 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere to Attend: A Principled Vision-Centric Position Encoding with Parabolas
Feb 01, 2026We propose Parabolic Position Encoding (PaPE), a parabola-based position encoding for vision modalities in attention-based architectures. Given a set of vision tokens-such as images, point clouds, videos, or event camera streams-our objective is to encode their positions while accounting for the characteristics of vision modalities. Prior works have largely extended position encodings from 1D-sequences in language to nD-structures in vision, but only with partial account of vision characteristics. We address this gap by designing PaPE from principles distilled from prior work: translation invariance, rotation invariance (PaPE-RI), distance decay, directionality, and context awareness. We evaluate PaPE on 8 datasets that span 4 modalities. We find that either PaPE or PaPE-RI achieves the top performance on 7 out of 8 datasets. Extrapolation experiments on ImageNet-1K show that PaPE extrapolates remarkably well, improving in absolute terms by up to 10.5% over the next-best position encoding. Code is available at https://github.com/DTU-PAS/parabolic-position-encoding.
Spiking Patches: Asynchronous, Sparse, and Efficient Tokens for Event Cameras
Oct 30, 2025We propose tokenization of events and present a tokenizer, Spiking Patches, specifically designed for event cameras. Given a stream of asynchronous and spatially sparse events, our goal is to discover an event representation that preserves these properties. Prior works have represented events as frames or as voxels. However, while these representations yield high accuracy, both frames and voxels are synchronous and decrease the spatial sparsity. Spiking Patches gives the means to preserve the unique properties of event cameras and we show in our experiments that this comes without sacrificing accuracy. We evaluate our tokenizer using a GNN, PCN, and a Transformer on gesture recognition and object detection. Tokens from Spiking Patches yield inference times that are up to 3.4x faster than voxel-based tokens and up to 10.4x faster than frames. We achieve this while matching their accuracy and even surpassing in some cases with absolute improvements up to 3.8 for gesture recognition and up to 1.4 for object detection. Thus, tokenization constitutes a novel direction in event-based vision and marks a step towards methods that preserve the properties of event cameras.
ClustViT: Clustering-based Token Merging for Semantic Segmentation
Oct 02, 2025Vision Transformers can achieve high accuracy and strong generalization across various contexts, but their practical applicability on real-world robotic systems is limited due to their quadratic attention complexity. Recent works have focused on dynamically merging tokens according to the image complexity. Token merging works well for classification but is less suited to dense prediction. We propose ClustViT, where we expand upon the Vision Transformer (ViT) backbone and address semantic segmentation. Within our architecture, a trainable Cluster module merges similar tokens along the network guided by pseudo-clusters from segmentation masks. Subsequently, a Regenerator module restores fine details for downstream heads. Our approach achieves up to 2.18x fewer GFLOPs and 1.64x faster inference on three different datasets, with comparable segmentation accuracy. Our code and models will be made publicly available.
A Survey on Dynamic Neural Networks: from Computer Vision to Multi-modal Sensor Fusion
Jan 13, 2025Model compression is essential in the deployment of large Computer Vision models on embedded devices. However, static optimization techniques (e.g. pruning, quantization, etc.) neglect the fact that different inputs have different complexities, thus requiring different amount of computations. Dynamic Neural Networks allow to condition the number of computations to the specific input. The current literature on the topic is very extensive and fragmented. We present a comprehensive survey that synthesizes and unifies existing Dynamic Neural Networks research in the context of Computer Vision. Additionally, we provide a logical taxonomy based on which component of the network is adaptive: the output, the computation graph or the input. Furthermore, we argue that Dynamic Neural Networks are particularly beneficial in the context of Sensor Fusion for better adaptivity, noise reduction and information prioritization. We present preliminary works in this direction.
From Web Data to Real Fields: Low-Cost Unsupervised Domain Adaptation for Agricultural Robots
Oct 31, 2024In precision agriculture, vision models often struggle with new, unseen fields where crops and weeds have been influenced by external factors, resulting in compositions and appearances that differ from the learned distribution. This paper aims to adapt to specific fields at low cost using Unsupervised Domain Adaptation (UDA). We explore a novel domain shift from a diverse, large pool of internet-sourced data to a small set of data collected by a robot at specific locations, minimizing the need for extensive on-field data collection. Additionally, we introduce a novel module -- the Multi-level Attention-based Adversarial Discriminator (MAAD) -- which can be integrated at the feature extractor level of any detection model. In this study, we incorporate MAAD with CenterNet to simultaneously detect leaf, stem, and vein instances. Our results show significant performance improvements in the unlabeled target domain compared to baseline models, with a 7.5% increase in object detection accuracy and a 5.1% improvement in keypoint detection.
Vision-based robot manipulation of transparent liquid containers in a laboratory setting
Apr 25, 2024Laboratory processes involving small volumes of solutions and active ingredients are often performed manually due to challenges in automation, such as high initial costs, semi-structured environments and protocol variability. In this work, we develop a flexible and cost-effective approach to address this gap by introducing a vision-based system for liquid volume estimation and a simulation-driven pouring method particularly designed for containers with small openings. We evaluate both components individually, followed by an applied real-world integration of cell culture automation using a UR5 robotic arm. Our work is fully reproducible: we share our code at at \url{https://github.com/DaniSchober/LabLiquidVision} and the newly introduced dataset LabLiquidVolume is available at https://data.dtu.dk/articles/dataset/LabLiquidVision/25103102.
