 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-conditioned Graph Diffusion for Neural Architecture Search
Mar 09, 2024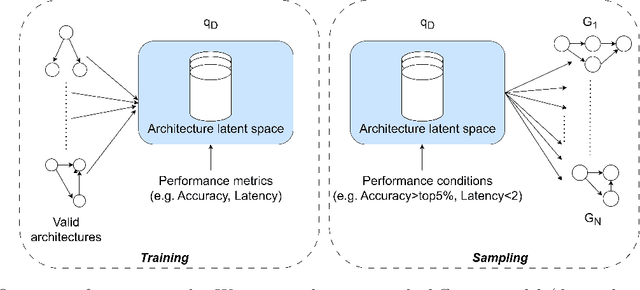
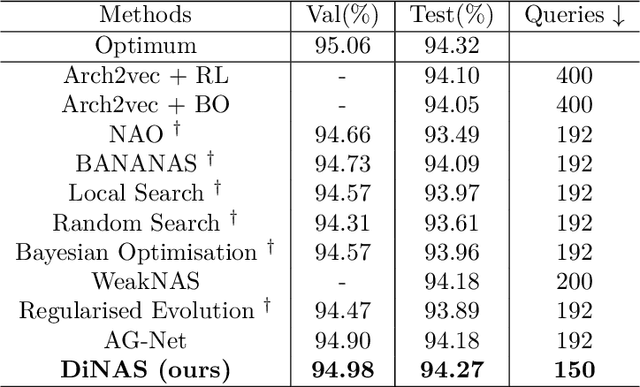
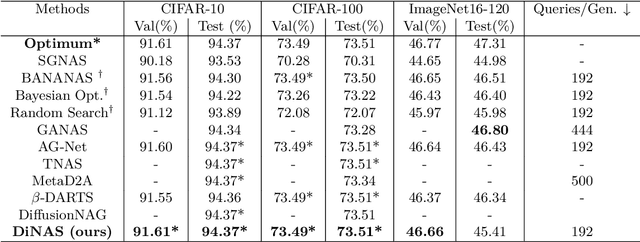
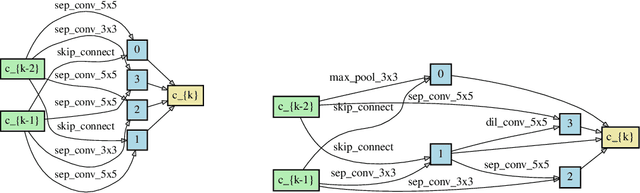
Neural architecture search automates the design of neural network architectures usually by exploring a large and thus complex architecture search space. To advance the architecture search, we present a graph diffusion-based NAS approach that uses discrete conditional graph diffusion processes to generate high-performing neural network architectures. We then propose a multi-conditioned classifier-free guidance approach applied to graph diffusion networks to jointly impose constraints such as high accuracy and low hardware latency. Unlike the related work, our method is completely differentiable and requires only a single model training. In our evaluations, we show promising results on six standard benchmarks, yielding novel and unique architectures at a fast speed, i.e. less than 0.2 seconds per architecture. Furthermore, we demonstrate the generalisability and efficiency of our method through experiments on ImageNet dataset.
SelectNAdapt: Support Set Selection for Few-Shot Domain Adaptation
Aug 09, 2023



Generalisation of deep neural networks becomes vulnerable when distribution shifts are encountered between train (source) and test (target) domain data. Few-shot domain adaptation mitigates this issue by adapting deep neural networks pre-trained on the source domain to the target domain using a randomly selected and annotated support set from the target domain. This paper argues that randomly selecting the support set can be further improved for effectively adapting the pre-trained source models to the target domain. Alternatively, we propose SelectNAdapt, an algorithm to curate the selection of the target domain samples, which are then annotated and included in the support set. In particular, for the K-shot adaptation problem, we first leverage self-supervision to learn features of the target domain data. Then, we propose a per-class clustering scheme of the learned target domain features and select K representative target samples using a distance-based scoring function. Finally, we bring our selection setup towards a practical ground by relying on pseudo-labels for clustering semantically similar target domain samples. Our experiments show promising results on three few-shot domain adaptation benchmarks for image recognition compared to related approaches and the standard random selection.
