 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Out-of-Distribution Detection and Uncertainty Estimation for Trajectory Prediction
Aug 04, 2023



Despite the significant research efforts on trajectory prediction for automated driving, limited work exists on assessing the prediction reliability. To address this limitation we propose an approach that covers two sources of error, namely novel situations with out-of-distribution (OOD) detection and the complexity in in-distribution (ID) situations with uncertainty estimation. We introduce two modules next to an encoder-decoder network for trajectory prediction. Firstly, a Gaussian mixture model learns the probability density function of the ID encoder features during training, and then it is used to detect the OOD samples in regions of the feature space with low likelihood. Secondly, an error regression network is applied to the encoder, which learns to estimate the trajectory prediction error in supervised training. During inference, the estimated prediction error is used as the uncertainty. In our experiments, the combination of both modules outperforms the prior work in OOD detection and uncertainty estimation, on the Shifts robust trajectory prediction dataset by $2.8 \%$ and $10.1 \%$, respectively. The code is publicly available.
Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving
Jul 27, 2023



Accurate 3D human pose estimation (3D HPE) is crucial for enabling autonomous vehicles (AVs) to make informed decisions and respond proactively in critical road scenarios. Promising results of 3D HPE have been gained in several domains such as human-computer interaction, robotics, sports and medical analytics, often based on data collected in well-controlled laboratory environments. Nevertheless, the transfer of 3D HPE methods to AVs has received limited research attention, due to the challenges posed by obtaining accurate 3D pose annotations and the limited suitability of data from other domains. We present a simple yet efficient weakly supervised approach for 3D HPE in the AV context by employing a high-level sensor fusion between camera and LiDAR data. The weakly supervised setting enables training on the target datasets without any 2D/3D keypoint labels by using an off-the-shelf 2D joint extractor and pseudo labels generated from LiDAR to image projections. Our approach outperforms state-of-the-art results by up to $\sim$ 13% on the Waymo Open Dataset in the weakly supervised setting and achieves state-of-the-art results in the supervised setting.
A Benchmark for Unsupervised Anomaly Detection in Multi-Agent Trajectories
Sep 05, 2022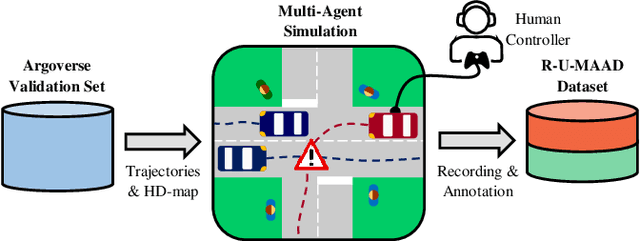

