around ten participants, with limited justification for sample size selection, proxy users, laboratory-based validation, and non-standardized feedback methods. Research teams were largely engineering-dominated (about 89%) and geographically concentrated in high-income countries. Despite strong evidence that sustained user engagement improves usability and adoption in assistive technology, its systematic implementation in RW research remains rare. Advancing the field requires embedding participatory methodologies throughout the design lifecycle and addressing systemic barriers that constrain meaningful user involvement.
DeepMIDE: A Multivariate Spatio-Temporal Method for Ultra-Scale Offshore Wind Energy Forecasting
Oct 26, 2024

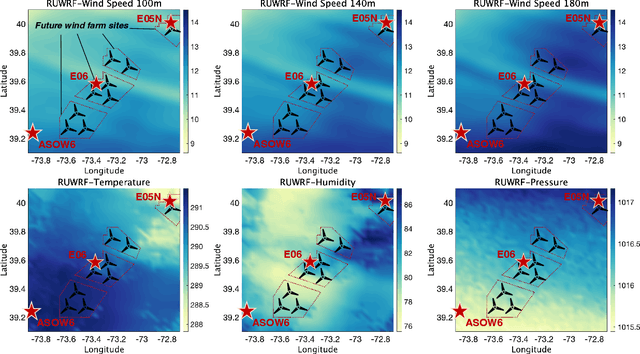

To unlock access to stronger winds, the offshore wind industry is advancing with significantly larger and taller wind turbines. This massive upscaling motivates a departure from univariate wind forecasting methods that traditionally focused on a single representative height. To fill this gap, we propose DeepMIDE--a statistical deep learning method which jointly models the offshore wind speeds across space, time, and height. DeepMIDE is formulated as a multi-output integro-difference equation model with a multivariate, nonstationary, and state-dependent kernel characterized by a set of advection vectors that encode the physics of wind field formation and propagation. Embedded within DeepMIDE, an advanced deep learning architecture learns these advection vectors from high dimensional streams of exogenous weather information, which, along with other parameters, are plugged back into the statistical model for probabilistic multi-height space-time forecasting. Tested on real-world data from future offshore wind energy sites in the Northeastern United States, the wind speed and power forecasts from DeepMIDE are shown to outperform those from prevalent time series, spatio-temporal, and deep learning methods.
Domain and Language Independent Feature Extraction for Statistical Text Categorization
Jul 02, 1996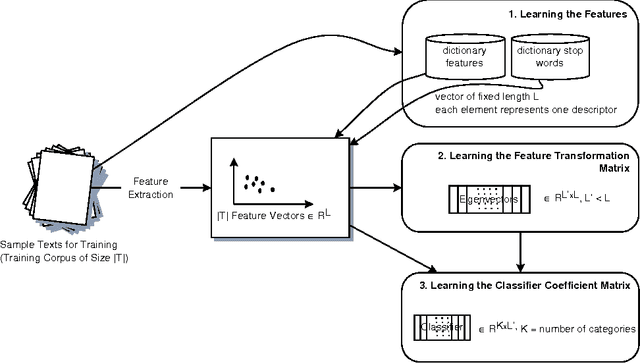

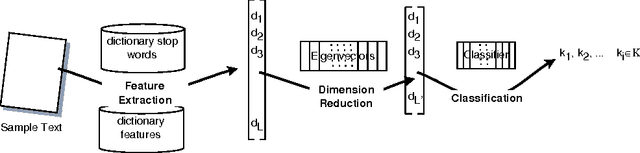

A generic system for text categorization is presented which uses a representative text corpus to adapt the processing steps: feature extraction, dimension reduction, and classification. Feature extraction automatically learns features from the corpus by reducing actual word forms using statistical information of the corpus and general linguistic knowledge. The dimension of feature vector is then reduced by linear transformation keeping the essential information. The classification principle is a minimum least square approach based on polynomials. The described system can be readily adapted to new domains or new languages. In application, the system is reliable, fast, and processes completely automatically. It is shown that the text categorizer works successfully both on text generated by document image analysis - DIA and on ground truth data.
* 12 pages, TeX file, 9 Postscript figures, uses epsf.sty