Knowing What to Label for Few Shot Microscopy Image Cell Segmentation
Nov 18, 2022


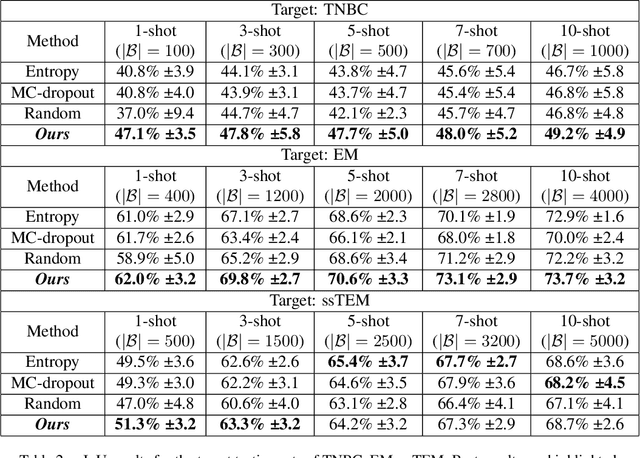
In microscopy image cell segmentation, it is common to train a deep neural network on source data, containing different types of microscopy images, and then fine-tune it using a support set comprising a few randomly selected and annotated training target images. In this paper, we argue that the random selection of unlabelled training target images to be annotated and included in the support set may not enable an effective fine-tuning process, so we propose a new approach to optimise this image selection process. Our approach involves a new scoring function to find informative unlabelled target images. In particular, we propose to measure the consistency in the model predictions on target images against specific data augmentations. However, we observe that the model trained with source datasets does not reliably evaluate consistency on target images. To alleviate this problem, we propose novel self-supervised pretext tasks to compute the scores of unlabelled target images. Finally, the top few images with the least consistency scores are added to the support set for oracle (i.e., expert) annotation and later used to fine-tune the model to the target images. In our evaluations that involve the segmentation of five different types of cell images, we demonstrate promising results on several target test sets compared to the random selection approach as well as other selection approaches, such as Shannon's entropy and Monte-Carlo dropout.