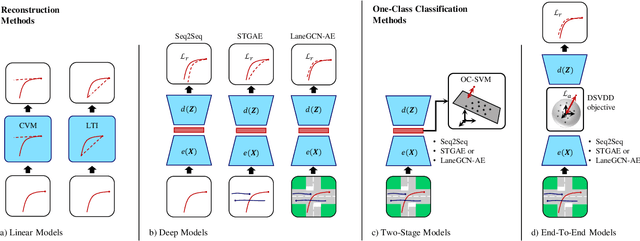
Human intuition allows to detect abnormal driving scenarios in situations they never experienced before. Like humans detect those abnormal situations and take countermeasures to prevent collisions, self-driving cars need anomaly detection mechanisms. However, the literature lacks a standard benchmark for the comparison of anomaly detection algorithms. We fill the gap and propose the R-U-MAAD benchmark for unsupervised anomaly detection in multi-agent trajectories. The goal is to learn a representation of the normal driving from the training sequences without labels, and afterwards detect anomalies. We use the Argoverse Motion Forecasting dataset for the training and propose a test dataset of 160 sequences with human-annotated anomalies in urban environments. To this end we combine a replay of real-world trajectories and scene-dependent abnormal driving in the simulation. In our experiments we compare 11 baselines including linear models, deep auto-encoders and one-class classification models using standard anomaly detection metrics. The deep reconstruction and end-to-end one-class methods show promising results. The benchmark and the baseline models will be publicly available.
MotionMixer: MLP-based 3D Human Body Pose Forecasting
Jul 01, 2022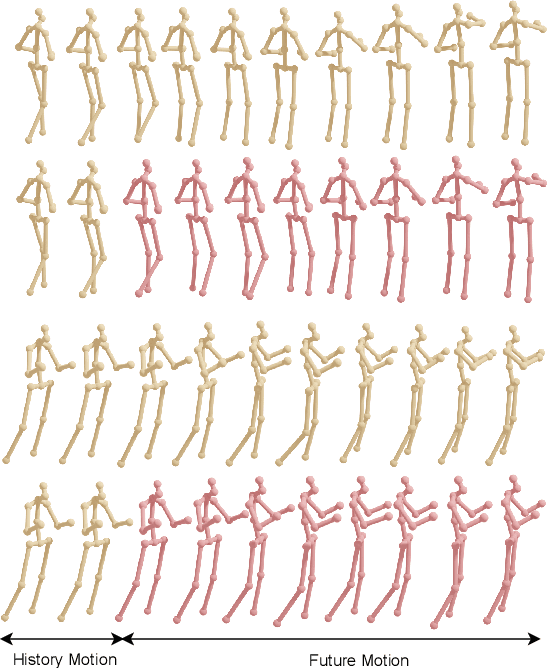

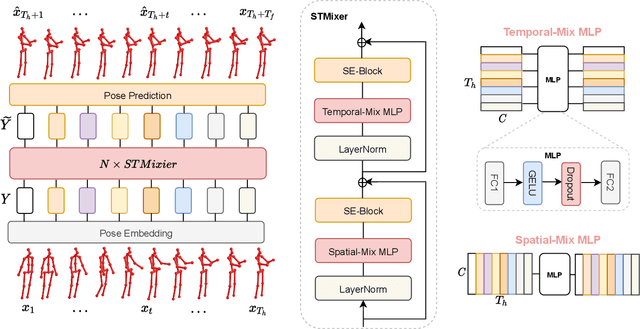
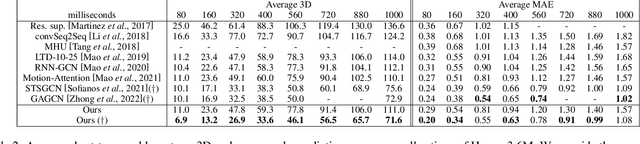
In this work, we present MotionMixer, an efficient 3D human body pose forecasting model based solely on multi-layer perceptrons (MLPs). MotionMixer learns the spatial-temporal 3D body pose dependencies by sequentially mixing both modalities. Given a stacked sequence of 3D body poses, a spatial-MLP extracts fine grained spatial dependencies of the body joints. The interaction of the body joints over time is then modelled by a temporal MLP. The spatial-temporal mixed features are finally aggregated and decoded to obtain the future motion. To calibrate the influence of each time step in the pose sequence, we make use of squeeze-and-excitation (SE) blocks. We evaluate our approach on Human3.6M, AMASS, and 3DPW datasets using the standard evaluation protocols. For all evaluations, we demonstrate state-of-the-art performance, while having a model with a smaller number of parameters. Our code is available at: https://github.com/MotionMLP/MotionMixer
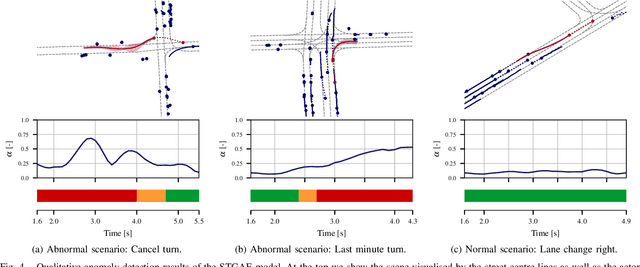
Anomaly Detection in Multi-Agent Trajectories for Automated Driving
Oct 28, 2021