Zoom in on the Plant: Fine-grained Analysis of Leaf, Stem and Vein Instances
Dec 14, 2023



Robot perception is far from what humans are capable of. Humans do not only have a complex semantic scene understanding but also extract fine-grained intra-object properties for the salient ones. When humans look at plants, they naturally perceive the plant architecture with its individual leaves and branching system. In this work, we want to advance the granularity in plant understanding for agricultural precision robots. We develop a model to extract fine-grained phenotypic information, such as leaf-, stem-, and vein instances. The underlying dataset RumexLeaves is made publicly available and is the first of its kind with keypoint-guided polyline annotations leading along the line from the lowest stem point along the leaf basal to the leaf apex. Furthermore, we introduce an adapted metric POKS complying with the concept of keypoint-guided polylines. In our experimental evaluation, we provide baseline results for our newly introduced dataset while showcasing the benefits of POKS over OKS.
Lightweight Monocular Depth Estimation through Guided Decoding
Mar 08, 2022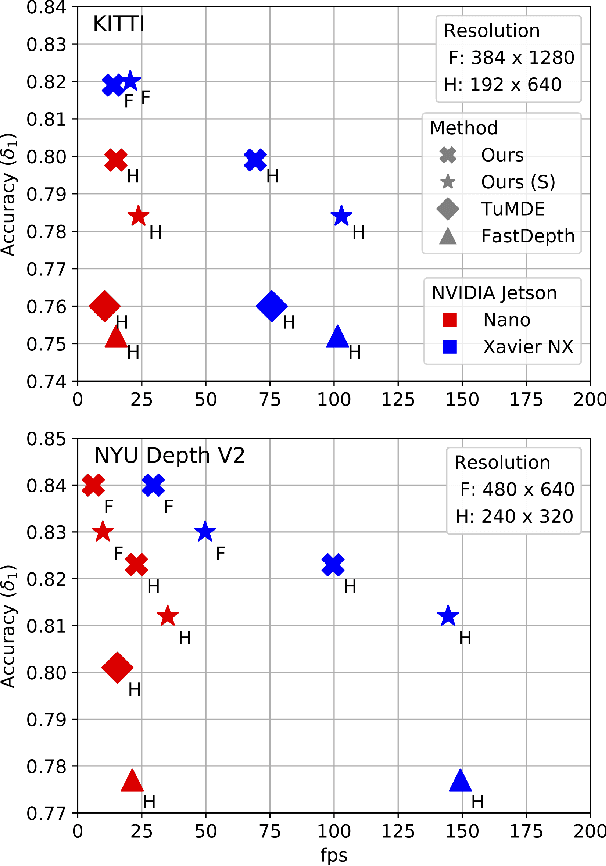
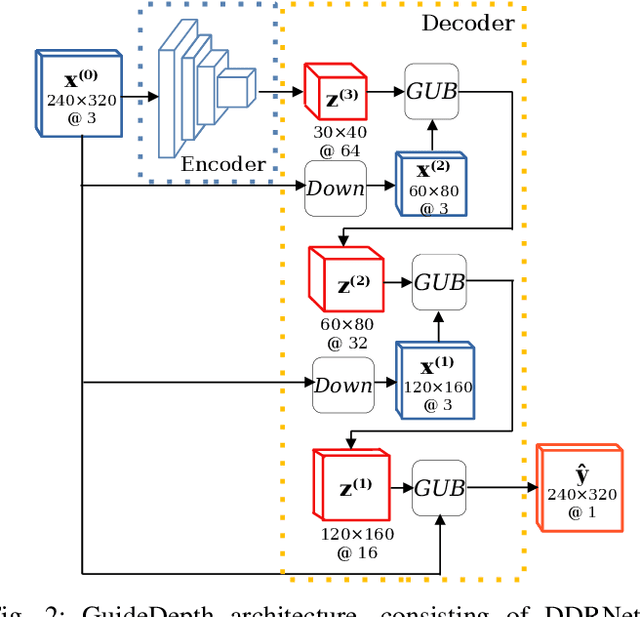


We present a lightweight encoder-decoder archi- tecture for monocular depth estimation, specifically designed for embedded platforms. Our main contribution is the Guided Upsampling Block (GUB) for building the decoder of our model. Motivated by the concept of guided image filtering, GUB relies on the image to guide the decoder on upsampling the feature representation and the depth map reconstruction, achieving high resolution results with fine-grained details. Based on multiple GUBs, our model outperforms the related methods on the NYU Depth V2 dataset in terms of accuracy while delivering up to 35.1 fps on the NVIDIA Jetson Nano and up to 144.5 fps on the NVIDIA Xavier NX. Similarly, on the KITTI dataset, inference is possible with up to 23.7 fps on the Jetson Nano and 102.9 fps on the Xavier NX. Our code and models are made publicly available.