Edge-Based Self-Supervision for Semi-Supervised Few-Shot Microscopy Image Cell Segmentation
Aug 03, 2022
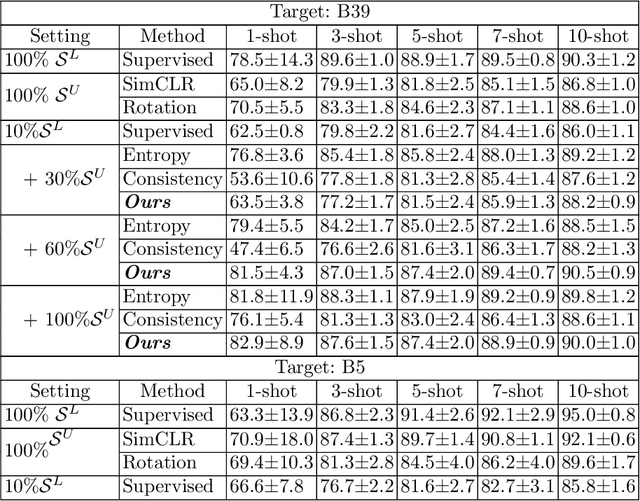

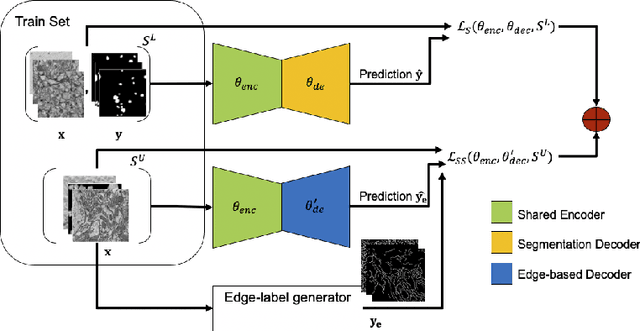
Deep neural networks currently deliver promising results for microscopy image cell segmentation, but they require large-scale labelled databases, which is a costly and time-consuming process. In this work, we relax the labelling requirement by combining self-supervised with semi-supervised learning. We propose the prediction of edge-based maps for self-supervising the training of the unlabelled images, which is combined with the supervised training of a small number of labelled images for learning the segmentation task. In our experiments, we evaluate on a few-shot microscopy image cell segmentation benchmark and show that only a small number of annotated images, e.g. 10% of the original training set, is enough for our approach to reach similar performance as with the fully annotated databases on 1- to 10-shots. Our code and trained models is made publicly available
A Spatio-Temporal Multilayer Perceptron for Gesture Recognition
Apr 25, 2022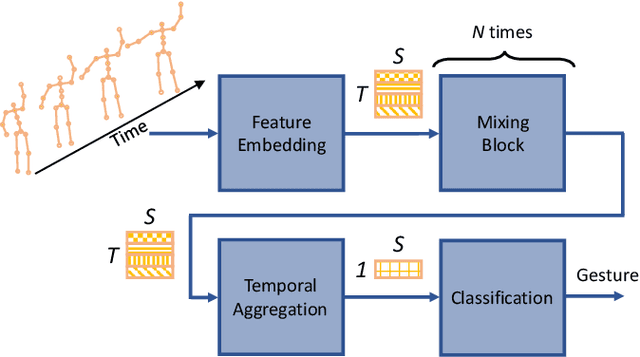
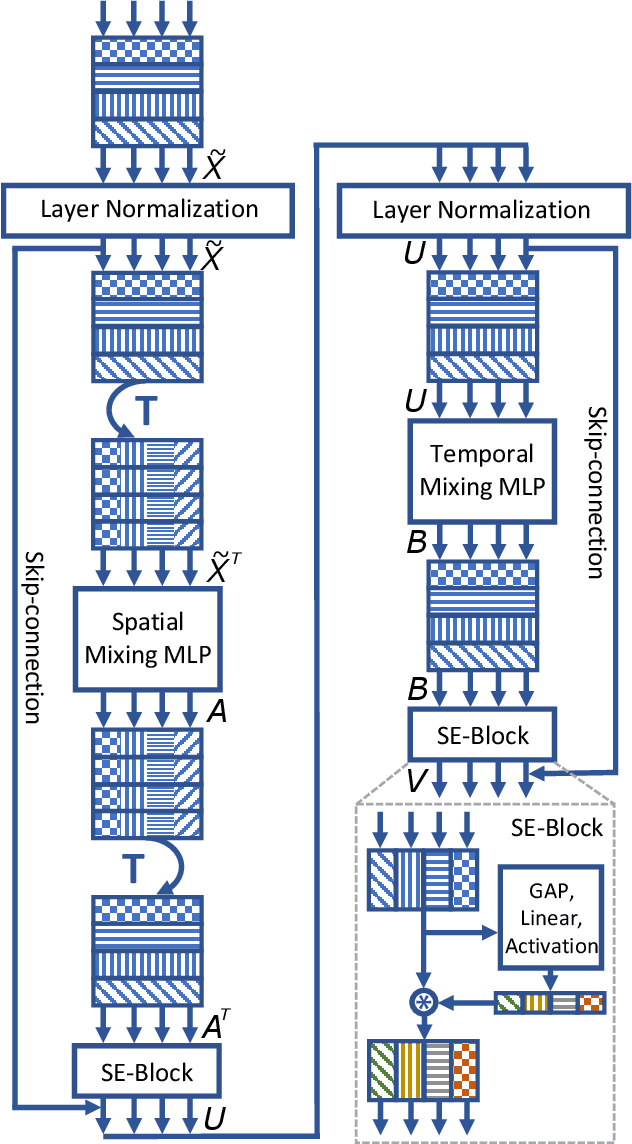
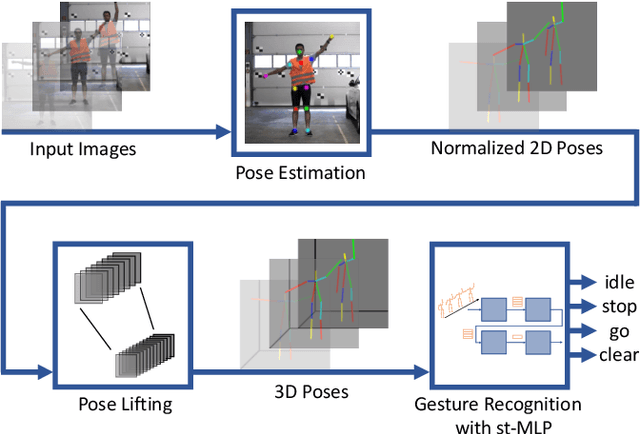
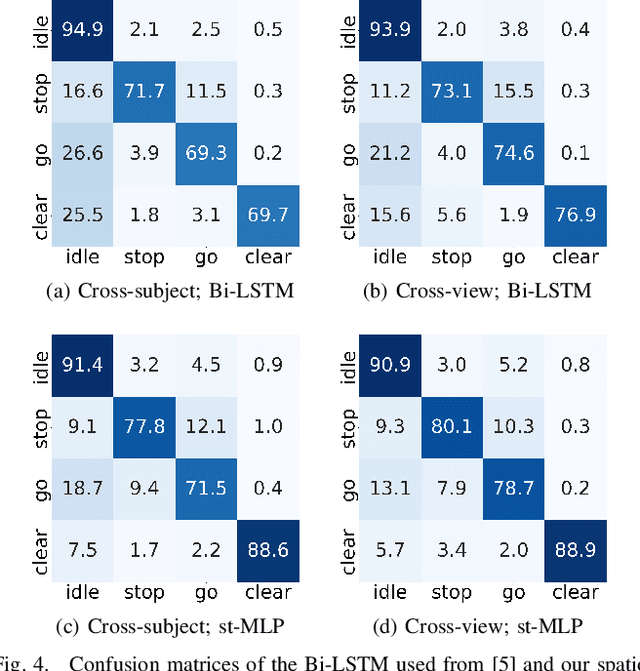