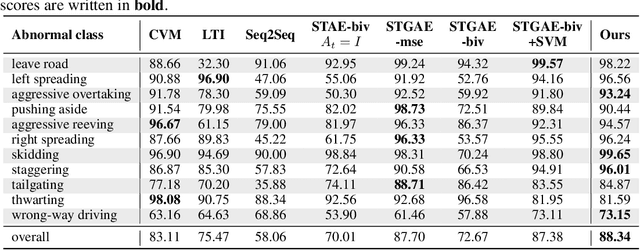
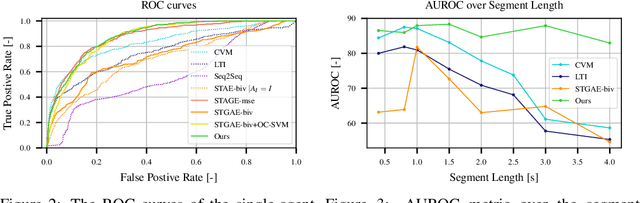
Human drivers can recognise fast abnormal driving situations to avoid accidents. Similar to humans, automated vehicles are supposed to perform anomaly detection. In this work, we propose the spatio-temporal graph auto-encoder for learning normal driving behaviours. Our innovation is the ability to jointly learn multiple trajectories of a dynamic number of agents. To perform anomaly detection, we first estimate a density function of the learned trajectory feature representation and then detect anomalies in low-density regions. Due to the lack of multi-agent trajectory datasets for anomaly detection in automated driving, we introduce our dataset using a driving simulator for normal and abnormal manoeuvres. Our evaluations show that our approach learns the relation between different agents and delivers promising results compared to the related works. The code, simulation and the dataset are publicly available on https://github.com/againerju/maad_highway.
Learning Temporal 3D Human Pose Estimation with Pseudo-Labels
Oct 14, 2021


We present a simple, yet effective, approach for self-supervised 3D human pose estimation. Unlike the prior work, we explore the temporal information next to the multi-view self-supervision. During training, we rely on triangulating 2D body pose estimates of a multiple-view camera system. A temporal convolutional neural network is trained with the generated 3D ground-truth and the geometric multi-view consistency loss, imposing geometrical constraints on the predicted 3D body skeleton. During inference, our model receives a sequence of 2D body pose estimates from a single-view to predict the 3D body pose for each of them. An extensive evaluation shows that our method achieves state-of-the-art performance in the Human3.6M and MPI-INF-3DHP benchmarks. Our code and models are publicly available at \url{https://github.com/vru2020/TM_HPE/}.
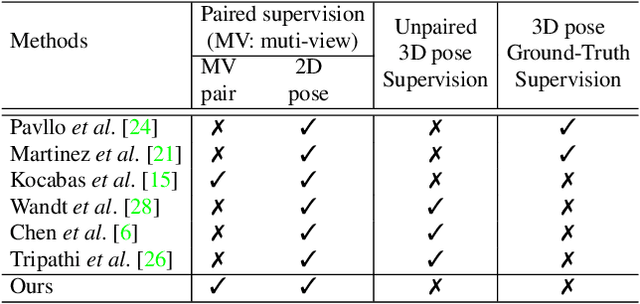
Self-Supervised 3D Human Pose Estimation with Multiple-View Geometry
Aug 17, 2021



