 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedestrian Environment Model for Automated Driving
Aug 17, 2023Besides interacting correctly with other vehicles, automated vehicles should also be able to react in a safe manner to vulnerable road users like pedestrians or cyclists. For a safe interaction between pedestrians and automated vehicles, the vehicle must be able to interpret the pedestrian's behavior. Common environment models do not contain information like body poses used to understand the pedestrian's intent. In this work, we propose an environment model that includes the position of the pedestrians as well as their pose information. We only use images from a monocular camera and the vehicle's localization data as input to our pedestrian environment model. We extract the skeletal information with a neural network human pose estimator from the image. Furthermore, we track the skeletons with a simple tracking algorithm based on the Hungarian algorithm and an ego-motion compensation. To obtain the 3D information of the position, we aggregate the data from consecutive frames in conjunction with the vehicle position. We demonstrate our pedestrian environment model on data generated with the CARLA simulator and the nuScenes dataset. Overall, we reach a relative position error of around 16% on both datasets.
Out-of-Distribution Detection for Monocular Depth Estimation
Aug 11, 2023In monocular depth estimation, uncertainty estimation approaches mainly target the data uncertainty introduced by image noise. In contrast to prior work, we address the uncertainty due to lack of knowledge, which is relevant for the detection of data not represented by the training distribution, the so-called out-of-distribution (OOD) data. Motivated by anomaly detection, we propose to detect OOD images from an encoder-decoder depth estimation model based on the reconstruction error. Given the features extracted with the fixed depth encoder, we train an image decoder for image reconstruction using only in-distribution data. Consequently, OOD images result in a high reconstruction error, which we use to distinguish between in- and out-of-distribution samples. We built our experiments on the standard NYU Depth V2 and KITTI benchmarks as in-distribution data. Our post hoc method performs astonishingly well on different models and outperforms existing uncertainty estimation approaches without modifying the trained encoder-decoder depth estimation model.
Data-Free Backbone Fine-Tuning for Pruned Neural Networks
Jun 22, 2023Model compression techniques reduce the computational load and memory consumption of deep neural networks. After the compression operation, e.g. parameter pruning, the model is normally fine-tuned on the original training dataset to recover from the performance drop caused by compression. However, the training data is not always available due to privacy issues or other factors. In this work, we present a data-free fine-tuning approach for pruning the backbone of deep neural networks. In particular, the pruned network backbone is trained with synthetically generated images, and our proposed intermediate supervision to mimic the unpruned backbone's output feature map. Afterwards, the pruned backbone can be combined with the original network head to make predictions. We generate synthetic images by back-propagating gradients to noise images while relying on L1-pruning for the backbone pruning. In our experiments, we show that our approach is task-independent due to pruning only the backbone. By evaluating our approach on 2D human pose estimation, object detection, and image classification, we demonstrate promising performance compared to the unpruned model. Our code is available at https://github.com/holzbock/dfbf.
Automated Static Camera Calibration with Intelligent Vehicles
Apr 21, 2023Connected and cooperative driving requires precise calibration of the roadside infrastructure for having a reliable perception system. To solve this requirement in an automated manner, we present a robust extrinsic calibration method for automated geo-referenced camera calibration. Our method requires a calibration vehicle equipped with a combined GNSS/RTK receiver and an inertial measurement unit (IMU) for self-localization. In order to remove any requirements for the target's appearance and the local traffic conditions, we propose a novel approach using hypothesis filtering. Our method does not require any human interaction with the information recorded by both the infrastructure and the vehicle. Furthermore, we do not limit road access for other road users during calibration. We demonstrate the feasibility and accuracy of our approach by evaluating our approach on synthetic datasets as well as a real-world connected intersection, and deploying the calibration on real infrastructure. Our source code is publicly available.
Gesture Recognition with Keypoint and Radar Stream Fusion for Automated Vehicles
Feb 20, 2023We present a joint camera and radar approach to enable autonomous vehicles to understand and react to human gestures in everyday traffic. Initially, we process the radar data with a PointNet followed by a spatio-temporal multilayer perceptron (stMLP). Independently, the human body pose is extracted from the camera frame and processed with a separate stMLP network. We propose a fusion neural network for both modalities, including an auxiliary loss for each modality. In our experiments with a collected dataset, we show the advantages of gesture recognition with two modalities. Motivated by adverse weather conditions, we also demonstrate promising performance when one of the sensors lacks functionality.