Gesture recognition is essential for the interaction of autonomous vehicles with humans. While the current approaches focus on combining several modalities like image features, keypoints and bone vectors, we present neural network architecture that delivers state-of-the-art results only with body skeleton input data. We propose the spatio-temporal multilayer perceptron for gesture recognition in the context of autonomous vehicles. Given 3D body poses over time, we define temporal and spatial mixing operations to extract features in both domains. Additionally, the importance of each time step is re-weighted with Squeeze-and-Excitation layers. An extensive evaluation of the TCG and Drive&Act datasets is provided to showcase the promising performance of our approach. Furthermore, we deploy our model to our autonomous vehicle to show its real-time capability and stable execution.
Lightweight Monocular Depth Estimation through Guided Decoding
Mar 08, 2022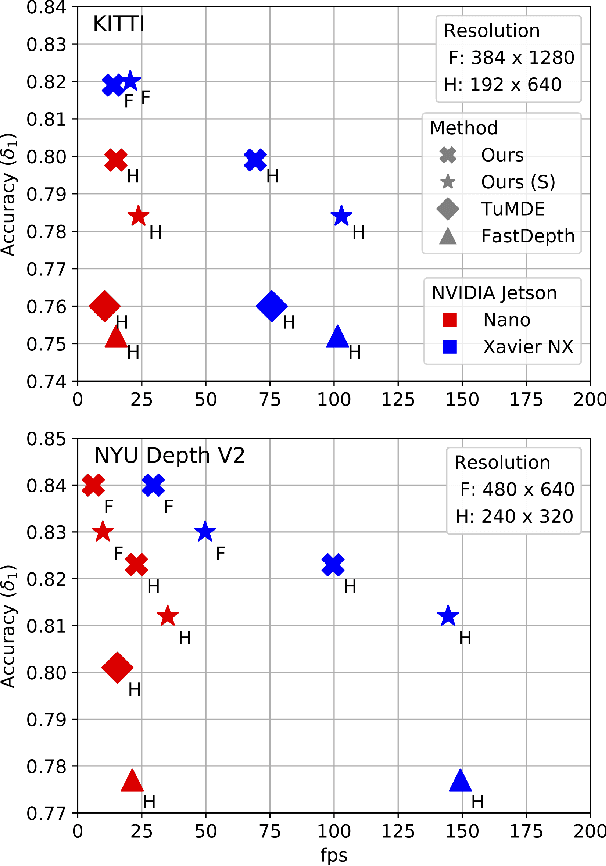
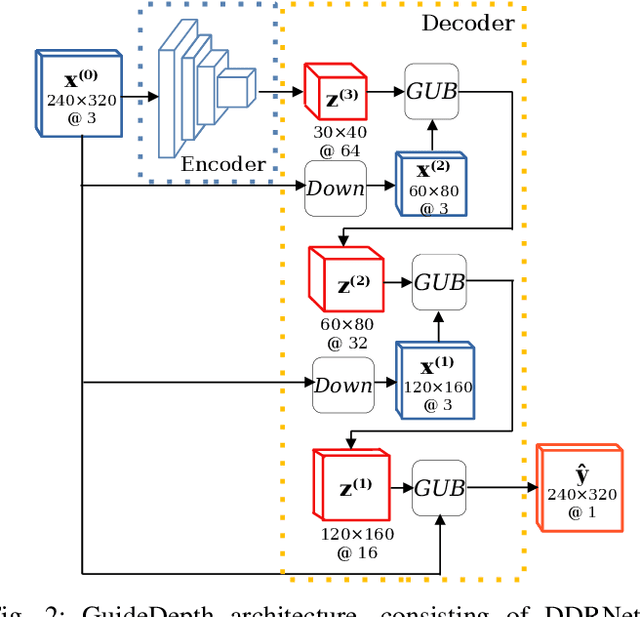


We present a lightweight encoder-decoder archi- tecture for monocular depth estimation, specifically designed for embedded platforms. Our main contribution is the Guided Upsampling Block (GUB) for building the decoder of our model. Motivated by the concept of guided image filtering, GUB relies on the image to guide the decoder on upsampling the feature representation and the depth map reconstruction, achieving high resolution results with fine-grained details. Based on multiple GUBs, our model outperforms the related methods on the NYU Depth V2 dataset in terms of accuracy while delivering up to 35.1 fps on the NVIDIA Jetson Nano and up to 144.5 fps on the NVIDIA Xavier NX. Similarly, on the KITTI dataset, inference is possible with up to 23.7 fps on the Jetson Nano and 102.9 fps on the Xavier NX. Our code and models are made publicly available.
