 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedestrian Environment Model for Automated Driving
Aug 17, 2023Besides interacting correctly with other vehicles, automated vehicles should also be able to react in a safe manner to vulnerable road users like pedestrians or cyclists. For a safe interaction between pedestrians and automated vehicles, the vehicle must be able to interpret the pedestrian's behavior. Common environment models do not contain information like body poses used to understand the pedestrian's intent. In this work, we propose an environment model that includes the position of the pedestrians as well as their pose information. We only use images from a monocular camera and the vehicle's localization data as input to our pedestrian environment model. We extract the skeletal information with a neural network human pose estimator from the image. Furthermore, we track the skeletons with a simple tracking algorithm based on the Hungarian algorithm and an ego-motion compensation. To obtain the 3D information of the position, we aggregate the data from consecutive frames in conjunction with the vehicle position. We demonstrate our pedestrian environment model on data generated with the CARLA simulator and the nuScenes dataset. Overall, we reach a relative position error of around 16% on both datasets.
Automated Automotive Radar Calibration With Intelligent Vehicles
Jun 23, 2023



While automotive radar sensors are widely adopted and have been used for automatic cruise control and collision avoidance tasks, their application outside of vehicles is still limited. As they have the ability to resolve multiple targets in 3D space, radars can also be used for improving environment perception. This application, however, requires a precise calibration, which is usually a time-consuming and labor-intensive task. We, therefore, present an approach for automated and geo-referenced extrinsic calibration of automotive radar sensors that is based on a novel hypothesis filtering scheme. Our method does not require external modifications of a vehicle and instead uses the location data obtained from automated vehicles. This location data is then combined with filtered sensor data to create calibration hypotheses. Subsequent filtering and optimization recovers the correct calibration. Our evaluation on data from a real testing site shows that our method can correctly calibrate infrastructure sensors in an automated manner, thus enabling cooperative driving scenarios.