* Accepted for presentation at the 3rd AVVision Workshop at ECCV 2022, October 23, 2022, Tel Aviv, Israel
MotionMixer: MLP-based 3D Human Body Pose Forecasting
Jul 01, 2022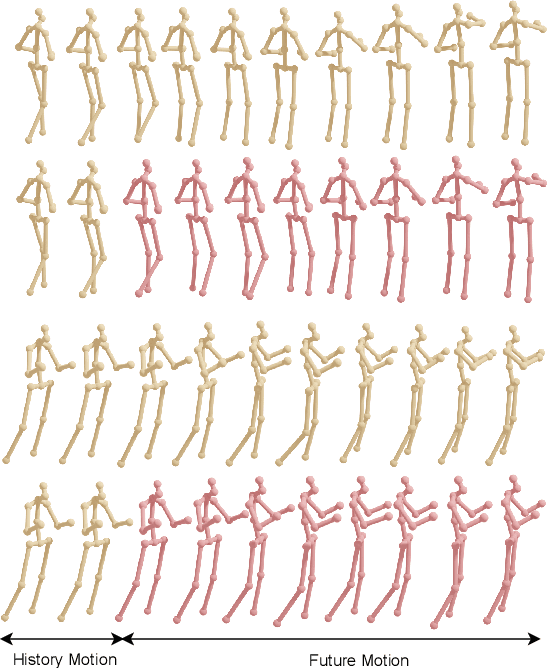

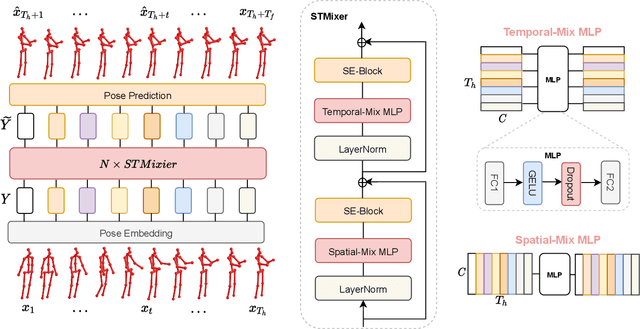
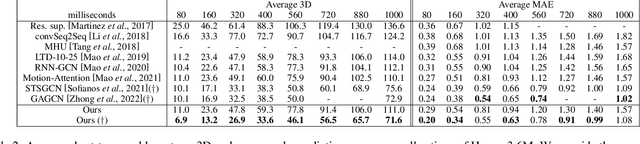
In this work, we present MotionMixer, an efficient 3D human body pose forecasting model based solely on multi-layer perceptrons (MLPs). MotionMixer learns the spatial-temporal 3D body pose dependencies by sequentially mixing both modalities. Given a stacked sequence of 3D body poses, a spatial-MLP extracts fine grained spatial dependencies of the body joints. The interaction of the body joints over time is then modelled by a temporal MLP. The spatial-temporal mixed features are finally aggregated and decoded to obtain the future motion. To calibrate the influence of each time step in the pose sequence, we make use of squeeze-and-excitation (SE) blocks. We evaluate our approach on Human3.6M, AMASS, and 3DPW datasets using the standard evaluation protocols. For all evaluations, we demonstrate state-of-the-art performance, while having a model with a smaller number of parameters. Our code is available at: https://github.com/MotionMLP/MotionMixer