Few-Shot Microscopy Image Cell Segmentation
Jun 29, 2020


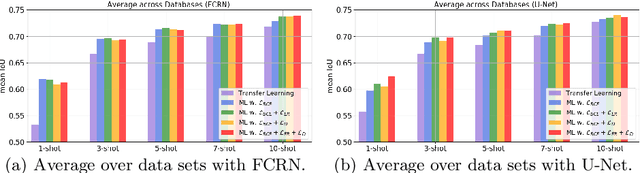
Automatic cell segmentation in microscopy images works well with the support of deep neural networks trained with full supervision. Collecting and annotating images, though, is not a sustainable solution for every new microscopy database and cell type. Instead, we assume that we can access a plethora of annotated image data sets from different domains (sources) and a limited number of annotated image data sets from the domain of interest (target), where each domain denotes not only different image appearance but also a different type of cell segmentation problem. We pose this problem as meta-learning where the goal is to learn a generic and adaptable few-shot learning model from the available source domain data sets and cell segmentation tasks. The model can be afterwards fine-tuned on the few annotated images of the target domain that contains different image appearance and different cell type. In our meta-learning training, we propose the combination of three objective functions to segment the cells, move the segmentation results away from the classification boundary using cross-domain tasks, and learn an invariant representation between tasks of the source domains. Our experiments on five public databases show promising results from 1- to 10-shot meta-learning using standard segmentation neural network architectures.