We present a self-supervised learning algorithm for 3D human pose estimation of a single person based on a multiple-view camera system and 2D body pose estimates for each view. To train our model, represented by a deep neural network, we propose a four-loss function learning algorithm, which does not require any 2D or 3D body pose ground-truth. The proposed loss functions make use of the multiple-view geometry to reconstruct 3D body pose estimates and impose body pose constraints across the camera views. Our approach utilizes all available camera views during training, while the inference is single-view. In our evaluations, we show promising performance on Human3.6M and HumanEva benchmarks, while we also present a generalization study on MPI-INF-3DHP dataset, as well as several ablation results. Overall, we outperform all self-supervised learning methods and reach comparable results to supervised and weakly-supervised learning approaches. Our code and models are publicly available
Traffic Control Gesture Recognition for Autonomous Vehicles
Jul 31, 2020

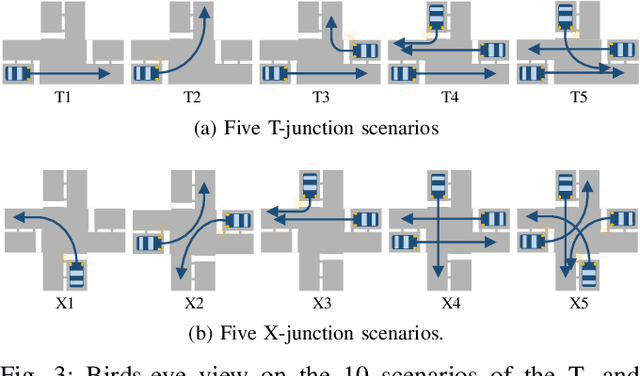

A car driver knows how to react on the gestures of the traffic officers. Clearly, this is not the case for the autonomous vehicle, unless it has road traffic control gesture recognition functionalities. In this work, we address the limitation of the existing autonomous driving datasets to provide learning data for traffic control gesture recognition. We introduce a dataset that is based on 3D body skeleton input to perform traffic control gesture classification on every time step. Our dataset consists of 250 sequences from several actors, ranging from 16 to 90 seconds per sequence. To evaluate our dataset, we propose eight sequential processing models based on deep neural networks such as recurrent networks, attention mechanism, temporal convolutional networks and graph convolutional networks. We present an extensive evaluation and analysis of all approaches for our dataset, as well as real-world quantitative evaluation. The code and dataset is publicly available.
Domain and Language Independent Feature Extraction for Statistical Text Categorization
Jul 02, 1996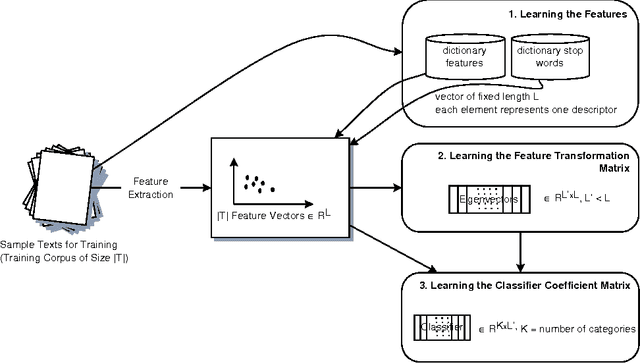

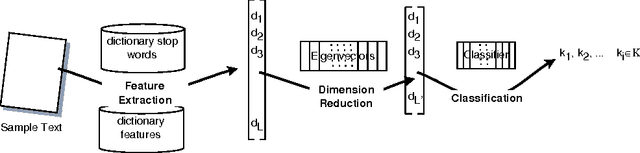

A generic system for text categorization is presented which uses a representative text corpus to adapt the processing steps: feature extraction, dimension reduction, and classification. Feature extraction automatically learns features from the corpus by reducing actual word forms using statistical information of the corpus and general linguistic knowledge. The dimension of feature vector is then reduced by linear transformation keeping the essential information. The classification principle is a minimum least square approach based on polynomials. The described system can be readily adapted to new domains or new languages. In application, the system is reliable, fast, and processes completely automatically. It is shown that the text categorizer works successfully both on text generated by document image analysis - DIA and on ground truth data.
* 12 pages, TeX file, 9 Postscript figures, uses epsf.sty