A Spatio-Temporal Multilayer Perceptron for Gesture Recognition
Apr 25, 2022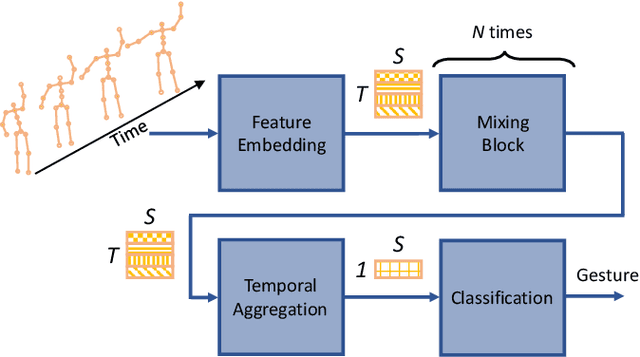
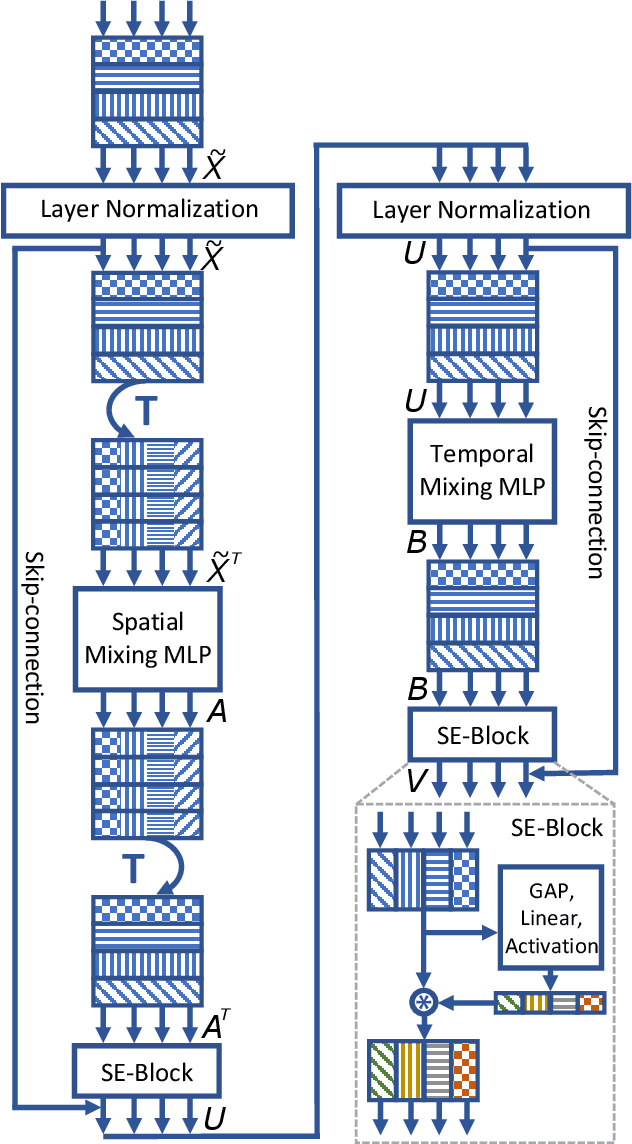
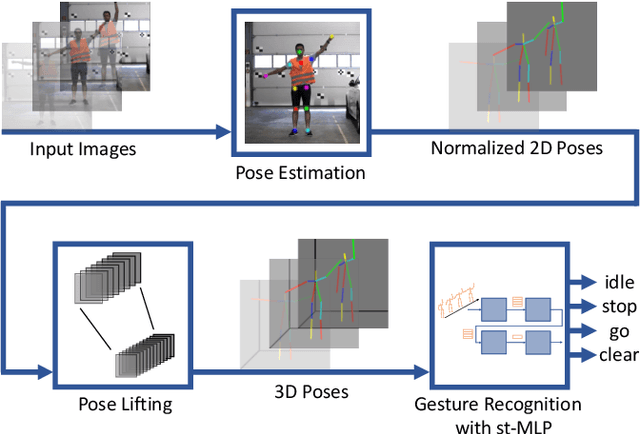
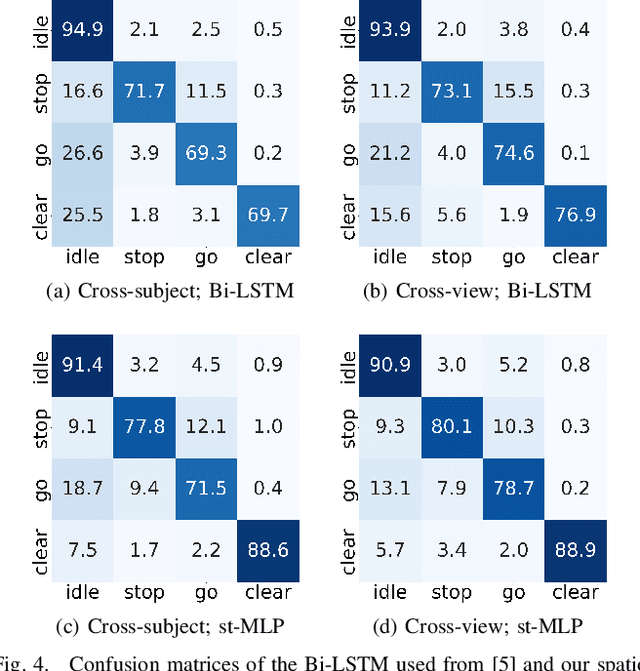
Gesture recognition is essential for the interaction of autonomous vehicles with humans. While the current approaches focus on combining several modalities like image features, keypoints and bone vectors, we present neural network architecture that delivers state-of-the-art results only with body skeleton input data. We propose the spatio-temporal multilayer perceptron for gesture recognition in the context of autonomous vehicles. Given 3D body poses over time, we define temporal and spatial mixing operations to extract features in both domains. Additionally, the importance of each time step is re-weighted with Squeeze-and-Excitation layers. An extensive evaluation of the TCG and Drive&Act datasets is provided to showcase the promising performance of our approach. Furthermore, we deploy our model to our autonomous vehicle to show its real-time capability and stable execution.