Automated Static Camera Calibration with Intelligent Vehicles
Apr 21, 2023Connected and cooperative driving requires precise calibration of the roadside infrastructure for having a reliable perception system. To solve this requirement in an automated manner, we present a robust extrinsic calibration method for automated geo-referenced camera calibration. Our method requires a calibration vehicle equipped with a combined GNSS/RTK receiver and an inertial measurement unit (IMU) for self-localization. In order to remove any requirements for the target's appearance and the local traffic conditions, we propose a novel approach using hypothesis filtering. Our method does not require any human interaction with the information recorded by both the infrastructure and the vehicle. Furthermore, we do not limit road access for other road users during calibration. We demonstrate the feasibility and accuracy of our approach by evaluating our approach on synthetic datasets as well as a real-world connected intersection, and deploying the calibration on real infrastructure. Our source code is publicly available.
Extrinsic Camera Calibration with Semantic Segmentation
Aug 08, 2022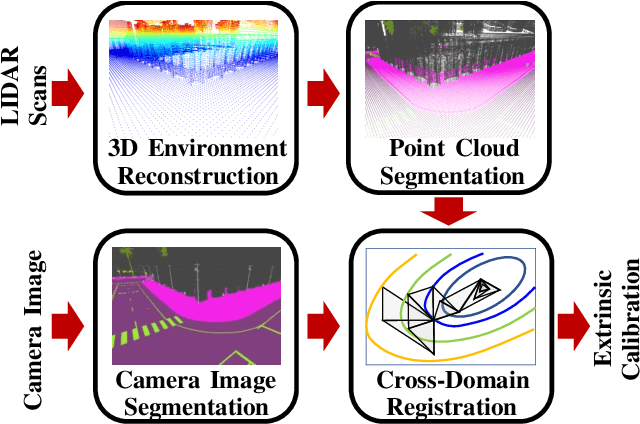
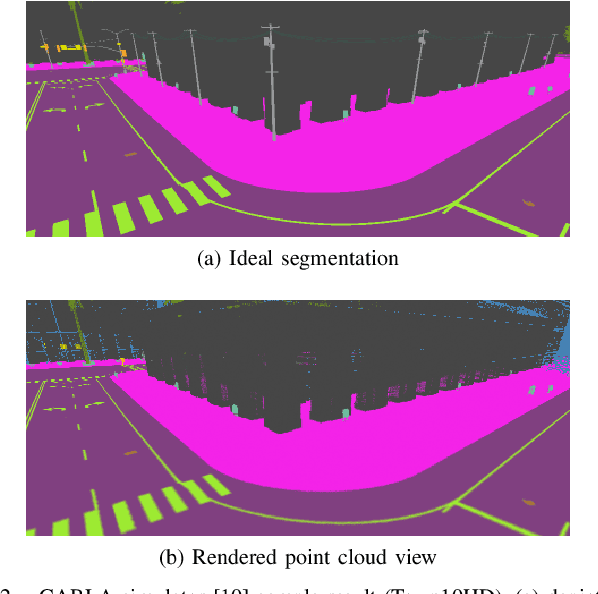

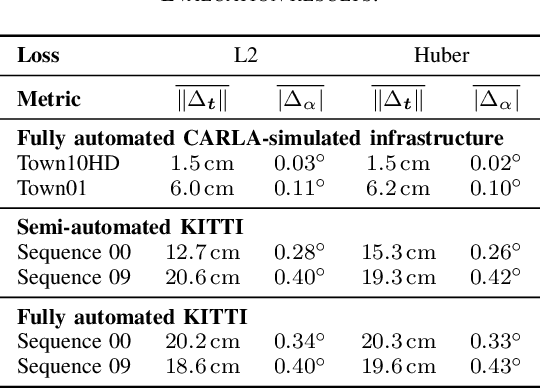
Monocular camera sensors are vital to intelligent vehicle operation and automated driving assistance and are also heavily employed in traffic control infrastructure. Calibrating the monocular camera, though, is time-consuming and often requires significant manual intervention. In this work, we present an extrinsic camera calibration approach that automatizes the parameter estimation by utilizing semantic segmentation information from images and point clouds. Our approach relies on a coarse initial measurement of the camera pose and builds on lidar sensors mounted on a vehicle with high-precision localization to capture a point cloud of the camera environment. Afterward, a mapping between the camera and world coordinate spaces is obtained by performing a lidar-to-camera registration of the semantically segmented sensor data. We evaluate our method on simulated and real-world data to demonstrate low error measurements in the calibration results. Our approach is suitable for infrastructure sensors as well as vehicle sensors, while it does not require motion of the camera platform.
