 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain and Language Independent Feature Extraction for Statistical Text Categorization
Jul 02, 1996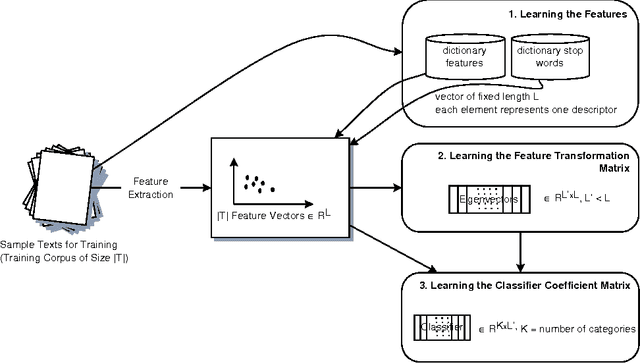

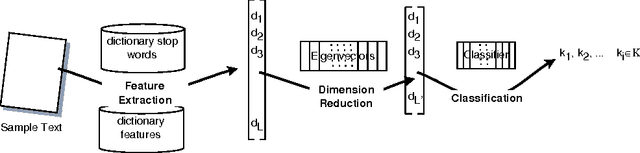

A generic system for text categorization is presented which uses a representative text corpus to adapt the processing steps: feature extraction, dimension reduction, and classification. Feature extraction automatically learns features from the corpus by reducing actual word forms using statistical information of the corpus and general linguistic knowledge. The dimension of feature vector is then reduced by linear transformation keeping the essential information. The classification principle is a minimum least square approach based on polynomials. The described system can be readily adapted to new domains or new languages. In application, the system is reliable, fast, and processes completely automatically. It is shown that the text categorizer works successfully both on text generated by document image analysis - DIA and on ground truth data.
* 12 pages, TeX file, 9 Postscript figures, uses epsf.sty