A Spatio-Temporal Multilayer Perceptron for Gesture Recognition
Apr 25, 2022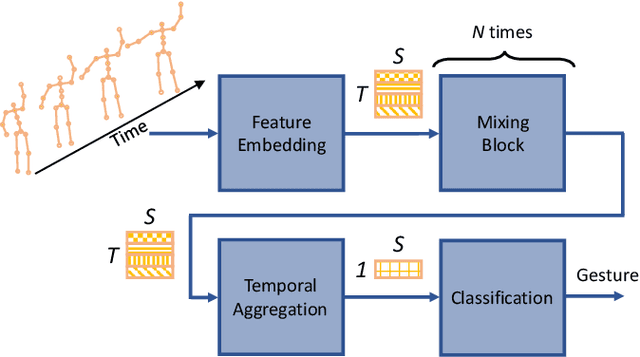
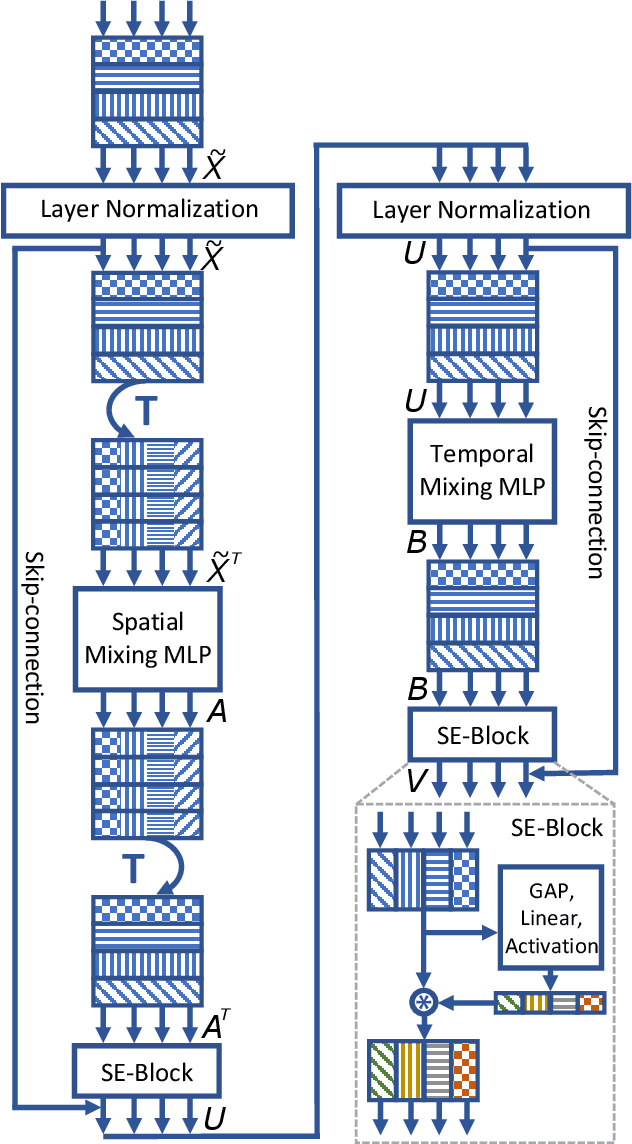
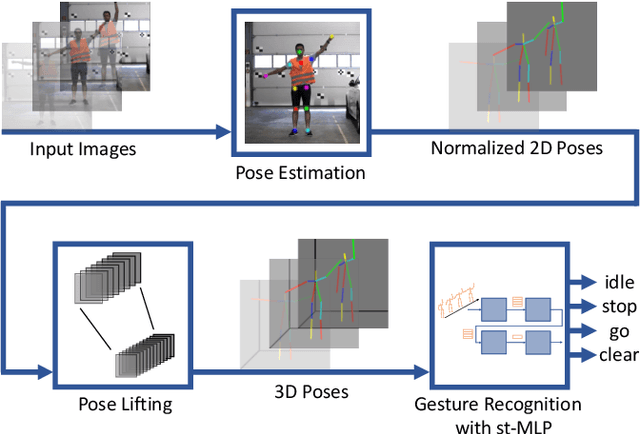
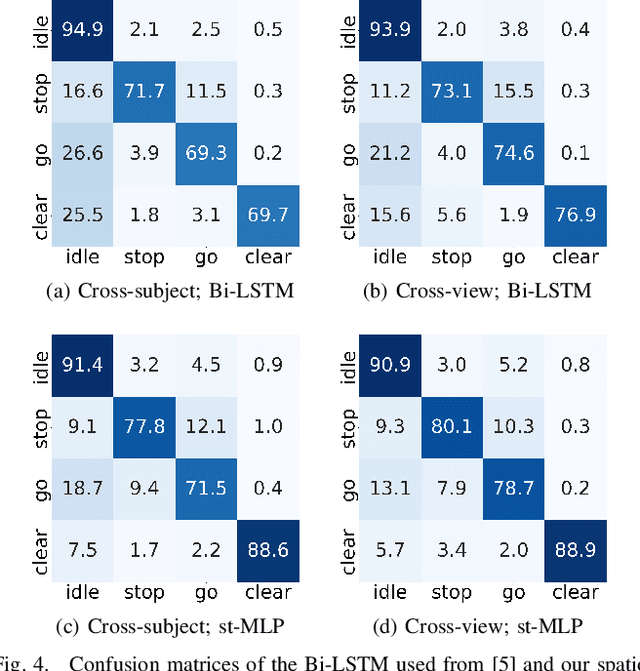
Gesture recognition is essential for the interaction of autonomous vehicles with humans. While the current approaches focus on combining several modalities like image features, keypoints and bone vectors, we present neural network architecture that delivers state-of-the-art results only with body skeleton input data. We propose the spatio-temporal multilayer perceptron for gesture recognition in the context of autonomous vehicles. Given 3D body poses over time, we define temporal and spatial mixing operations to extract features in both domains. Additionally, the importance of each time step is re-weighted with Squeeze-and-Excitation layers. An extensive evaluation of the TCG and Drive&Act datasets is provided to showcase the promising performance of our approach. Furthermore, we deploy our model to our autonomous vehicle to show its real-time capability and stable execution.
ParticleAugment: Sampling-Based Data Augmentation
Jun 16, 2021


We present an automated data augmentation approach for image classification. We formulate the problem as Monte Carlo sampling where our goal is to approximate the optimal augmentation policies. We propose a particle filtering formulation to find optimal augmentation policies and their schedules during model training. Our performance measurement procedure relies on a validation subset of our training set, while the policy transition model depends on a Gaussian prior and an optional augmentation velocity parameter. In our experiments, we show that our formulation for automated augmentation reaches promising results on CIFAR-10, CIFAR-100, and ImageNet datasets using the standard network architectures for this problem. By comparing with the related work, we also show that our method reaches a balance between the computational cost of policy search and the model performance.